写在前面的总结:
1、目前分类损失函数为何多用交叉熵,而不是KL散度。
首先损失函数的功能是通过样本来计算模型分布与目标分布间的差异,在分布差异计算中,KL散度是最合适的。但在实际中,某一事件的标签是已知不变的(例如我们设置猫的label为1,那么所有关于猫的样本都要标记为1),即目标分布的熵为常数。而根据下面KL公式可以看到,KL散度 - 目标分布熵 = 交叉熵(这里的“-”表示裁剪)。所以我们不用计算KL散度,只需要计算交叉熵就可以得到模型分布与目标分布的损失值。

从上面介绍,知道了模型分布与目标分布差异可用交叉熵代替KL散度的条件是目标分布为常数。如果目标分布是有变化的(如同为猫的样本,不同的样本,其值也会有差异),那么就不能使用交叉熵,例如蒸馏模型的损失函数就是KL散度,因为蒸馏模型的目标分布也是一个模型,该模型针对同类别的不同样本,会给出不同的预测值(如两张猫的图片a和b,目标模型对a预测为猫的值是0.6,对b预测为猫的值是0.8)。
注:交叉熵和KL散度应用方式不同的另一种解释(我更倾向于上面我自己的解释,更具公式解释性):
交叉熵:其用来衡量在给定的真实分布下,使用非真实分布所指定的策略消除系统的不确定性所需要付出的努力的大小。这也是为什么在机器学习中的分类算法中,我们总是最小化交叉熵,因为交叉熵越低,就证明由算法所产生的策略最接近最优策略,也间接证明我们算法所算出的非真实分布越接近真实分布。
KL散度(相对熵):衡量不同策略之间的差异呢,所以我们使用KL散度来做模型分布的拟合损失。
信息量

熵

相对熵(KL散度)

交叉熵

交叉熵的实现
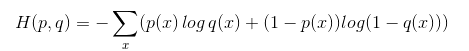
【深度学习原理】交叉熵损失函数的实现(看这里,比较清楚详细)
def cross_entropy(a, y):
return np.sum(np.nan_to_num(-y*np.log(a)-(1-y)*np.log(1-a)))
# tensorflow version
loss = tf.reduce_mean(-tf.reduce_sum(y_*tf.log(y), reduction_indices=[1]))
# numpy version
loss = np.mean(-np.sum(y_*np.log(y), axis=1))def cross_entropy(X,y):
"""
X is the output from fully connected layer (num_examples * num_classes)
y is labels (num_examples * 1)
"""
m = y.shape[0]
p = softmax(X)
log_likelihood = -np.log(p[range(m),y])
loss = np.sum(log_likelihood)/m
return loss参考:
