HDFS:
HDFS即Hadoop分布式文件系统(Hadoop Distributed Filesystem),以流式数据访问模式来存储文件。
HDFS Block:
HDFS上的文件被划分为块大小的多个分块,作为独立的存储单元,称为数据块。
HDFS的三个节点:
Namenode:用来管理HDFS的元数据。
Datanode:文件系统的工作节点,负责存储元数据。
Secondary Namenode:Namenode备份节点,解决数据安全问题,与Namenode进行通信,以便定期保存HDFS元数据的快照。
HDFS的局限性:
HDFS不适合用在要求低时间延迟数据访问的应用,存储大量的小文件,多用户写入,任意修改文件。
HDFS启动过程:
1)在NameNode主节点启动时,首先进入安全模式:
1.加载fsimage,加载到内存中
2.如果edits文件不为空,那么Namenode自己来合并
3.检查DN的健康情况
4.如果有DN挂掉了,指挥做备份
2)当集群启动之时,DN会向NN发送一些信息(Block位置、DN地址)
3)client向NN汇报当前要上传的文件信息(block数量)文件的上传时间、权限、拥有者
4)client计算block的数量,向NN请求一个ID号,请求存放block的位置
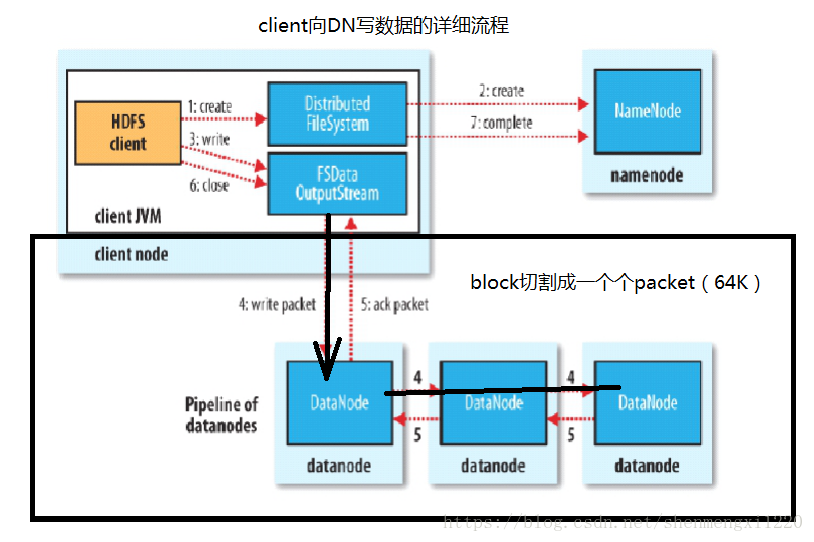
Client向Datanode写数据的详细过程:
1、如果要上传一个大文件,计算大文件的block数量大文件地址/128M=block数
2、client会向namenode汇报:
(1)当前大文件的blokc数
(2)当前大文件属于谁权限
(3)上传时间
3、client切割出来一个block
4、请求block块的ld号以及地址
5、因为namenode能够掌控全局,管理所有的DN,所以他会将负载不高的DN地址返回给client
6、client拿到地址后,向Datanode上传数据
7、DN将block存储完毕后,会向Namenode汇报当前的存储情况
Namenode的作用:
1、掌控全局,管理DataNode以及元数据
2、接受客户端的读写服务
3、收集DataNode汇报的Block列表信息NameNode保存metadata信息(包括文件owership和permissions文件大小,时间、Block列表、Block 副本位置)
4、接受client的读请求,返回地址
Datanode的作用:
1、存储block块
2、向Namenode汇报发送心跳
3、接受client的读请求
HDFS的备份机制:
1、第一个block存储在负载不是很高的一台服务器上
2、第1个备份的block存储在与第一个block不同的机架随机一条服务
3、第2个备份在与第一个备份相同的机架随机一台服务器
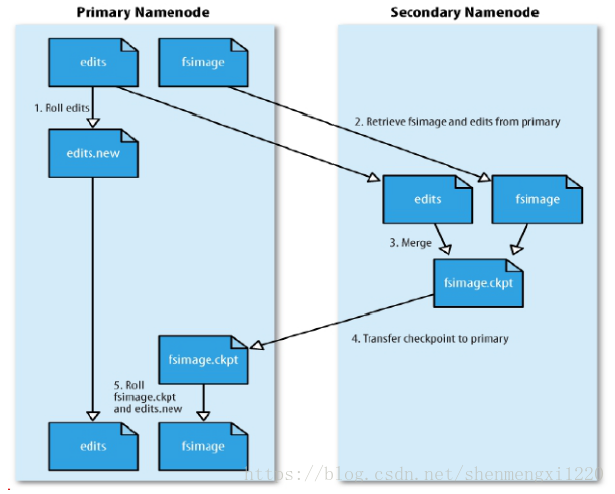
Namenode持久化:
当一个edits使用超过3600秒或者edits文件超过64M,会将edits和fsimage拉取到Secondary Namenode,模拟执行edits文件产生元数据,合并成新的fsimage.ckpt传回Namenode。
edits:具体的操作信息
fsimage:元数据
搭建集群的模式:
1、 伪分布式
在一台服务器上,启动多个进程,模拟多个角色
2、 完全分布式
在多台服务器上,每台服务器启动不同角色的进程,使用多台服务器组成HDFS集群。
3、高可用的完全分布式