接着上一篇讲。
我们发现构建一个这样的三层网络需要太多的features 了,这样会使计算大大增加。所以我们必须做一些修改,
1.在模型中将常用单词对或短语视为单个“单词”。比如:“我擦”的意思和 “我” & “擦”是不一样的。在此不再详细解释
2.对频繁的词进行子采样以减少训练实例的数量。
3.用“负采样”的技术修改优化目标,这会使每个训练样本只更新一小部分模型的权重。
subsampling:
对于“the”有两个问题。
1.当看单词对时,(“狐狸”,“the”)并没有告诉我们很多关于“狐狸”的含义。 “这个”几乎出现在每个单词的上下文中。
2.我们将有更多的样本(“the”,...)比我们需要为“the”学习一个好的向量。
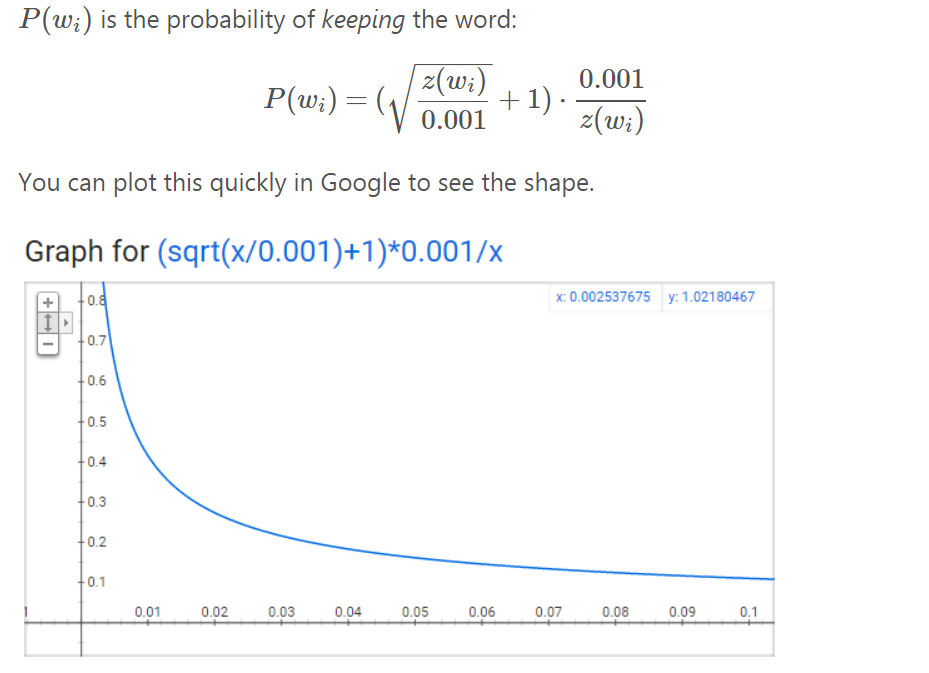
对于我们在训练文本中遇到的每个单词,我们都有可能将其从文本中有效删除。 我们删除的概率与词频有关。
词频高我们就删除它,词频低我们就subsample它

负采样 Negative sampling
每个样本导入,不是改变所有的weight 而是改变一部分。
当在单词对(“狐狸”,“快速”)上训练网络时,网络的“标签”或“正确输出”是一个热点向量。 也就是说,对于对应于“快速”的输出神经元输出1,并且对于所有其他数千个输出神经元输出0。
对于负面抽样,我们将随机选择一小部分“负面”单词(比如5)来更新权重。 (在这种情况下,“否定”一词是我们希望网络输出0的那个词)。 我们还将更新我们的“正面”单词的权重(在我们当前的例子中,这是“快速”一词)。
我们模型的输出层有一个300 x 10,000的权重矩阵。 所以我们只是更新我们正面词的权重(“快速”),加上我们想要输出的其他5个词的权重。这总共有6个输出神经元,总共有1,800个权重值。 这只是输出层3M重量的0.06%!
在隐藏层中,只更新输入词的权重(无论您是否使用负面采样,情况都是如此)。