学习大数据课程 spark 基于内存的分布式计算框架(二)RDD 编程基础使用
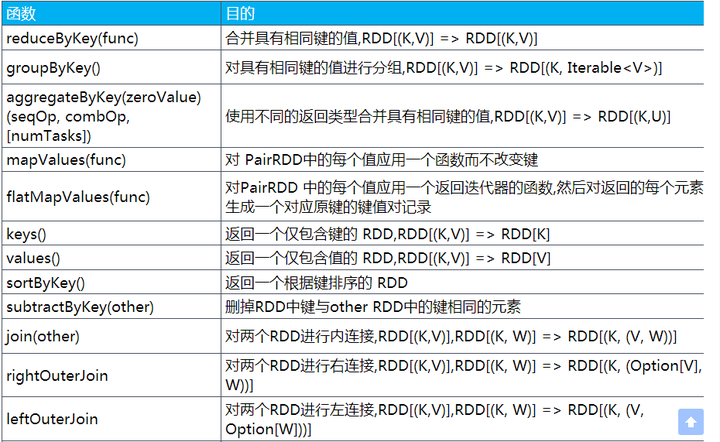
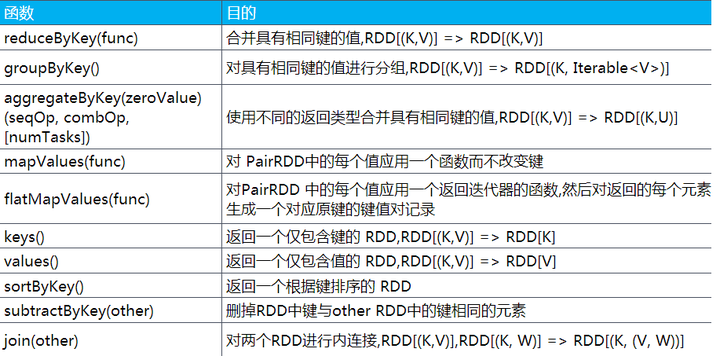
1.常用的转换
假设rdd的元素是: {1,2,2,3}

很多初学者,对大数据的概念都是模糊不清的,大数据是什么,能做什么,学的时候,该按照什么线路去学习,学完往哪方面发展,想深入了解,想学习的同学欢迎加入大数据学习qq群:199427210,有大量干货(零基础以及进阶的经典实战)分享给大家,并且有清华大学毕业的资深大数据讲师给大家免费授课,给大家分享目前国内最完整的大数据高端实战实用学习流程体系
应用于pairRdd

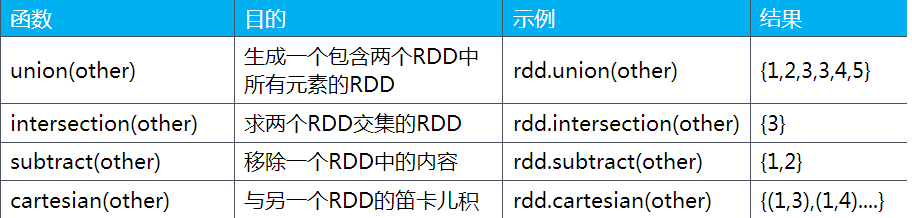
假设rdd的元素是:{1, 2, 3},other元素是:{3, 4, 5}
2.常用操作接口
假设rdd的元素是:{1, 2, 3, 3}


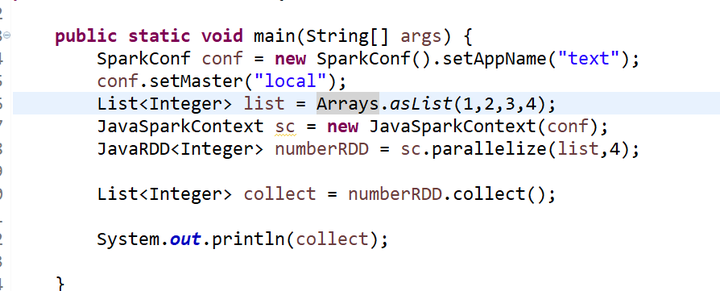
3.创建RDD
有两种方式:读取外部数据集,以及在驱动器程序中对一个集合进行并行化
parallelize 集合并行化
textFile 本地文件或者HDFS文件

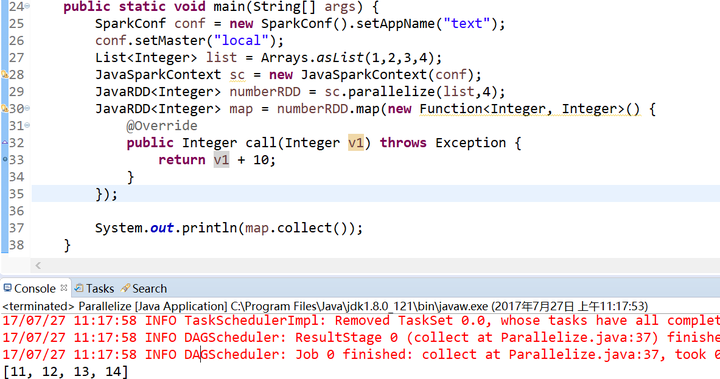
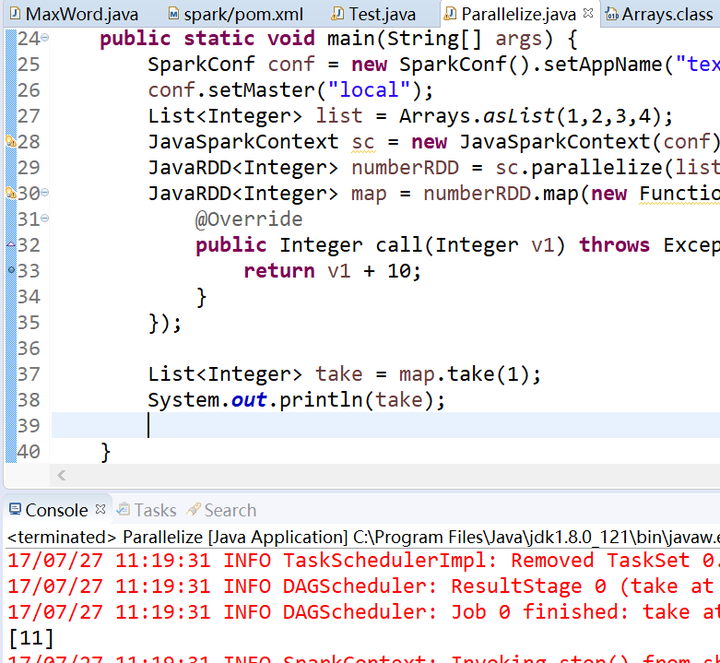
4.map()函数 和 take()函数
map(func)
take(num)
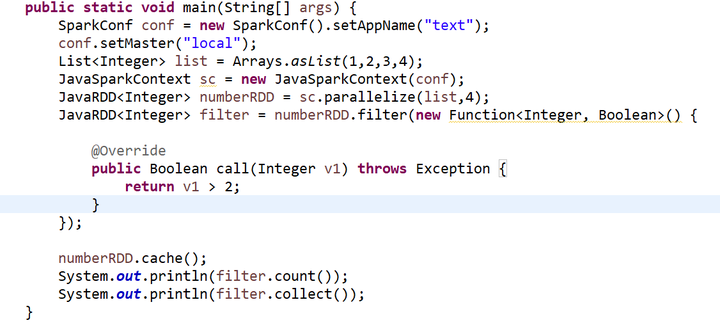
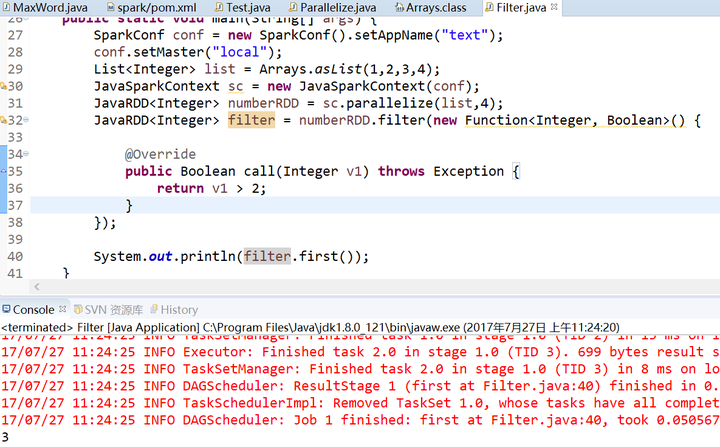
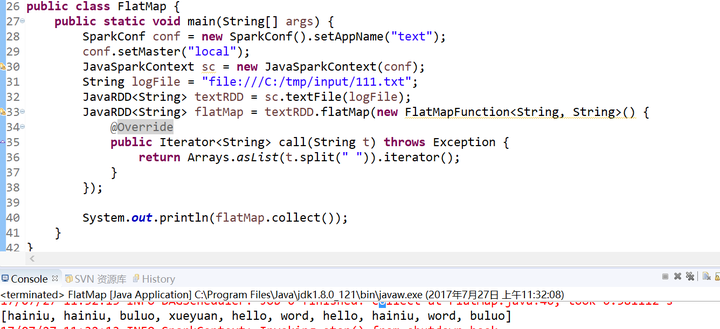
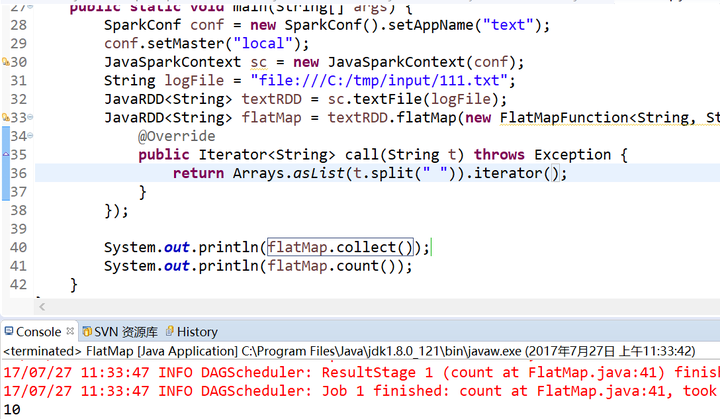
5.count()函数和collect()函数
count()
collect()
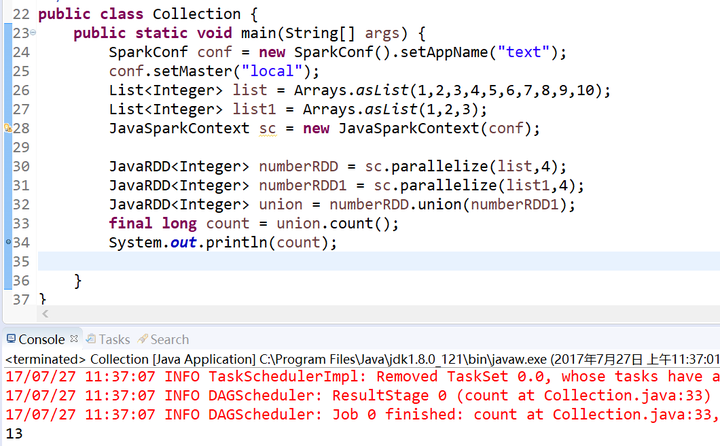
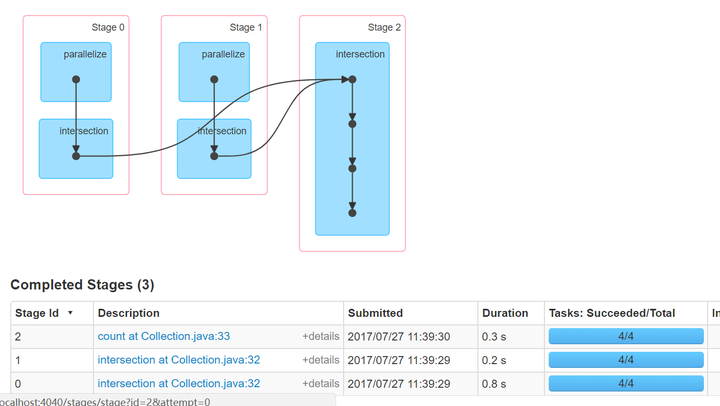
6.集合操作
distinct,去重,但其操作的开销大,因为它需要所有数据通过网络进行混洗
union

intersection

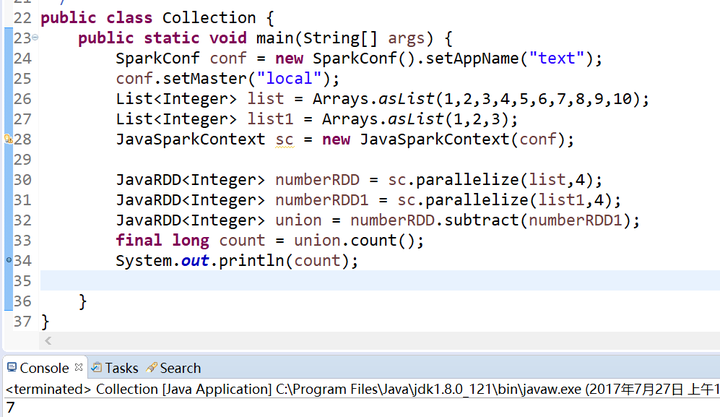
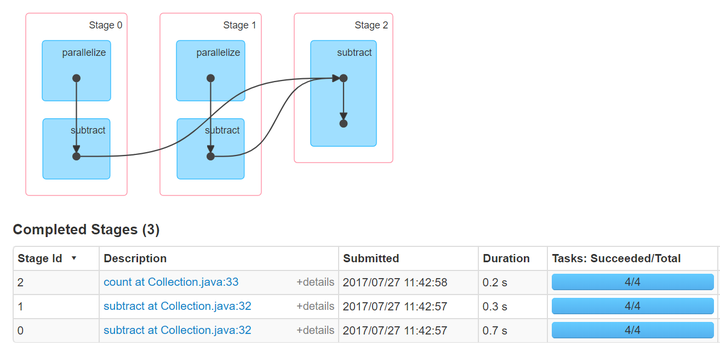
subtract


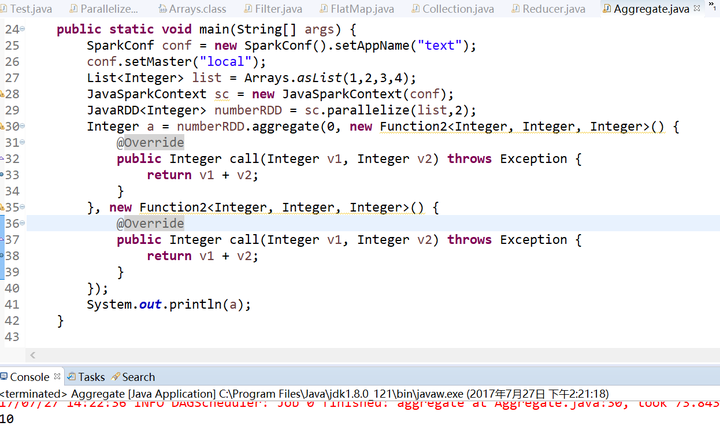
7.aggregate()函数
aggregate()函数需要我们提供期待返回的类型的初始值,然后通过一个函数把RDD中的元素合并起来放入累加器,考虑到每个节点是在本地累加的,最终,还需要通过第二个函数把累加器兩兩合并
8.top()函数和 foreach()函数
top(num)


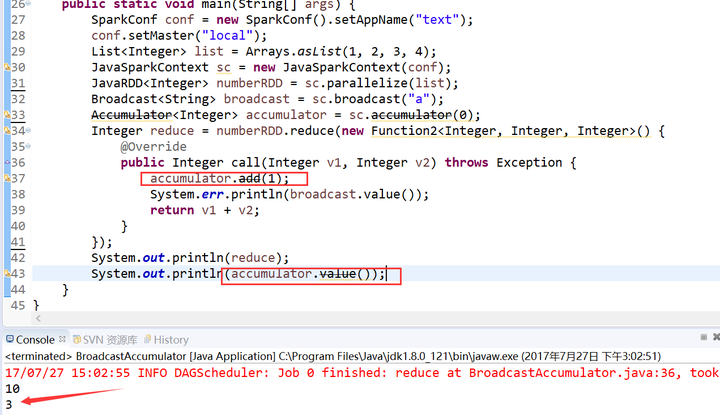
9.共享变量
我们传递给Spark的函数,如map(),或者filter()的判断条件函数,能够利用定义在函数之外的变量,但是集群中的每一个task都会得到变量的一个副本,并且task在对变量进行的更新不会被返回给driver。而Spark的两种共享变量:累加器(accumulator)和广播变量(broadcast variable)
累加器
累加器可以很简便地对各个worker返回给driver的值进行聚合。累加器最常见的用途之一就是对一个job执行期间发生的事件进行计数。
广播变量
广播变量通常情况下,当一个RDD的很多操作都需要使用driver中定义的变量时,每次操作,driver都要把变量发送给worker节点一次,如果这个变量中的数据很大的话,会产生很高的传输负载,导致执行效率降低。使用广播变量可以使程序高效地将一个很大的只读数据发送给多个worker节点,而且对每个worker节点只需要传输一次,每次操作时executor可以直接获取本地保存的数据副本,不需要多次传输。

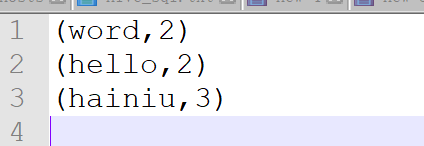


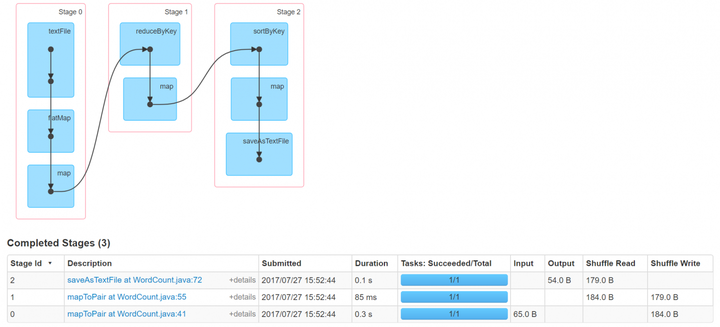
10.wordcount and sort


加油加油加油