4.5 C4.5算法
4.5.1 C4.5算法的实现
前面讲解了决策树最基本的算法ID3,接下来将要讲解的是ID3的改进版本,C4.5是Quinlan在1993年提出的。
C45算法和ID3类似,只是不再以以信息增益作为划分训练数据集的特征,而是以信息增益比作为划前文也讲过了,笔者还是把不同的部分贴出来吧。其余的都一样。
信息增益比(information gain ratio)
特征 对训练数据集 的信息增益比 定义为其信息增益 与训练数据集 关于特征 的值的熵 之比,即
其中,
是特征
取值的个数。
用信息增益比来选择特征的算法称为C4.5算法。
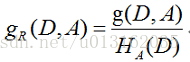
Python代码如下。
"""
函数说明:信息增益比
Parameters:
dataSet - 数据集
baseEntropy - 数据集的信息熵
i - 特征维度i
Returns:
增益比
"""
def calcInformationGainRatio(dataSet, baseEntropy,i):
return calcInformationGain(dataSet,baseEntropy,i) / baseEntropy
"""
函数说明:选择最好的数据集划分方式--C45
Parameters:
dataSet:数据集
Returns:
最优结果
"""
def chooseBestFeatureToSplitByC45(dataSet):
# 最后一列yes分类标签,不属于特征变量
numFeatures = len(dataSet[0]) - 1
baseEntropy = calcShannonEnt(dataSet)
bestInfoGainRate = 0.0
bestFeature = -1
for i in range(numFeatures): # 遍历所有维度特征
infoGainRate = calcInformationGainRatio(dataSet, baseEntropy, i) # 计算信息增益比
if (infoGainRate > bestInfoGainRate): # 选择最大的信息增益比
bestInfoGainRate = infoGainRate
bestFeature = i
return bestFeature # 返回最佳特征对应的维度
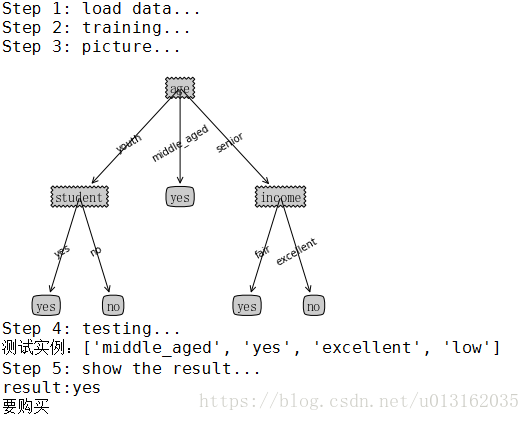
结果如下所示。
【完整代码参考附件4.DT-ID3_C45-buys_computer_Classifty\ DT-ID3_C45-buys_computer_Classifty.py】
【注】笔者为了区分ID3和C45 所以代码中集成两个算法,请注意和前文的第一个实例做比较,读者朋友请自行比较。
算法(C4.5算法)
输入:训练数据集
,特征集
,阈值
;
输出:决策树
;
- step.1初始化信息增益的阈值
- step.2判断样本 是否为同一类输出 ,若 为单节点树 ,则将类 作为该节点的类标记,返回 ;
- step.3判断特征集 是否为空,如果是空则返回单节点树 ,标记类别为样本中输出类别 实例数最多的类别返回 ;
- step.4计算 中的各个特征(一共 个)对输出 的信息增益比,选择信息增益最大比的特征 ;
- step.5如果 的信息增益小于阈值 ,则返回单节点树 ,标记类别为样本中输出类别 实例数最多的类别 ,返回 。
- step.6否则,按特征 的不同取值 将对应的样本输出 分成若干个非空子集 ,将 中实例数的做大的类作为标记,构建子节点,由节点及其子节点构成数 ,返回 。
- step.7对第 个子节点,以 为训练集,以 { }为特征集,递归地调用步(2)~步(6),得到子树 ,返回 。
【注】C4.5不同之处就是使用增益比来得到选择特征。
4.5.2 C4.5算法的有优缺点
C4.5算法用信息增益率来选择属性,继承了ID3算法的优点。并在以下几方面对ID3算法进行了改进:
- 克服了用信息增益选择属性时偏向选择取值多的属性的不足;
- 在树构造过程中进行剪枝;
- 能够完成对连续属性的离散化处理;
- 能够对不完整数据进行处理。
C4.5算法产生的分类规则易于理解、准确率较高;但效率低,因树构造过程中,需要对数据集进行多次的顺序扫描和排序。也是因为必须多次数据集扫描,C4.5只适合于能够驻留于内存的数据集。在实现过程中,C4.5算法在结构与递归上与ID3完全相同,区别只在于选取决决策特征时的决策依据不同,二者都有贪心性质:即通过局部最优构造全局最优。
C4.5虽然改进或者改善了ID3算法的几个主要的问题,仍然有优化的空间。
- 由于决策树算法非常容易过拟合,因此对于生成的决策树必须要进行剪枝。剪枝的算法有非常多,C4.5的剪枝方法有优化的空间。思路主要是两种,一种是预剪枝,即在生成决策树的时候就决定是否剪枝。另一个是后剪枝,即先生成决策树,再通过交叉验证来剪枝。后面在下篇讲CART树的时候我们会专门讲决策树的减枝思路,主要采用的是后剪枝加上交叉验证选择最合适的决策树。
- C4.5生成的是多叉树,即一个父节点可以有多个节点。很多时候,在计算机中二叉树模型会比多叉树运算效率高。如果采用二叉树,可以提高效率。
- C4.5只能用于分类,如果能将决策树用于回归的话可以扩大它的使用范围。
- C4.5由于使用了熵模型,里面有大量的耗时的对数运算,如果是连续值还有大量的排序运算。如果能够加以模型简化可以减少运算强度但又不牺牲太多准确性的话,那就更好了。
参考文档:
英文文档:http://scikit-learn.org/stable/modules/tree.html
中文文档:http://sklearn.apachecn.org/cn/0.19.0/modules/tree.html
参考文献:
[1]《机器学习》周志华著
[2]《统计学习方法》李航著
[3]L. Breiman, J. Friedman, R. Olshen, and C. Stone. Classification and Regression Trees. Wadsworth, Belmont, CA, 1984.
[4] Quinlan, JR. (1986) Induction of Decision Trees. Machine Learning, 1, 81-106.
[5]J.R. Quinlan. C4. 5: programs for machine learning. Morgan Kaufmann, 1993.
[6]T. Hastie, R. Tibshirani and J. Friedman. Elements of Statistical Learning, Springer, 2009.
本章参考附件
点击进入