前言
假设有随机变量X和随机变量X’,两者拥有同样的m大小的样本空间(可能发生的事件),但两个满足不同的分布:P和Q(同一个事件发生的概率可能不同)。
信息
当X=x_i时,表明x_i这个实值所对应的事件发生了,此时x_i这个事件的信息(自信息)定义为:
I ( x i ) = − l o g p ( x i ) I(x_i) = -logp(x_i) I(xi)=−logp(xi)
由公式可知,x_i这个事件发生的概率越大,则它所包含的信息就越少。
信息熵
信息是单个事件x_i的信息量,而信息熵是随机变量X的信息量,定义为:
H ( X ) = ∑ i = 1 m − p ( x i ) l o g ( p ( x i ) ) H(X)=\sum_{i=1}^m-p(x_i)log(p(x_i)) H(X)=i=1∑m−p(xi)log(p(xi))
KL散度
KL散度用于衡量随机变量X和随机变量X’它们分布(P和Q)的差异,定义为:
D K L ( P ∣ ∣ Q ) = ∑ i = 1 m P ( x i ) l o g ( P ( x i ) / Q ( x i ) ) D_{KL}(P||Q)=\sum_{i=1}^mP(x_i)log(P(x_i)/Q(x_i)) DKL(P∣∣Q)=i=1∑mP(xi)log(P(xi)/Q(xi))
根据的https://blog.csdn.net/weixinhum/article/details/85064685推导可知,KL散度是非负的:
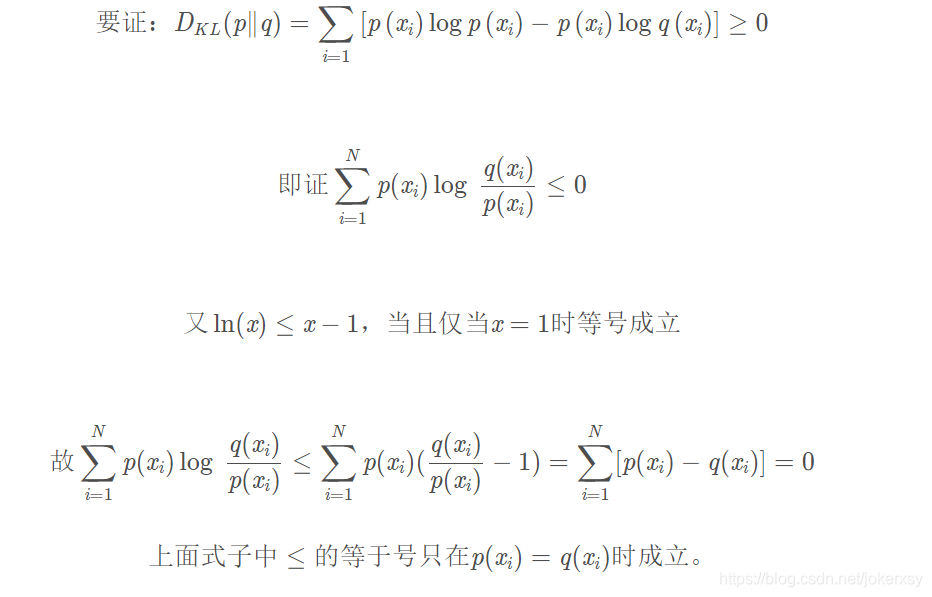
交叉熵
上面KL散度中,以P为真实分布,以Q为模型拟合出来的分布,KL散度越小越好。而由于拆分:
D K L ( P ∣ ∣ Q ) = ∑ i = 1 m P ( x i ) l o g ( P ( x i ) / Q ( x i ) ) D_{KL}(P||Q)=\sum_{i=1}^mP(x_i)log(P(x_i)/Q(x_i)) DKL(P∣∣Q)=i=1∑mP(xi)log(P(xi)/Q(xi))
D K L ( P ∣ ∣ Q ) = ∑ i = 1 m P ( x i ) l o g ( P ( x i ) ) − ∑ i = 1 m P ( x i ) l o g ( Q ( x i ) ) D_{KL}(P||Q)=\sum_{i=1}^mP(x_i)log(P(x_i)) - \sum_{i=1}^mP(x_i)log(Q(x_i)) DKL(P∣∣Q)=i=1∑mP(xi)log(P(xi))−i=1∑mP(xi)log(Q(xi))
∑ i = 1 m P ( x i ) l o g ( P ( x i ) ) 就 = − H ( X ) \sum_{i=1}^mP(x_i)log(P(x_i))就=-H(X) i=1∑mP(xi)log(P(xi))就=−H(X)
即,计算拆分KL散度之后发现,其前项就是真实分布P所对应的那个随机变量X的信息熵,它来自于模型的训练集,是一个计算好的常数。所以,为了简便计算,一般不计算前向,而直接最小化后项,也就是:
最 小 化 − ∑ i = 1 m P ( x i ) l o g ( Q ( x i ) ) 就 可 以 了 最小化- \sum_{i=1}^mP(x_i)log(Q(x_i))就可以了 最小化−i=1∑mP(xi)log(Q(xi))就可以了
而玩意儿就被称为交叉熵。
后记
只是从公式层面大致理解了一下。我认为在介绍这几个概念的过程中,一定不能离开概率论中的基本定义,比如:
- 随机变量:是一个函数,把样本空间中的样本点映射成实值
- 样本空间:随机试验中所有可能的事件(结果)集合
- 事件发生:引入了随机变量之后,那就是随机变量取一个具体的实值—>X(某事件)=x_i—>某事件得以发生
等术语,否则会造成混乱。以后再做深入理解。