版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/cheidou123/article/details/83759282
一、什么是HDFS
HDFS是什么:HDFS即Hadoop分布式文件系统(Hadoop Distributed Filesystem),以流式数据访问模式来存储超大文件,运行于商用硬件集群上,是管理网络中跨多台计算机存储的文件系统。
HDFS不适合用在:要求低时间延迟数据访问的应用,存储大量的小文件,多用户写入,任意修改文件。
二、HDFS的原理
1.hdfs数据块
HDFS上的文件被划分为块大小的多个分块,作为独立的存储单元,称为数据块,起初默认大小是64MB,从2.7.3版本改成了128MB,这个块大小可以在hdfs-site.xml修改它的大小
1.1使用数据块的好处:
⑴一个文件的大小可以大于网络中任意一个磁盘的容量
⑵使用抽象块概念而非整个文件作为存储单元,大大简化存储子系统的设计
⑶提高可用性 将每个块复制到少数几个物理上相互独立的机器上(默认为3个),可以确保在块、磁盘或机器发生故障后数据不会丢失。如果发现一个块不可用,系统会从其他地方读取另一个副本。
1.2数据块为什么不能太大
⑴重启过程中,数据块越大,系统加载时间越长
⑵数据量的大小与问题解决的复杂度呈线性关系。对于同一个算法,处理的数据量越大,时间复杂度越高。
⑶在Map Reduce框架里,Map之后的数据是要经过排序才执行Reduce操作的。这通常涉及到归并排序,而归并排序的算法思想便是“对小文件进行排序,然后将小文件归并成大文件”,因此“小文件”不宜过大。
⑷数据量的大小与问题解决的复杂度呈线性关系。对于同一个算法,处理的数据量越大,时间复杂度越高。
1.3数据块为什么不能太小
⑴减少硬盘寻道时间 如果数据块太多,会增加底层硬盘的寻道时间,这是数据量不能太小的根本原因!!!
⑵减少NameNode内存消耗 数据块信息太多,会增加namenode的内存消耗
2.hdfs结构
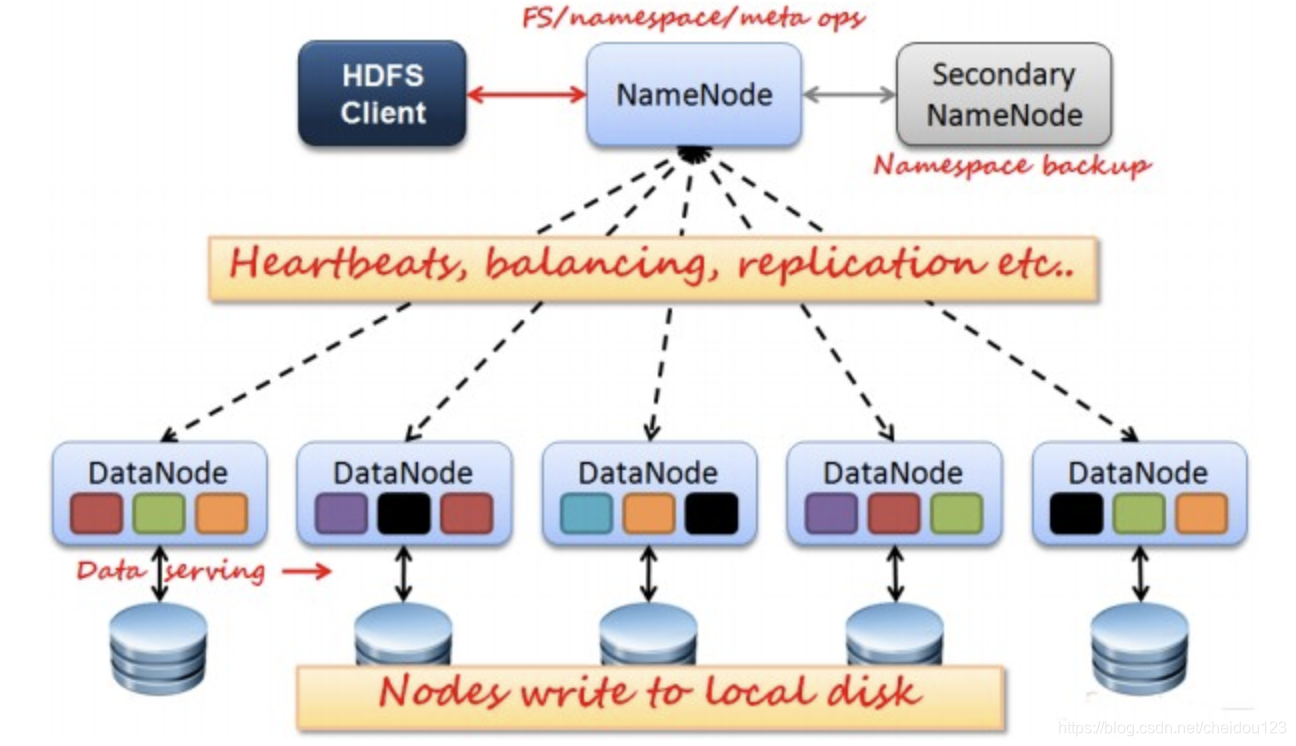
⑴Client 客户端
文件切分。文件上传 HDFS 的时候,Client 将文件切分成 一个一个的Block,然后进行存储。
与 NameNode 交互,获取文件的位置信息
与 DataNode 交互,读取或者写入数据。
Client 提供一些命令来管理 HDFS,比如启动或者关闭HDFS
Client 可以通过一些命令来访问 HDFS
⑵NameNode 就是 master,它是一个主管、管理者,namenode内存中存储的是=fsimage+edits。
管理 HDFS 的名称空间
管理数据块(Block)映射信息
配置副本策略
处理客户端读写请求
⑶Secondary NameNode 并非 NameNode 的热备,存储NameNode的一部分信息。当NameNode 挂掉的时候,它并不能马上替换 NameNode 并提供服务
辅助 NameNode,分担其工作量,SecondaryNameNode负责定时默认1小时,从namenode上,获取fsimage和edits来进行合并,然后再发送给namenode。减少namenode的工作量。
定期合并 fsimage和fsedits,并推送给NameNode
在紧急情况下,可辅助恢复 NameNode
⑷DataNode:就是Slave。NameNode 下达命令,DataNode 执行实际的操作
存储实际的数据块
执行数据块的读/写操作
⑸fsimage 元数据镜像文件(文件系统的目录树。)
⑹edits 元数据的操作日志(针对文件系统做的修改操作记录)
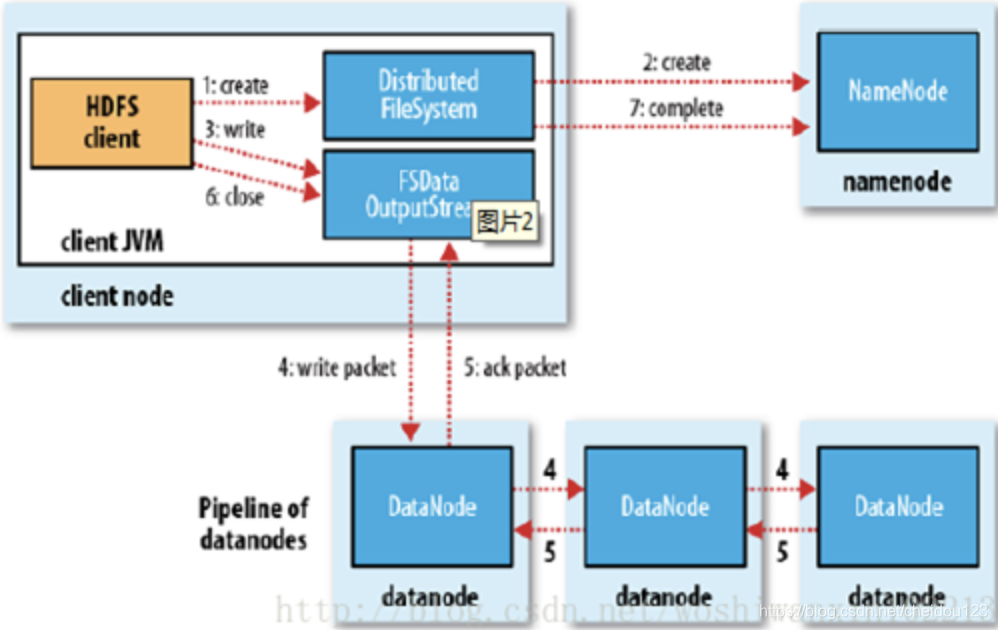
3.hdfs写入