转自:
https://www.cnblogs.com/DjangoBlog/p/6889421.html
https://blog.csdn.net/aiwuzhi12/article/details/54707695
现有分词介绍
分词方法大致分为两种:
- 基于词典的机械切分
- 基于统计模型的序列标注切分
1. 基于词典的机械划分
1.1 基于词典的机械划分
基于词典的方法本质上就是字符串匹配的方法,将一串文本中的文字片段和已有的词典进行匹配,如果匹配到,则此文字片段就作为一个分词结果。
但是基于词典的机械切分会遇到多种问题,最为常见的包括歧义切分问题和未登录词问题。
- 歧义切分问题
比如下面的例子:“结婚的和尚未结婚的人”,通过机械切分的方式,会有两种切分结果:1,“结婚/的/和/尚未/结婚/的/人”;2,“结婚/的/和尚/未/结婚/的/人”。可以明显看出,第二种切分是有歧义的,单纯的机械切分很难避免这样的问题。 - 未登录词问题
未登录词识别也称作新词发现,指的是词没有在词典中出现,比如一些新的网络词汇,如“网红”,“走你”;一些未登录的人名,地名;一些外语音译过来的词等等。基于词典的方式较难解决未登录词的问题,简单的case可以通过加词典解决,但是随着字典的增大,可能会引入新的bad case,并且系统的运算复杂度也会增加。
1.2 基于词典的机械分词改进方法
为了解决歧义切分的问题,在中文分词上有很多优化的方法,常见的包括最大匹配方法(包括正向最大匹配,逆向最大匹配),最少分词结果,全切分后选择路径等多种算法。
- 最大匹配法/MM方法(The Maximum Matching Method)
正向最大匹配指的是从左到右对一个字符串进行匹配,所匹配的词越长越好,比如“中国科学院计算研究所”,按照词典中最长匹配原则的切分结果是:“中国科学院/计算研究所”,而不是“中国/科学院/计算/研究所”。
但是正向最大匹配也会存在一些bad case,常见的例子如:“他从东经过我家”,使用正向最大匹配会得到错误的结果:“他/从/东经/过/我/家”。
逆向最大匹配的顺序是从右向左倒着匹配,如果能匹配到更长的词,则优先选择,上面的例子“他从东经过我家”逆向最大匹配能够得到正确的结果“他/从/东/经过/我/家”。
但是逆向最大匹配同样存在badcase:“他们昨日本应该回来”,逆向匹配会得到错误的结果“他们/昨/日本/应该/回来”。 - 最少分词结果
针对正向逆向匹配的问题,将双向切分的结果进行比较,选择切分词语数量最少的结果。
但是最少切分结果同样有bad case,比如“他将来上海”,正确的切分结果是“他/将/来/上海”,有4个词,而最少切分结果“他/将来/上海”只有3个词。 - 全切分后选择路径
全切分方法就是将所有可能的切分组合全部列出来,并从中选择最佳的一条切分路径。关于路径的选择方式,一般有n最短路径方法,基于词的n元语法模型方法等。
n最短路径方法的基本思想就是将所有的切分结果组成有向无环图,每个切词结果作为一个节点,词之间的边赋予一个权重,最终找到权重和最小的一条路径作为分词结果。
基于词的n元语法模型可以看作是n最短路径方法的一种优化,不同的是,根据n元语法模型,路径构成时会考虑词的上下文关系,根据语料库的统计结果,找出构成句子最大模型概率。一般情况下,使用unigram和bigram的n元语法模型的情况较多。
2. 基于统计模型的序列标注切分
针对基于词典的机械切分所面对的问题,尤其是未登录词识别,使用基于统计模型的分词方式能够取得更好的效果。
基于统计模型的分词方法,简单来讲就是一个序列标注问题。
在一段文字中,我们可以将每个字按照他们在词中的位置进行标注,常用的标记有以下四个label:B,Begin,表示这个字是一个词的首字;M,Middle,表示这是一个词中间的字;E,End,表示这是一个词的尾字;S,Single,表示这是单字成词。
分词的过程就是将一段字符输入模型,然后得到相应的标记序列,再根据标记序列进行分词。
举例来说:“达观数据位是企业大数据服务商”,经过模型后得到的理想标注序列是:“BMMESBEBMEBME”,最终还原的分词结果是“达观数据/是/企业/大数据/服务商”。
在NLP领域中,解决序列标注问题的常见模型主要有HMM和CRF。
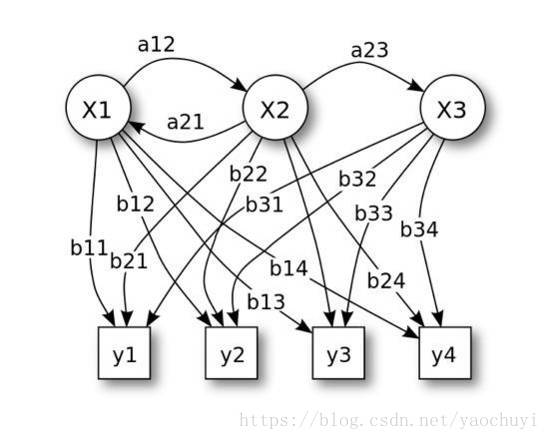
2.1 HMM
HMM(HiddenMarkov Model)隐马尔科夫模型应用非常广泛,基本的思想就是根据观测值序列找到真正的隐藏状态值序列。
在中文分词中,一段文字的每个字符可以看作是一个观测值,而这个字符的词位置label(BEMS)可以看作是隐藏的状态。使用HMM的分词,通过对切分语料库进行统计,可以得到模型中5大要要素:
- 起始概率矩阵
- 转移概率矩阵
- 发射概率矩阵
- 观察值集合
- 状态值集合
在概率矩阵中,起始概率矩阵表示序列第一个状态值的概率,在中文分词中,理论上M和E的概率为0。转移概率表示状态间的概率,比如B->M的概率,E->S的概率等。而发射概率是一个条件概率,表示当前这个状态下,出现某个字的概率,比如p(人|B)表示在状态为B的情况下人字的概率。
有了三个矩阵和两个集合后,HMM问题最终转化成求解隐藏状态序列最大值的问题,求解这个问题最长使用的是Viterbi算法,这是一种动态规划算法,具体的算法可以参考维基百科词条,在此不详细展开。(https://en.wikipedia.org/wiki/Viterbi_algorithm)
(HMM模型示意图)
2.2 CRF
CRF(Conditional random field,条件随机场)是用来标注和划分结构数据的概率化结构模型,通常使用在模式识别和机器学习中,在自然语言处理和图像处理等领域中得到广泛应用。和HMM类似,当对于给定的输入观测序列X和输出序列Y,CRF通过定义条件概率P(Y|X),而不是联合概率分布P(X,Y)来描述模型。CRF算法的具体算法可以参考维基百科词条。(https://en.wikipedia.org/wiki/Conditional_random_field)
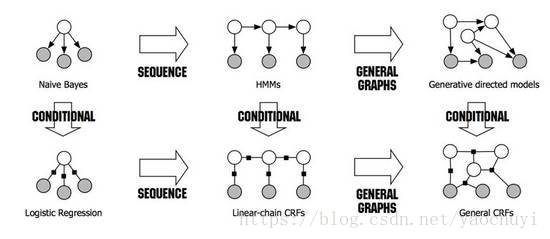
(不同概率模型之间的关系及演化图)
以下是思维导图的形式展示两大区别:

图片来自:https://blog.csdn.net/sinat_26917383/article/details/52275328
字标注本质上是训练出一个字的分类器。模型框架如下:
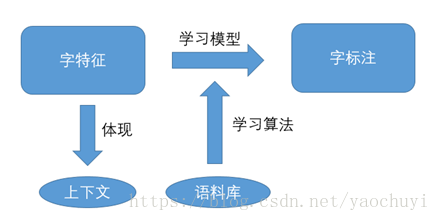
(字标注训练模型框架)
学习算法是指监督机器学习算法,常用的有:
- 最大熵算法、
- 条件随机场(CRF, Conditional Random Fields)、
- 支持向量机(SVM, Support Vector Machine)、
- 平均感知机(AP, Averaged Perceptron) 等。
基于字标注的分词方法是基于统计的。
其主要的优势在于能够平衡地看待词表词和未登录词的识别问题。
其缺点是学习算法的复杂度往往较高,计算代价较大,好在现在的计算机的计算能力相较于以前有很大提升;同时,该方法依赖训练语料库,领域自适应较差。基于字标注的分词方法是目前的主流分词方法。
3. 统计与字典相结合
张梅山等人在《统计与字典相结合的领域自适应中文分词》提出通过在统计中文分词模型中融入词典相关特征的方法,使得统计中文分词模型和词典有机结合起来。一方面可以进一步提高中文分词的准确率,另一方面大大改善了中文分词的领域自适应性。
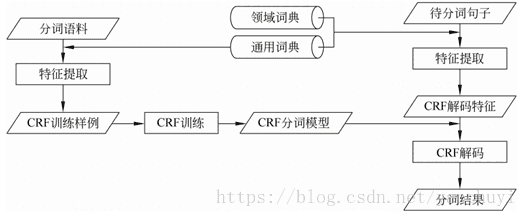
(领域自适应性分词系统框架图)
4. 基于深度学习的分词方法
深度学习介绍
随着AlphaGo的大显神威,Deep Learning(深度学习)的热度进一步提高。深度学习来源于传统的神经网络模型。传统的神经网络一般由输入层,隐藏层,输出层组成,其中隐藏层的数目按需确定。深度学习可以简单的理解为多层神经网络,但是深度学习的却不仅仅是神经网络。深度模型将每一层的输出作为下一层的输入特征,通过将底层的简单特征组合成为高层的更抽象的特征来进行学习。在训练过程中,通常采用贪婪算法,一层层的训练,比如在训练第k层时,固定训练好的前k-1层的参数进行训练,训练好第k层之后的以此类推进行一层层训练。
深度学习在很多领域都有所应用,在图像和语音识别领域中已经取得巨大的成功。
深度学习主要有两点优势:
- 深度学习可以通过优化最终目标,有效学习原子特征和上下文的表示;
- 基于深层网络如 CNN、 RNN、 LSTM等,深度学习可以更有效的刻画长距离句子信息。
在自然语言处理上,深度学习在机器翻译、自动问答、文本分类、情感分析、信息抽取、序列标注、语法解析等领域都有广泛的应用。2013年末google发布的word2vec工具,可以看做是深度学习在NLP领域的一个重要应用,虽然word2vec只有三层神经网络,但是已经取得非常好的效果。通过word2vec,可以将一个词表示为词向量,将文字数字化,更好的让计算机理解。使word2vec模型,我们可以方便的找到同义词或联系紧密的词,或者意义相反的词等。
词向量
词向量的意思就是通过一个数字组成的向量来表示一个词,这个向量的构成可以有很多种。最简单的方式就是所谓的one-hot向量。假设在一个语料集合中,一共有n个不同的词,则可以使用一个长度为n的向量,对于第i个词(i=0…n-1),向量 index=i 处值为1外,向量其他位置的值都为0,这样就可以唯一的通过一个[0,0,1,…,0,0]形式的向量表示一个词。one-hot向量比较简单也容易理解,但是有很多问题,比如:
1. 当加入新词时,整个向量的长度会改变;
2. 维数过高难以计算;
3. 向量的表示方法很难体现两个词之间的关系。
因此一般情况下one-hot向量较少的使用。
如果考虑到词和词之间的联系,就要考虑词的共现问题。最简单的是使用基于文档的向量表示方法来给出词向量。基本思想也很简单,假设有n篇文档,如果某些词经常成对出现在多篇相同的文档中,我们则认为这两个词联系非常紧密。
对于文档集合,可以将文档按顺编号(i=0…n-1),将文档编导作为向量索引,这样就有一个n维的向量。当一个词出现在某个文档i中时,向量i处值为1,这样就可以通过一个类似 [0,1,0,…,1,0] 形式的向量表示一个词。
基于文档的词向量能够很好的表示词之间的关系,但是向量的长度和语料库的大小相关,同样会存在维度变化问题。
考虑一个固定窗口大小的文本片段来解决维度变化问题,如果在这样的片段中,两个词出现了,就认为这两个词有关。举例来讲,有以下三句话: “我\喜欢\你”,“我\爱\运动”,“我\爱\摄影”,如果考虑窗口的大小为1,也就是认为一个词只和它前面和后面的词有关,通过统计共现次数,我们能够得到下面的矩阵:
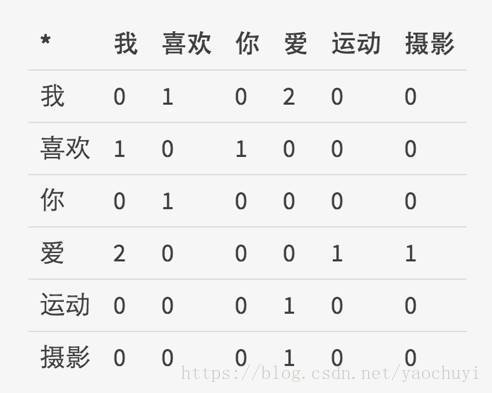
(基于文本窗口共现统计出来的矩阵)
可以看到这是一个n*n的对称矩阵X,这个矩阵的维数会随着词典数量的增加而增大,通过SVD(Singular Value Decomposition,奇异值分解),我们可以将矩阵维度降低,但仍存在一些问题: 矩阵X维度经常改变,并且由于大部分词并不是共现而导致的稀疏性,矩阵维度过高计算复杂度高等问题。
(1) word2vec词向量
Word2vec是一个三层的神经网络,同样可以将词向量化。虽然word2vec只有三层神经网络,但是已经取得非常好的效果。通过word2vec,可以将一个词表示为词向量,将文字数字化,更好的让计算机理解。使word2vec模型,我们可以方便的找到同义词或联系紧密的词,或者意义相反的词等。
在Word2vec中最重要的两个模型是CBOW(Continuous Bag-of-Word)模型和Skip-gram(Continuous Skip-gram)模型,两个模型都包含三层: 输入层,投影层,输出层。
CBOW模型的作用是已知当前词Wt的上下文环境(Wt-2,Wt-1,Wt+1,Wt+2)来预测当前词,Skip-gram模型的作用是根据当前词Wt来预测上下文(Wt-2,Wt-1,Wt+1,Wt+2)。
在模型求解中,和一般的机器学习方法类似,也是定义不同的损失函数,使用梯度下降法寻找最优值。Word2vec模型求解中,使用了Hierarchical Softmax方法和NegativeSampling两种方法。通过使用Word2vec,我们可以方便的将词转化成向量表示,让计算机和理解图像中的每个点一样,数字化词的表现。
(2)RNN——seq2seq
LSTM也是一种RNN,不同的是LSTM能够学会远距离的上下文依赖,能够存储较远距离上下文对当前时间节点的影响。
所有的RNN都有一串重复的神经网络模块。
对于标准的RNN,这个模块都比较简单,比如使用单独的tanh层。
LSTM拥有类似的结构,但是不同的是,LSTM的每个模块拥有更复杂的神经网络结构:4层相互影响的神经网络。在LSTM每个单元中,因为门结构的存在,对于每个单元的转态,使得LSTM拥有增加或减少信息的能力。
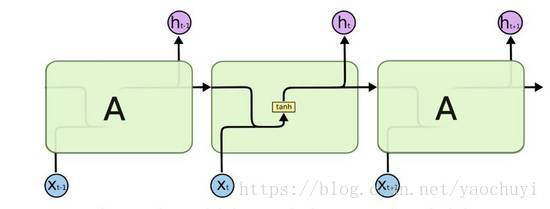
(标准RNN模型中的重复模块包括1层结构)
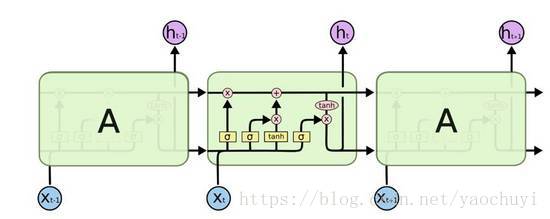
(LSTM模型中的重复模块包括4层结构)
《Neural Architectures for Named Entity Recognition》一文中提出了一种深度学习框架,如图,利用该框架可以进行中文分词。具体地,首先对语料的字进行嵌入,得到字嵌入后,将字嵌入特征输入给双向LSTM,输出层输出深度学习所学习到的特征,并输入给CRF层,得到最终模型。
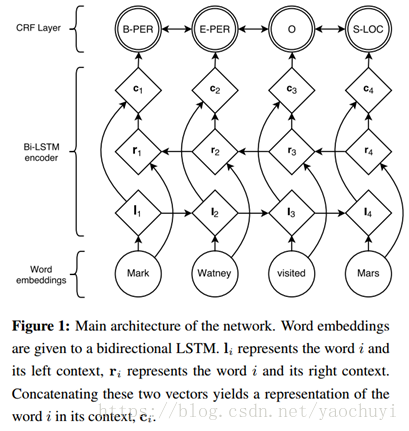
(一个深度学习框架)