C4.5算法是机器学习算法中的一种分类决策树算法,其核心算法是ID3算法. C4.5算法继承了ID3算法的优点,并在以下几方面对ID3算法进行了改进:
1)用信息增益率来选择属性,克服了用信息增益选择属性时偏向选择取值多的属性的不足;
2)在树构造过程中进行剪枝;
3)能够完成对连续属性的离散化处理;
4)能够对不完整数据进行处理。
C4.5算法有如下优点:产生的分类规则易于理解,准确率较高。其缺点是:在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效。
决策树分类算法的一般流程如下:一开始,所有的实例均位于根节点,所有参数的取值均离散化;根据启发规则选择一个参数,根据参数取值的不同对实例集进行分割;对分割后得到的节点进行同样的启发式参数选择分割过程,如此往复,直到(a)分割得到的实例集合属于同一类;(b)参数用完,以子集中绝大多数的实例类别作为该叶节点的类别。
核心问题:参数选择规则 在每一个节点进行参数选择时,由于有众多的选项,需要一个选择规则。基本的原则是使最后构造出的决策树规模最小。基于这个基本原则,我们启发式地定义规则为使分割后得到的子节点纯度最大。于是参数选择规则问题就转化为了纯度定义的问题。 我们利用熵(Entropy)的概念去描述“不纯度”,熵值越大,说明这个节点的纯度越低:当节点的类别均匀分布时,熵值为1;当只包含一类时,熵值为0.熵的计算公式如下图,以2为底的概率对数与概率乘积之和的相反数。
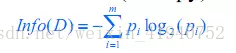
基于熵的概念,我们可以得到参数选择的第一个规则:信息增益(InfoGain).信息增益的定义是分裂前的节点熵减去分裂后子节点熵的加权和,即不纯度的减少量,也就是纯度的增加量。参数选择的规则是:选择使信息增益最大的参数分割该节点。信息增益计算的算例如下图。
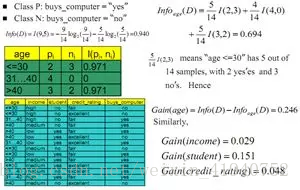
信息增益存在的问题时:总是倾向于选择包含多取值的参数,因为参数的取值越多,其分割后的子节点纯度可能越高。为了避免这个问题,我们引入了增益比例(GainRatio)的选择指标,其定义如下图所示。

增益比例存在的问题是:倾向于选择分割不均匀的分裂方法,举例而言,即一个拆分若分为两个节点,一个节点特别多的实例,一个节点特别少的实例,那么这种拆分有利于被选择。 为了克服信息增益和增益比例各自的问题,标准的解决方案如下:首先利用信息增益概念,计算每一个参数分割的信息增益,获得平均信息增益;选出信息增益大于平均值的所有参数集合,对该集合计算增益比例,选择其中增益比例最大的参数进行决策树分裂。
上面介绍的是基于熵概念的参数选择规则,另一种流行的规则称为基尼指数(GiniIndex),其定义如下图。基尼系数在节点类别分布均匀时取最大值1-1/n,在只包含一个类别时取最小值0.所以与熵类似,也是一个描述不纯度的指标。

基于基尼系数的规则是:选择不纯度减少量(Reduction in impurity)最大的参数。不纯度减少量是分割前的Giniindex减去分割后的Gini index。基尼系数的特点与信息增益的特点类似。
过度拟合问题(Overfitting)
过度拟合问题是对训练数据完全拟合的决策树对新数据的预测能力较低。为了解决这个问题,有两种解决方法。第一种方法是前剪枝(prepruning),即事先设定一个分裂阈值,若分裂得到的信息增益不大于这个阈值,则停止分裂。第二种方法是后剪枝(postpruning),首先生成与训练集完全拟合的决策树,然后自下而上地逐层剪枝,如果一个节点的子节点被删除后,决策树的准确度没有降低,那么就将该节点设置为叶节点(基于的原则是Occam剪刀:具有相似效果的两个模型选择较简单的那个)。
代表算法 这里介绍两个算法,一个是RainForest,其主要的贡献是引入了一个称为AVC的数据结构,其示意图如下。主要的作用是加速参数选择过程的计算。

另一个算法称为BOAT,其采用了称为bootstrap的统计技术对数据集进行分割,在分割的子数据集上分别构造决策树,再基于这些决策树构造一个新的决策树,文章证明这棵新树与基于全局数据集构造的决策树非常相近。这种方法的主要优势在于支持增量更新。