决策树算法描述:

ID3与C4.5的区别在于:
【1】ID3使用信息增益作为特征选择的度量
【2】C4.5使用信息增益率作为特征选择的度量

C4.5用信息增益率来选择属性,克服了用信息增益选择属性是偏向选择去之多的属性的不足;在树的构造过程中进行剪枝;能够对连续的属性进行离散化处理;能够对不完整的数据进行处理。
实验过程:
根据西瓜数据集2.0的数据,对'色泽', '根蒂', '敲击', '纹理', '脐部', '触感'等六大属性进行划分构建决策树。然后根据建立的模型分别对测试数据进行单样例和多样例测试,得到划分结果。
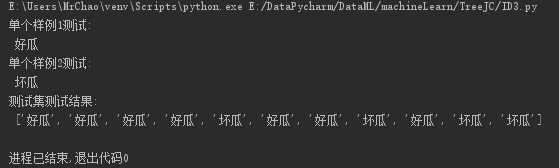
【1】ID3算法测试
根据ID3算法使用信息增益作为特征选择的度量,构建决策树,得到结果如图:

##构建测试集:
testSet = [
['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑'],
['乌黑', '蜷缩', '沉闷', '清晰', '平坦', '硬滑'],
['乌黑', '蜷缩', '浊响', '清晰', '凹陷', '硬滑'],
['青绿', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑'],
['浅白', '蜷缩', '浊响', '模糊', '凹陷', '硬滑'],
['乌黑', '硬挺', '沉闷', '稍糊', '稍凹', '软粘'],
['青绿', '蜷缩', '清脆', '清晰', '平坦', '软粘'],
['浅白', '硬挺', '清脆', '模糊', '平坦', '硬滑'],
['浅白', '蜷缩', '浊响', '清晰', '凹陷', '硬滑'],
['青绿', '稍蜷', '浊响', '稍糊', '凹陷', '硬滑'],
['浅白', '稍蜷', '沉闷', '稍糊', '凹陷', '硬滑'],
]featLabels = ['色泽', '根蒂', '敲击', '纹理', '脐部', '触感']
# 单个样例测试
testVec_1 = ['浅白', '蜷缩', '浊响', '清晰', '凹陷', '硬滑']
testVec_2 = ['乌黑', '硬挺', '浊响', '稍糊', '凹陷', '硬滑']
print('单个样例1测试:\n', classify(myTree, featLabels, testVec_1))
print('单个样例2测试:\n', classify(myTree, featLabels, testVec_2))
#testSet测试
testSet = createTestSet()
print('测试集测试结果:\n', classifyAll(myTree, featLabels, testSet))测试结果:
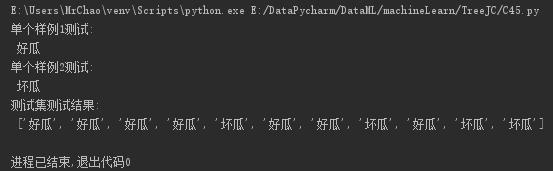
【2】C4.5算法测试
根据C4.5算法使用信息增益率作为特征选择的度量,构建决策树,得到结果如图:

##构建测试集:
testSet = [
['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑'],
['乌黑', '蜷缩', '沉闷', '清晰', '平坦', '硬滑'],
['乌黑', '蜷缩', '浊响', '清晰', '凹陷', '硬滑'],
['青绿', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑'],
['浅白', '蜷缩', '浊响', '模糊', '凹陷', '硬滑'],
['乌黑', '硬挺', '沉闷', '稍糊', '稍凹', '软粘'],
['青绿', '蜷缩', '清脆', '清晰', '平坦', '软粘'],
['浅白', '硬挺', '清脆', '模糊', '平坦', '硬滑'],
['浅白', '蜷缩', '浊响', '清晰', '凹陷', '硬滑'],
['青绿', '稍蜷', '浊响', '稍糊', '凹陷', '硬滑'],
['浅白', '稍蜷', '沉闷', '稍糊', '凹陷', '硬滑'],
]featLabels = ['色泽', '根蒂', '敲击', '纹理', '脐部', '触感']
# 单个样例测试
testVec_1 = ['浅白', '蜷缩', '浊响', '清晰', '凹陷', '硬滑']
testVec_2 = ['乌黑', '硬挺', '浊响', '稍糊', '凹陷', '硬滑']
print('单个样例1测试:\n', classify(myTree, featLabels, testVec_1))
print('单个样例2测试:\n', classify(myTree, featLabels, testVec_2))
#testSet测试
testSet = createTestSet()
print('测试集测试结果:\n', classifyAll(myTree, featLabels, testSet))测试结果:
实验总结:
通过实验结果观察,给定正确训练集构建决策树,在小数量的测试集上,由ID3与C4.5所得的决策树的模型来预测的结果是一致的。由于我这里测试的testSet的数据量有限,所以很难体现出C4.5在准确率上比ID3的优势。
总而言之,C4.5算法采用信息增益率来选择属性,产生分类的规则易于理解,克服了用信息增益选择属性时偏向选择取值多的属性的不足在树构造过程中进行剪枝;能够对不完整数据进行处理。但与此,C4.5效率低,因为在树构造过程中,需要对数据集进行多次的顺序扫描和排序。也因为必须多次数据集扫描,C4.5只适合于能够驻留于内存的数据集。