交叉熵和KL散度
信息熵H(X)可以看做,对X中的样本进行编码所需要的编码长度的期望值。
这里可以引申出交叉熵的理解,现在有两个分布,真实分布p和非真实分布q,我们的样本来自真实分布p。
按照真实分布p来编码样本所需的编码长度的期望为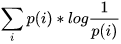 ,这就是上面说的信息熵H( p )
,这就是上面说的信息熵H( p )
按照不真实分布q来编码样本所需的编码长度的期望为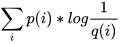 ,这就是所谓的交叉熵H( p,q )
,这就是所谓的交叉熵H( p,q )
这里引申出KL散度D(p||q) = H(p,q) - H(p) = 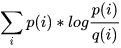 ,也叫做相对熵,它表示两个分布的差异,差异越大,相对熵越大。
,也叫做相对熵,它表示两个分布的差异,差异越大,相对熵越大。
机器学习中,我们用非真实分布q去预测真实分布p,因为真实分布p是固定的,D(p||q) = H(p,q) - H(p) 中 H(p) 固定,也就是说交叉熵H(p,q)越大,相对熵D(p||q)越大,两个分布的差异越大。
所以交叉熵用来做损失函数就是这个道理,它衡量了真实分布和预测分布的差异性。
https://www.cnblogs.com/liaohuiqiang/p/7673681.html
https://blog.csdn.net/colourful_sky/article/details/78534122?utm_source=blogxgwz0
扫描二维码关注公众号,回复:
4076974 查看本文章
