skip-gram模型的简单介绍
skip-gram模型简单来讲就是在一大段话中,我们给定其中一个词语,希望预测它周围的词语,将词向量作为参数,通过这种方式来训练词向量,最后能够得到满足要求的词向量。而一般来讲,skip-gram模型都是比较简单的线性模型。
我们先假定有10000个单词,用one-hot-vector表示每一个。所以输入为batch*10000。输出也是batch*10000矩阵,是一个概率矩阵。
如果输入的vector代表单词ant,输出的one hot vector 中的第n个(如 mask)value,表示的是 mask 出现在ant 周围的概率。
构建的模型很简单,只有一层hidden layer。而且hidden layer没有激活函数。输出层的激活函数是softmax。

为什么输入形式为one hot vector呢?下面举一个简单的 1*5vector的例子/
输入向量 乘 weight矩阵相当于在weight矩阵中选取了其中一行 ,那么hidden layer的weight matrix 是不是可以看作word vector 的查找表呢?也就是说 hidden layer 表示的是这10000个单词所对应的300个feature。
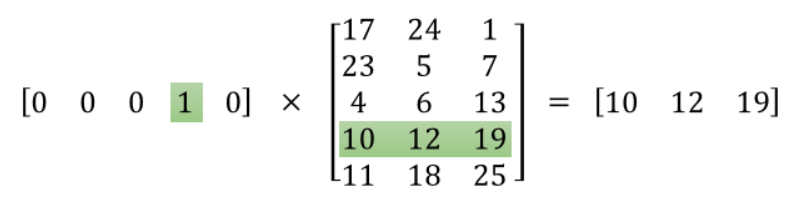
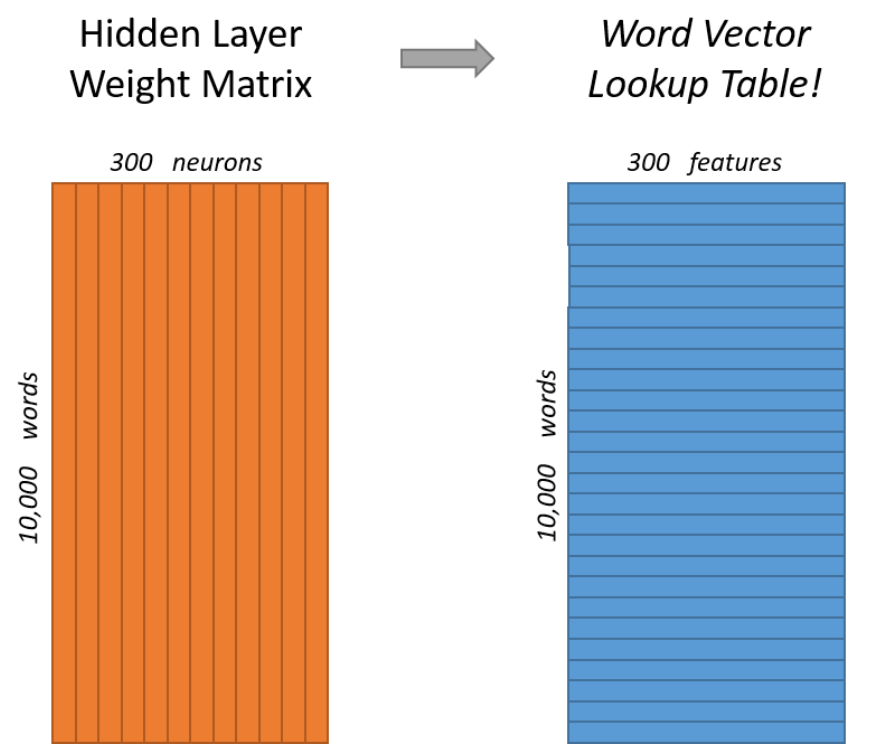
如果输入时 “ants”。说经过hidden layer 之后,输出到输出层的就是 ants 的300个features 了。如下图所示,所以ants的feature再与 输出层的 car feature 相乘再softmax,就变成了 car出现在 ants 周围的概率。

所以 如果两个单词意思相近,那么他们输出的概率向量 应该是相似的。