1、定义
- 常见的二元分类如下:
- 邮件:垃圾邮件/非垃圾邮件
- 网络交易:欺诈/非欺诈
- 癌症:恶性/良性
- 多元分类如下:
- 将邮件分类为:工作、家人、朋友等
- 气候分类为:晴天、阴天、下雨、下雪等
2、模型设置
2.1、背景
根据上述提及的二元分类问题,在机器学习中,可以设置模型的输出为0或1:
y∈{0,1}
其中,0代表的是消极类型(比如恶性肿瘤),1代表的是积极类型(比如良性肿瘤)
阈值分类器:
Ifhθ(x)⩾0.5,predict"y=1"Ifhθ(x)<0.5,predict"y=0"
如果按照线性回归模拟,
hθ(x)的值有可能小于0或大于1,但这是不可能的,
hθ(x)的值应当在0到1之间,才能较好解决分类问题。因此,需要用到一种能使
hθ(x)的值处于0到1之间的假设函数。
2.2、逻辑回归模型
2.2.1、假设函数(模型)
- 含义
hθ(x)表示输入变量为x的情况下输出变量y=1的概率:
hθ(x)=P(y=1∣x;θ)
具体为:给定参数
θ,在
x条件下,
y=1的概率,在实际操作中,设为S型函数(或称逻辑函数):
hθ(x)=g(θTx)(1)g(z)=1+e−z1(2)
- 决策边界
如果有:
hθ(x)=g(θ0+θ1x1+θ2x2)(3)θ0=−3;θ1=1;θ2=1(4)
那么,依据式(1)至(4),可知:
predict"y=1",If−3+x1+x2⩾0predict"y=0",If−3+x1+x2<0
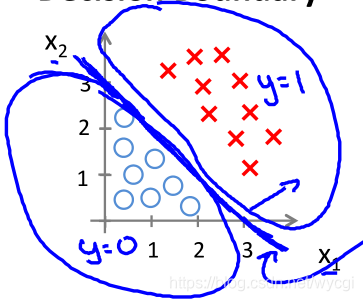
由上可知,
−3+x1+x2=0是决策边界(如下图的蓝色直线),一侧表示
y=1,另一侧表示
y=0。
另外,如果决策边界不是直线,可以根据输入特征的分布情况确定各种边界:
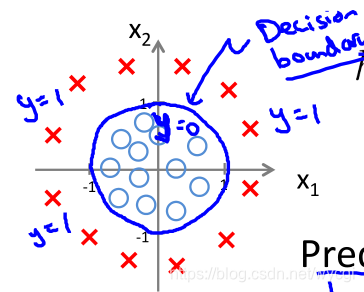
hθ(x)=g(θ0+θ1x1+θ2x2+θ3x12+θ4x22)(5)
根据式(5),如果
θ=∣∣∣∣∣∣∣∣∣∣10011∣∣∣∣∣∣∣∣∣∣,则有
1+x12+x22=0,表示为一个圆,如下图:
2.2.2、代价函数
- 线性回归的代价函数
J(θ)=m1i=1∑mcost(hθ(x(i)),y(i))J(θ)=m1i=1∑m21(hθ(x(i))−y(i))
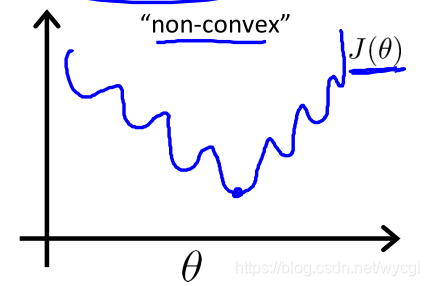
结合上文的假设函数,会使
J(θ)变成非凸函数,如下图所示,局部极值较多,难以进行回归运算:
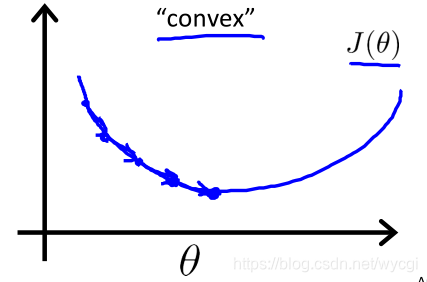
因此,根据上文的假设函数,代价函数需要是凸函数:
- 逻辑回归的代价函数
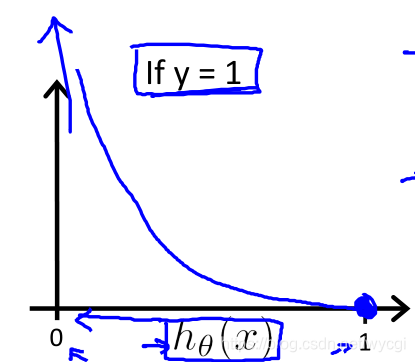
J(θ)=m1i=1∑mCost(hθ(x),y)Cost(hθ(x),y)={−log(hθ(x))−log(1−hθ(x))if y=1if y=0(6)
当
y=1时,
cos=0;当
hθ(x)→0时,
cos→∞,如下图:
当
y=0时,
cos=0;当
hθ(x)→1时,
cos→∞,如下图:

上式(6)在简化后可得:
Cost(hθ(x(i)),y(i))=−y(i)log(hθ(x(i))−(1−y(i))log(1−hθ(x(i)))
进而,代价函数如下:
J(θ)=−m1i=1∑m[y(i)log(hθ(x(i))+(1−y(i))log(1−hθ(x(i)))]
2.2.3、梯度下降
minθJ(θ):
repeat
θj:=θj−αi=1∑m(hθ(x(i))−y(i))xj(i)
刚好逻辑回归算法中代价函数的导数跟线性回归中代价函数的导数一样,厉害了。
2.2.4、软件自带的高级优化算法
-
梯度下降算法相比高级算法而言,需要设置学习速率
α,而且收敛速度慢,不如软件自带的高级优化算法(比较复杂是缺点)。
-
包括:conjugate gradient(共轭梯度法)、BFGS(变尺度法)、L-BFGS(限制变尺度法)
-
举例octave中的fminunc算法,具体操作如下:
先建立costfunction.m文件,输入模型参数
θ,输出代价函数的值和代价函数的偏导数。
costfunction.m文件如下:
function [jval,gradient] = costfunction(theta)
jval = [此处写 J(θ)];
gradient(1) = [此处写偏导数1];
gradient(2) = [此处写偏导数2];
...
然后运行以下代码:
扫描二维码关注公众号,回复:
4059890 查看本文章

option = optimset('GradObj','on','MaxIter','100');
%第一个设置梯度目标参数打开'on'(也即使用用户自定义的梯度参数gradient),第二个设置迭代次数为100
initialTheta = zeros(2,1);
[optTheta,functionVal,exitFlag] = fminunc(@costfunction,initialTheta,options)
% 左式依次表示代价函数的值,模型参数的值,是否收敛(1表示收敛)
%右式依次表示建立的costfunction函数,初始化的模型参数,函数设置
[theta, cost] = ...
fminunc(@(t)(costFunction(t, X, y)), initial_theta, options);
%实际中。。。
2.3、多元分类处理
- 多种类型下,y的值从1开始,比如邮件中工作设为1,朋友设为2,家人设为3等
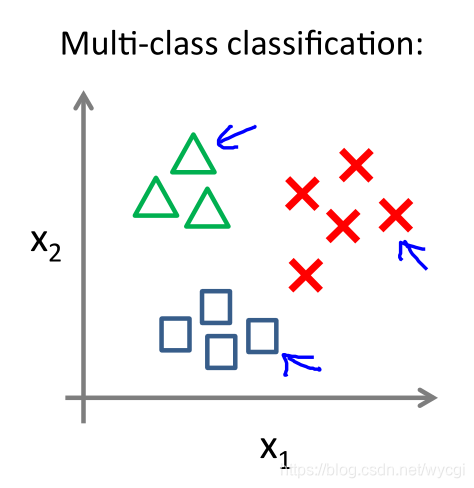
- 将每个输出类型作为一个二元分类问题,比如:工作和其他的分类;朋友和其他的分类;家人和其他的分类,得到以下假设函数:
hθ(i)(x)=P(y=i∣x;θ)(i=1,2,3)
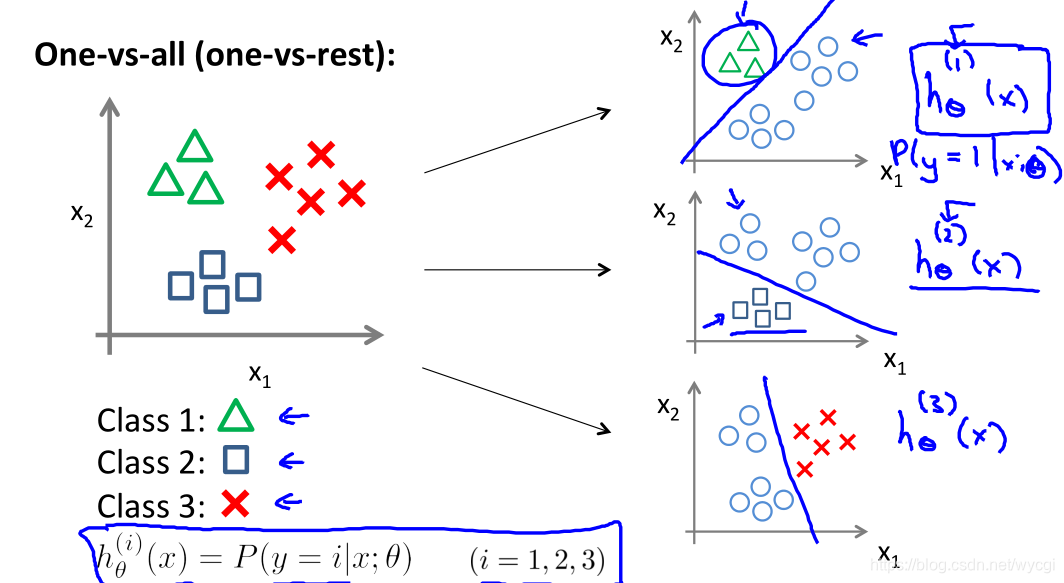
- 利用上式的假设函数进行测试时,将输入特征x分别输入到三个假设函数(分类器)中,将能够得到最大输出特征y的假设函数确认为可信度高的分类器,并根据所得到的可信度高的分类器确定分类类型。