目录
C4.5算法是用于生成决策树的一种经典算法,是ID3算法的一种延伸和优化。
所以要介绍C4.5算法,就要把ID3,以及ID3中设计的熵的概念一起进行讲解。
关于熵的概念在溯源探幽--熵的世界文章中做了很详细的介绍,所以这里大致过一下。
一、熵的认识
1、熵的概念
熵:是表示随机变量不确定性的度量,熵的取值越大,随机变量的不确定性也越大。
设X是一个取有限个值的离散随机变量,其概率分布为
P(X=xi)=pi, i=1,2,⋯,n
熵计算公式:H(X)=- ∑ pi * logpi,i=1,2, ... , n
一个栗子: A集合[1,1,2,2,2,2,2,2,2,2]
B集合[1,1,2,3,4,5,6,7,8,9]
先观察下数据,对于集合A,里面只有1、2两个不同数据;
而B集合里面有9个不同数据,很显然B比A更加混乱一些,
这是我们直观的感受,接下来我们用公式计算一下
H(A)=-2/10*log(2/10)+(-8/10*log(8/10))=0.217
(1的概率为2/10,2的概率为8/10)
H(B)=-2/10*log(2/10)+(-1/10*log(1/10))*8=0. 940
(1的概率为2/10,其他8个值的概率为1/10)
通过公式计算我们也可以得到,A的熵值较小,说明A比B更加有效一点
对于熵:H(X)=- ∑ pi * logpi
不确定性越大,得到的熵值也就越大
当p=0或p=1时,H(p)=0,随机变量完全没有不确定性
当p=0.5时,H(p)=1,此时随机变量的不确定性最大
2、信息熵公式推导
对于公式H(X)我们也可以进行简单的推导:
假设我们有两个类别1,2.对应的概率分别为P1=x ,P2=1-x
H(x)=-(xlog(x)+(1-x)log(1-x)),其实就是求H(X)的极值点,
很显然,当x趋于+∞和-∞时,H(X)趋于0,所以就变成求最大值点,最简单的方式就是求导;
H(x)’=log(x)-1/ln(a)-log(1-x)+1/ln(a)=0
Log(x)-log(1-x)=0
Log(x/(1-x))=0
x/(1-x)=1
最终可以求的x=0.5(如下图)

二、ID3
ID3算法的核心是在决策树各个子节点上应用信息增益准则选择特征,递归的构建决策树.
具体方法是:从根节点开始,对节点计算所有可能的特征的信息增益,选择信息增益最大的特征作为节点的特征,由该特征的不同取值建立子节点;再对子节点递归调用以上方法,构建决策树。直到所有特征的信息增益均很小或没有特征可以选择为止。最后得到一个决策树。
【信息增益:表示特征X使得类Y的不确定性减少的程度。(分类后的专一性,希望分类后的结果是同类在一起) 】
ID3过程:
根据信息增益(Informationgain)来选取Feature作为决策树分裂的节点.特征A对训练数据集D的信息增益定义为集合D的经验熵(所谓经验熵,指的是熵是有某个数据集合估计得到的)H(D)与特征A给定条件下D的经验条件熵 H(D∣A) 之差,记为g(D,A).
g(D,A)=H(D)−H(D|A) 实际上就是特征A和D的互信息
实例论证
插入一个例子:接下来所有的算法和实践都用本例来进行计算
小王是一家著名高尔夫俱乐部的经理。但是他被雇员数量问题搞得心情十分不好。某些天好像所有人都來玩高尔夫,以至于所有员工都忙的团团转还是应付不过来,而有些天不知道什么原因却一个人也不来,俱乐部为雇员数量浪费了不少资金。
小王的目的是通过下周天气预报寻找什么时候人们会打高尔夫,以适时调整雇员数量。因此首先他必须了解人们决定是否打球的原因。

回到ID3算法
分别以A1,A2,A3,A4 来表示
outlook,temperature,humidity和windy情况4个特征,下面来计算每个特征的信息增益.
具体如下:
在历史数据中(14天)有9天打球,5天不打球,
所以此时总体的熵应为:
H(D)=-9/14*log(9/14)-5/14*log(4/14)=0.940

4个特征逐一分析,先从outlook特征开始:
Outlook = sunny时,
H(D|A1=sunny)=-2/5*log(2/5)-3/5*log(3/5)=0.971
Outlook = overcast时,
H(D|A1=overcast)=-4/4*log(4/4)-0/4*log(0/4)= 0
Outlook = rainy时,
H(D|A1=rainy)=-3/5*log(3/5)-2/5*log(2/5)= 0.971
根据数据统计,outlook取值分别为
sunny,overcast,rainy的概率分别为: 5/14, 4/14, 5/14
熵值计算: H(D|A1) =5/14* 0.971 + 4/14 * 0 + 5/14 * 0.971 = 0.693
信息增益:系统的熵值从原始的0.940下降到了0.693,
增益为g(D,A1)=H(D)−H(D|A1)= 0.940- 0.693=0.247
同样的方式可以计算出其他特征的信息增益,那么我们选择最大的那个特征就可以啦,相当于是遍历了一遍特征,找出来了大当家,然后再其余的特征中继续通过信息增益查找下一个根节点!
g(D,A1)=gain(outlook)=0.247
g(D,A2)=gain(temperature)=0.029
g(D,A3)=gain(humidity)=0.152
g(D,A4)=gain(windy)=0.048
总结
总结一下上面的计算过程,
假设训练数据集为 D,∣D∣表示其大小.设有 K 个分类 C1,C2,…,Ck,∣Ck∣ 为类 Ck 的大小,即样本个数, ∑Kk=1∣Ck∣=∣D∣ .设特征 A 有 n 个不同的取值 {a1,a2,…,an},根据特征 A 的取值将 D 划分成 n 个子集 D1,D2,…,Dn,∣Di∣ 为 Di 的大小, ∑ni=1∣Di∣ .记子集 Di中属于类 Ck的样本集合为 Dik, ∣Dik∣ 为 Dik 的大小.
于是信息增益的算法如下:
计算数据集 D 的经验熵 H(D):
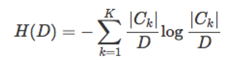
计算特征A对数据集 D 的经验条件熵:

具体为:
1.若D中所有实例都属于同一类 Ck,则 T 为单节点树,并将类 Ck作为该节点的类标记,返回T.
2.若A=Φ,则T为单节点树,并将D中实例最大的类Ck作为该节点的类标记,返回T.
3.否则,按照信息增益的算法,计算每个特征对D的信息增益,取信息增益最大的特征 Ag.
4.如果 Ag<ε,则置 T 为单节点树,并将D中实例最大的类Ck作为该节点的类标记,返回T.
5.否则,对Ag的每一可能值 ai,依Ag=ai将D分成若干非空子集Di,将Di中实例最大的类作为标记,构建子节点,由节点和子节点构成树T,返回T.
6.对第 i 个子节点,以Di为训练集,以A−{Ag} 为特征集,递归地调用步骤1到步骤5,得到子树 Ti,返回Ti.
ID3缺点:
ID3采用的信息增益度量存在一个内在偏置,它优先选择有较多属性值的Feature,因为属性值多的Feature会有相对较大的信息增益。
(信息增益反映的给定一个条件以后不确定性减少的程度,必然是分得越细的数据集确定性更高,也就是条件熵越小,信息增益越大).
为了克服ID3的缺点,引进C4.5算法
三、C4.5
C4.5算法是数据挖掘十大算法之一,它是对ID3算法的改进
避免ID3不足的一个度量就是不用信息增益来选择Feature,而是用信息增益比率(gainratio),增益比率通过引入一个被称作分裂信息(Splitinformation)的项来惩罚取值较多的Feature,分裂信息用来衡量Feature分裂数据的广度和均匀性:
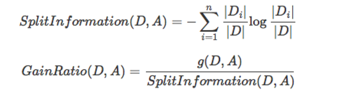
但是当某个Di的大小跟D的大小接近的时候,SplitInformation(D,A)→0,GainRatio(D,A)→∞,为了避免这样的属性,可以采用启发式的思路,只对那些信息增益比较高的属性才应用信息增益比率.
还是之前的例子,根据公式可以直接求解
SplitInformation(outlook)=SplitInformation(D,A1)
=-5/14*log(5/14)-5/14*log(5/14)-5/14*log(5/14)=1.58
g(D,A1)=0.247(ID3算法结果,直接引用)
GainRatio(D,A1)=g(D,A1) /SplitInformation(D,A1)
=0.247/1.58= 0.16
同理可以求得其他自变量的增益率,
选取最大的信息增益率作为分裂属性。
相比ID3,C4.5还能处理连续属性值,具体步骤为:
•把需要处理的样本(对应根节点)或样本子集(对应子树)按照连续变量的大小从小到大进行排序。
•假设该属性对应的不同的属性值一共有N个,那么总共有N−1个可能的候选分割阈值点,每个候选的分割阈值点的值为上述排序后的属性值中两两前后连续元素的中点,根据这个分割点把原来连续的属性分成bool属性.实际上可以不用检查所有N−1个分割点。
• 用信息增益比率选择最佳划分。
C4.5算法优缺点分析
优点:
(1)通过信息增益率选择分裂属性,克服了ID3算法中通过信息增益倾向于选择拥有多个属性值的属性作为分裂属性的不足;
(2)能够处理离散型和连续型的属性类型,即将连续型的属性进行离散化处理;
(3)构造决策树之后进行剪枝操作;
(4)能够处理具有缺失属性值的训练数据。
缺点:
(1)算法的计算效率较低,特别是针对含有连续属性值的训练样本时表现的尤为突出。
(2)算法在选择分裂属性时没有考虑到条件属性间的相关性,只计算数据集中每一个条件属性与决策属性之间的期望信息,有可能影响到属性选择的正确性。