文章目录
什么是Shuffle?
一个action会触发一个job,一个job遇到shuffle会拆分成stage,stage里面有一堆task。
有些操作会触发spark的“shuffle”操作。“shuffle”是spark里的一种机制,会对数据进行重新分区或者分发。将数据重新分组到不同的分区。这通常涉及到在executor和机器之间复制数据,涉及到磁盘I/O,数据序列化,网络I/O,使得shuffle成为复杂而昂贵的操作。

举个例子,1、2、3、4、5、6是六个分区,一个RDD的数据有很多partition,比如说1、2、3、4。1、2、3、4上面都有<key,value>格式的数据,你现在如果想根据key来进行分组,然后相同的key进行累加,那么肯定要把key相同的数据放到同一个地方才能进行累加操作,比如reduceByKey。所以要把1、2、3、4上面都是key1的映射到5上面,把都是key2的映射到6上面。这样的话相同的key都在一块了,那么现在你就可以把value加载一块了。这个数据重新分发的过程就是shuffle。这个过程会会根据key把1、2、3、4的数据复制到5、6,对性能影响比较大。
为了组织shuffle的数据,Spark将生成任务集 (就是stage)- map任务组织数据,reduce任务做数据的聚合。一个 map 任务的所有结果数据会保存在内存,直到内存不能全部存储为止。然后,这些数据将基于目标分区进行排序并写入一个单独的文件中。在 reduce 时,任务将读取相关的已排序的数据块。
面试题:为什么说shuffle是一种复杂而昂贵的操作?生产上工作中是不是应该尽可能的去规避掉shuffle呢?
shuffle通常涉及到在executor和机器之间复制数据,涉及到磁盘I/O,数据序列化,网络I/O,使得shuffle成为复杂而昂贵的操作。大多数情况下,尽可能的避免使用含有shuffle的算子,而且有shuffle很有可能会出现数据倾斜。当然只是绝大多数情况去避免使用,也有个别情况要手动添加shuffle才能起作用的。
shuffle是整个大数据的性能杀手,瓶颈所在,所以生产中尽可能的避免使用shuffle。
为了能更好的理解“shuffle”过程中发生了什么我们可以以reduceByKey为例来分析。reduceByKey操作将具备相同key的元素执行reduce函数聚合到一个tuple中生成一个新的RDD。以上就是把相同的key分到一个reduce上面去。难题是一个key对应的所有值并不一定在同一个分区里,甚至可能不在同一台机器上,但是它们必须被共同计算,最后计算的时候肯定是跨分区进行计算的。
RDD中 partition 个数怎么定?(小插曲)
RDD 由若干个 partition 组成,共有三种生成方式:
- 从 Scala 集合中创建,通过调用 SparkContext#makeRDD 或 SparkContext#parallelize
- 加载外部数据来创建 RDD,例如从 HDFS 文件、mysql 数据库读取数据等
- 由其他 RDD 执行 transform 操作转换而来
那么,在使用上述方法生成 RDD 的时候,会为 RDD 生成多少个 partition 呢?一般来说,加载 Scala 集合或外部数据来创建 RDD 时,是可以指定 partition 个数的,若指定了具体值,那么 partition 的个数就等于该值,比如:
val rdd1 = sc.makeRDD( scalaSeqData, 3 ) //< 指定 partition 数为3
val rdd2 = sc.textFile( hdfsFilePath, 10 ) //< 指定 partition 数为10
若没有指定具体的 partition 数时的 partition 数为多少呢?
- 对于从 Scala 集合中转换而来的 RDD:默认的 partition 数为 defaultParallelism,该值在不同的部署模式下不同:
①Local 模式:本机 cpu cores 的数量
②Mesos 模式:8
③Yarn:max(2, 所有 executors 的 cpu cores 个数总和) - 对于从外部数据加载而来的 RDD:默认的 partition 数为 min(defaultParallelism, 2)
- 对于执行转换操作而得到的 RDD:视具体操作而定,如 map 得到的 RDD 的 partition 数与 父 RDD 相同;union 得到的 RDD 的 partition 数为父 RDDs 的 partition 数之和…
有哪些算子会产生shuffle?
-
1) repartition 系列的操作:重新分区,生产中用的最多是合并小文件,减小生成的文件数
比如repartition 和 coalesce -
2)‘ByKey系列的操作:聚合
比如groupByKey 和 reduceByKey -
3)join系列的操作:关联(注意如果两个RDD分区一对一join是不会产生shuffle的)
比如cogroup 和 join
1)repartition 系列的操作
①spark-shell代码测试
先来一波操作:
//读取一个文件
scala> val info = sc.textFile("file:///home/hadoop/data/wordcount.txt")
info: org.apache.spark.rdd.RDD[String] = file:///home/hadoop/data/wordcount.txt MapPartitionsRDD[1] at textFile at <console>:24
scala> info.collect
res0: Array[String] = Array(world world hello, China hello, people person, love)
//partition的数量为2
scala> info.partitions.length
res3: Int = 2
//----------------------下面是coalesce操作------------
//通过coalesce把info这个RDD转换后,partition数量变成了1
scala> val info1 = info.coalesce(1)
info1: org.apache.spark.rdd.RDD[String] = CoalescedRDD[4] at coalesce at <console>:25
scala> info1.partitions.length
res4: Int = 1
//coalesce默认是一个窄依赖的算子,不会产生shuffle
//但是可以加true参数,变成宽依赖,产生shuffle
//下面希望通过coalesce把info这个RDD转换后,partition数量变成4,结果还是2,却不是4
scala> val info2 = info.coalesce(4)
info2: org.apache.spark.rdd.RDD[String] = CoalescedRDD[7] at coalesce at <console>:25
scala> info2.partitions.length
res6: Int = 2
//如果想变成4,变得比info的partition数量更大,需要加个true参数,如果变小则不用加
//变大,加true参数,会进行shuffle操作,变小则没有shuffle操作
scala> val info2 = info.coalesce(4,true)
info2: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[11] at coalesce at <console>:25
scala> info2.partitions.length
res7: Int = 4
//----------------------下面是repartition操作------------
//通过repartition(1)可以把原来info的2个partition转换为1个partition,而且不用加上true,partition数量由多变少
//用repartition虽然可以把partition有多变少,但是要避免,推荐使用coalesce,因为尽量避免使用shuffle
scala> val info3 = info.repartition(1)
info3: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[23] at repartition at <console>:25
scala> info3.partitions.length
res10: Int = 1
//通过repartition(5)可以把原来info的2个partition转换为5个partition,而且不用加上true,partition数量由少变多
//增加了并行度(一个partition一个task,一个task一个并行度)
scala> val info3 = info.repartition(5)
info3: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[19] at repartition at <console>:25
scala> info3.partitions.length
res9: Int = 5
//原因:repartition底层调用的是coalesce(numPartitions:Int,shuffle:Boolean=true)
//repartition一直存在shuffle的,数据需要重新分发
②DAG图分析
先执行:val info2 = info.coalesce(4,true),再执行info2.collect,
看DAG图:

分析:coalesce是transformation操作,不会触发job,遇到collect触发job,coalesce中的参数为true,会产生shuffle,所以遇到coalesce的时候生成了stage1和stage2。
再执行 val info1 = info.coalesce(1),然后执行info1.collect,
看DAG图:
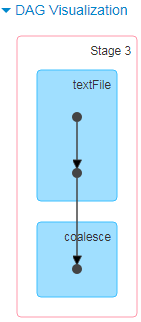

分析:coalesce是transformation操作,不会触发job,遇到collect触发job,coalesce中的参数没有true,默认是false,不会产生shuffle,所以中间没有拆分成新的stage。并且可以看到stage3里面只有1个task。
再执行val info3 = info.repartition(1),然后执行info3.collect,
看DAG图:

分析:repartition是transformation操作,不会触发job,遇到collect触发job,repartition底层调用的是coalesce(1,true),会产生shuffle,所以遇到coalesce的时候生成了stage4和stage5。
再执行 val info4 = info.repartition(5),然后info4.collect,
看DAG图:


分析:repartition是transformation操作,不会触发job,遇到collect触发job,repartition底层调用的是coalesce(5,true),会产生shuffle,所以遇到coalesce的时候生成了stage6和stage7。并且可以看出stage6里面有2个task,stage7里面有5个task。
③IDEA代码测试
mapPartitionsWithIndex((index,partition)这个算子,是分分区,然后给它加个Partition编号(从0开始)。可以通过这个算子拿到分区的id
package com.ruozedata.spark.com.ruozedata.spark.core
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.ListBuffer
object RepartitionApp {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("LogApp").setMaster("local[2]")
val sc = new SparkContext(sparkConf)
//parallelize是可以设置并行度的,不设置的话有默认值,这里不设置的话是2
val students = sc.parallelize(List("zhangsan","lisi","wangwu","xiaoming","lilei","zhaoliu","zhengqi"),3)
/*
val stus = new ListBuffer[]
创建一个空的可变列表stus
向stus中追加元素,可以这样:stus +="zhangsan" 或者这样:stus.append("zhnagsan")。注意:没有生成新的集合
*/
//此代码的意思是进来7个人,然后分组
//这里是分成三组
students.mapPartitionsWithIndex((index,partition) => {
val stus = new ListBuffer[String]
while(partition.hasNext){
stus +=("----" + partition.next() + ",哪个组: " + (index+1))//index是从0开始的
}
stus.iterator
}).foreach(println)
sc.stop()
}
}
运行结果:
----wangwu,哪个组: 2
----xiaoming,哪个组: 2
----zhangsan,哪个组: 1
----lisi,哪个组: 1
----lilei,哪个组: 3
----zhaoliu,哪个组: 3
----zhengqi,哪个组: 3
上面是分成了三个组,那么如果现在想分成2个组,怎么办?
在students后面加个coalesce(2)就可以了:
students.coalesce(2).mapPartitionsWithIndex((index,partition) => {
运行结果如下:
----zhangsan,哪个组: 1
----wangwu,哪个组: 2
----lisi,哪个组: 1
----xiaoming,哪个组: 2
----lilei,哪个组: 2
----zhaoliu,哪个组: 2
----zhengqi,哪个组: 2
上面的partition数量由3变为2,由多变少。那么由少变多呢?
比如如果现在想分成4个组,怎么办?
在students后面加个repartition(4)就可以了:
students.repartition(4).mapPartitionsWithIndex((index,partition) => {
运行结果:
----lisi,哪个组: 1
----wangwu,哪个组: 2
----lilei,哪个组: 1
----zhaoliu,哪个组: 2
----xiaoming,哪个组: 3
----zhengqi,哪个组: 3
----zhangsan,哪个组: 4
小知识点:mapPartitions效率比map高的多,开发应首先mapPartitions,但是当partition数据很大时有OOM的风险,要注意。
④repartition 和 coalesce在生产中的应用??(重要)
①举个经典的例子,现在有一个RDD,有500个partition分区,每个分区有50万条数据,每个分区里面只有一个id=1的记录,现在对这个RDD进行filter过滤,过滤条件为id=1。那么过滤之后每个分区就只有一条记录了,filter是窄依赖,过滤之后还是有500个分区,每个分区只有一条记录,分区数决定了最终文件的个数。那么显然最终由很多很多小文件。(小文件的危害???)所以这个时候要借助coalesce来收敛一下了。
当spark程序中,存在过多的小任务的时候,可以通过 RDD.coalesce方法,收缩合并分区,减少分区的个数,减小任务调度成本,避免Shuffle导致,比RDD.repartition效率提高不少。
②另外也可以借助coalesce来合并小文件。
③如果分区数过少,而分区的数据量很大,(生产上每条记录最终出来的结果有多大是知道的,每个业务线最终出来的结果有多大肯定是知道的),可以用reparation把数据打散,比如原来10个partition,现在重新分发数据变成20个partition,来提高并行度。N个分区有数据分布不均匀的状况,重新分发数据,可以减少数据倾斜的程度。
2)‘ByKey系列的操作
①reduceByKey(func, [numPartitions])
现在来执行wordcount案例:
scala> sc.textFile("file:///home/hadoop/data/wordcount.txt").flatMap(_.split("\t")).map((_,1)).reduceByKey(_+_).collect
res19: Array[(String, Int)] = Array((love,1), (hello,2), (world,2), (people,1), (China,1), (person,1))
看DAG图:


从上图可以看出,先读取一个文件,进行flatMap,然后进行map,每个key赋上一个1,然后遇到reduceByKey,含有shuffle,拆分成两个stage,每个stage的task数量是2。shuffle的时候map后会写(shuffle write,大小为223.0 B),后面reduce会读(shuffle read,大小为223.0 B)。
reduceByKey(+)这个算子执行后RDD数据结构是什么?
org.apache.spark.rdd.RDD[(String, Int)]
(tuple,是个元组,单词和单词出现的数量)
②groupByKey([numPartitions])
看一下groupByKey的数据结构:
scala> sc.textFile("file:///home/hadoop/data/wordcount.txt").flatMap(_.split("\t")).map((_,1)).groupByKey()
res21: org.apache.spark.rdd.RDD[(String, Iterable[Int])] = ShuffledRDD[59] at groupByKey at <console>:25
scala> sc.textFile("file:///home/hadoop/data/wordcount.txt").flatMap(_.split("\t")).map((_,1)).groupByKey().foreach(println)
(people,CompactBuffer(1))
(China,CompactBuffer(1))
(person,CompactBuffer(1))
(love,CompactBuffer(1))
(hello,CompactBuffer(1, 1))
(world,CompactBuffer(1, 1))
RDD[(String, Iterable[Int])] 第一个是String类型,第二个是可迭代的,里面是Int类型
如果用groupByKey实现wordcount案例呢??
scala> sc.textFile("file:///home/hadoop/data/wordcount.txt").flatMap(_.split("\t")).map((_,1)).groupByKey().map(x => (x._1,x._2.sum)).collect
res31: Array[(String, Int)] = Array((love,1), (hello,2), (world,2), (people,1), (China,1), (person,1))
看UI:


从上图可以看出,先读取一个文件,进行flatMap,然后进行map,每个key赋上一个1,然后遇到groupByKey,含有shuffle,拆分成两个stage,每个stage的task数量是2。shuffle的时候map后会写(shuffle write,大小235.0 B),后面reduce会读(shuffle read,大小为235.0 B)。
③比较reduceByKey和groupByKey
来看groupByKey和reduceByKey的两张图:

groupbykey是全局聚合算子,将所有map task中的数据都拉取到shuffle中将key相同的数据进行聚合,它存在很多弊端,例如:将大量的数据进行网络传输,浪费大量的资源,最重要的是如果数据量太大还会出现GC和OutOfMemoryError的错误,如果数据某个key的数据量远大于其他key的数据,在进行全局聚合的时候还会出现数据倾斜的问题。

reducebykey是在map阶段进行本地聚合以后才会到shuffle中进行全局聚合,相当于是进入shuffle之前已经做了一部分聚合,那么它的网络传输速度会比groupbykey快很多而且占用资源也会减少很多,但是算子本身就如它的名字一样,主要是进行计算的将相同key的数据进行计算,返回计算结果。
比较reduceByKey和groupByKey得知,两个shuffle的时候map后写(shuffle write),后面reduce读(shuffle read)的大小是不一样的,groupByKey的shuffle write、shuffle read要比reduceByKey的shuffle write、shuffle read的大。
就是说reduceByKey的shuffle数据要比groupByKey的shuffle数据少。
原因是groupByKey是对所有数据进行shuffle,这些数据并不进行计算。底层调的是combineByKeyWithClassTag方法,传参 mapSideCombine: Boolean = false,不进行局部聚合。
而reduceByKey进行了局部的combine,本地的聚合,减少shuffle的数据量,然后再把本地聚合后的结果数据进行shuffle,而且还有计算。底层调的是combineByKeyWithClassTag方法,默认传参 mapSideCombine: Boolean = true,进行局部聚合。
所以在生产上工作中优先使用reduceByKey,要谨慎使用groupbykey。
小知识点:看一下collect源码:
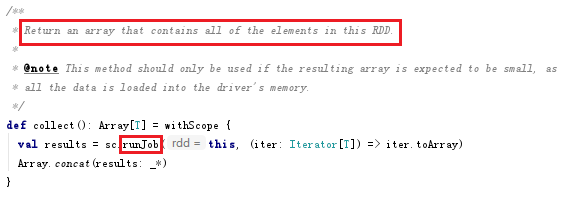
①只要看到一个操作里面有runJob,就可以判断这个算子是一个action类型的,会触发一个job。②collect会返回一个RDD的所有元素。现在你在spark-shell的控制台上对一个RDD执行collect,如果这个RDD数据量非常大,几亿条数据,那么会发生什么?肯定会发生OOM的。这个算子只适用于数据量比较小的,因为它会把所有数据加载到driver内存里去。③concat(results: _*),是把results转变为一个可变参数
④aggregateByKey
实际的项目中在进行聚合之后我们不一定只是要计算,还会找聚合后某个字段的最大值,最小值等等操作,groupbykey聚合后返回的是(K,Iterable[V]),我们可以把iterable[V]这个集合的数据进行二次处理来实现我们实际的项目需求,但是上面已经提到了groupbykey的诸多问题,reducebykey也是只有在单纯的对数据进行计算的时候才能和groupbykey有等价效果。既想像reducebykey那样进行本地聚合,又想像groupbykey那样返回一个集合便于我们操作。
aggregatebykey和reducebykey一样首先在本地聚合,然后再在全局聚合。它的返回值也是由我们自己设定的。
aggregateByKey(zeroValue)(seqOp, combOp, [numPartitions])
当调用(K,V)对的数据集时,返回(K,U)对的数据集,其中使用给定的combine函数和zeroValue聚合每个键的值。允许与输入值类型不同的聚合值类型,同时避免不必要的分配。与groupByKey类似,reduce任务的数量可通过第二个参数进行配置。
aggregatebykey使用需要提供三个参数:
zeroValue: U 这个参数就会决定最后的返回类型
seqOp: (U, V) => U 将V(数据)放入U中进行本地聚合
combOp: (U, U) => U 将不同的U进行全局聚合
举个例子:
这个例子原创来自:Spark学习之路(四)—— RDD常用算子详解:https://www.e-learn.cn/content/qita/2346057
val list = List(("hadoop", 3), ("hadoop", 2), ("spark", 4), ("spark", 3), ("storm", 6), ("storm", 8))
sc.parallelize(list,numSlices = 2).aggregateByKey(zeroValue = 0,numPartitions = 3)(
seqOp = math.max(_, _),
combOp = _ + _
).collect.foreach(println)
//输出结果:
(hadoop,3)
(storm,8)
(spark,7)
这里使用了numSlices = 2指定aggregateByKey父操作parallelize的分区数量为2,
这个时候要特别注意,zeroValue = 0,其实是个初始值,给了个初始值
其执行流程如下:

基于同样的执行流程,如果numSlices = 1,则意味着只有输入一个分区,则其最后一步combOp相当于是无效的,执行结果为:
(hadoop,3)
(storm,8)
(spark,4)
同样的,如果每个单词对一个分区,即numSlices = 6,此时相当于求和操作,执行结果为:
(hadoop,5)
(storm,14)
(spark,7)
aggregateByKey(zeroValue = 0,numPartitions = 3)的第二个参数numPartitions决定的是输出RDD的分区数量,想要验证这个问题,可以对上面代码进行改写,使用getNumPartitions方法获取分区数量:
sc.parallelize(list,numSlices = 6).aggregateByKey(zeroValue = 0,numPartitions = 3)(
seqOp = math.max(_, _),
combOp = _ + _
).getNumPartitions

3)join系列的操作
①cogroup
cogroup(otherDataset, [numPartitions])
When called on datasets of type (K, V) and (K, W), returns a dataset of (K, (Iterable, Iterable)) tuples. This operation is also called groupWith.
在一个 (K, V) 对的 dataset 上调用时,返回一个 (K, (Iterable, Iterable)) tuples 的 dataset。
举个例子:
这个例子原创来自:Spark学习之路(四)—— RDD常用算子详解:https://www.e-learn.cn/content/qita/2346057
scala> val list01 = List((1, "a"),(1, "a"), (2, "b"), (3, "e"))
list01: List[(Int, String)] = List((1,a), (1,a), (2,b), (3,e))
scala> val list02 = List((1, "A"), (2, "B"), (3, "E"))
list02: List[(Int, String)] = List((1,A), (2,B), (3,E))
scala> val list03 = List((1, "[ab]"), (2, "[bB]"), (3, "eE"),(3, "eE"))
list03: List[(Int, String)] = List((1,[ab]), (2,[bB]), (3,eE), (3,eE))
scala> sc.parallelize(list01).cogroup(sc.parallelize(list02),sc.parallelize(list03))
res37: org.apache.spark.rdd.RDD[(Int, (Iterable[String], Iterable[String], Iterable[String]))] = MapPartitionsRDD[118] at cogroup at <console>:31
// 输出: 同一个RDD中的元素先按照key进行分组,然后再对不同RDD中的元素按照key进行分组
scala> sc.parallelize(list01).cogroup(sc.parallelize(list02),sc.parallelize(list03)).foreach(println)
(1,(CompactBuffer(a, a),CompactBuffer(A),CompactBuffer([ab])))
(3,(CompactBuffer(e),CompactBuffer(E),CompactBuffer(eE, eE)))
(2,(CompactBuffer(b),CompactBuffer(B),CompactBuffer([bB])))
②join
join(otherDataset, [numPartitions])
When called on datasets of type (K, V) and (K, W), returns a dataset of (K, (V, W)) pairs with all pairs of elements for each key. Outer joins are supported through leftOuterJoin, rightOuterJoin, and fullOuterJoin.
在一个 (K, V) 和 (K, W) 类型的 dataset 上调用时,返回一个 (K, (V, W)) pairs 的 dataset,等价于内连接操作。如果想要执行外连接,可以使用leftOuterJoin, rightOuterJoin 和 fullOuterJoin 等算子。
注意如果两个RDD分区一对一join是不会产生shuffle的。
举例:
scala> a.collect
res10: Array[(String, String)] = Array((a,a1), (b,b1), (c,c1), (d,d1), (f,f1), (f,f2))
scala> b.collect
res11: Array[(String, String)] = Array((a,a2), (c,c2), (c,c3), (e,e1))
//inner join
scala> a.join(b).collect
res14: Array[(String, (String, String))] = Array((a,(a1,a2)), (c,(c1,c2)), (c,(c1,c3)))
//left join
scala> a.leftOuterJoin(b).collect
res15: Array[(String, (String, Option[String]))] = Array((d,(d1,None)), (b,(b1,None)), (f,(f1,None)), (f,(f2,None)), (a,(a1,Some(a2))), (c,(c1,Some(c2))), (c,(c1,Some(c3))))
//right join
scala> a.rightOuterJoin(b).collect
res16: Array[(String, (Option[String], String))] = Array((e,(None,e1)), (a,(Some(a1),a2)), (c,(Some(c1),c2)), (c,(Some(c1),c3)))
//full join
scala> a.fullOuterJoin(b).collect
res17: Array[(String, (Option[String], Option[String]))] = Array((d,(Some(d1),None)), (b,(Some(b1),None)), (f,(Some(f1),None)), (f,(Some(f2),None)), (e,(None,Some(e1))), (a,(Some(a1),Some(a2))), (c,(Some(c1),Some(c2))), (c,(Some(c1),Some(c3))))
参考博客:
https://www.jianshu.com/p/54b3a4e786d9
https://blog.csdn.net/qq_24674131/article/details/85114760
https://www.e-learn.cn/content/qita/2346057
https://blog.csdn.net/jiaotongqu6470/article/details/78457966