一 概述
Spark Streaming底层的数据处理单位是:DStream ; 主要是处理流式数据(数据一直不停的在向Spark程序发送),这里可以结合 Spark Core 和 Spark SQL 来处理数据,如果来源数据是非结构化的数据,那么我们这里就可以结合 Spark Core 来处理,如果数据为结构化的数据,那么我们这里就可以结合Spark SQL 来进行处理。
特性
- 易用 可以像编写离线批处理一样去开发流式的处理程序,并且可以使用java/scala/Python语言进行代码开发
- 容错 SparkStreaming在没有额外代码和配置的情况下可以恢复丢失的工作
- 易整合到Spark体系
和storm的区别
- Storm处理的是每次传入的一个事件,Spark Streaming是处理某个时间段窗口内的事件流
- 一般Storm的时延性比spark streaming要低,原因是Spark Streaming是小的批处理,通过间隔时长生成批次,一个批次触发一次计算,比如我在程序里面设置间隔时长为5秒,那就是五秒接收到的数据触发一次计算,Storm是实时处理,来一条数据,触发一次计算,所以可以称spark streaming为流式计算,Storm 为实时计算,阿里的JStorm通过实现Trident,也支持小的批处理计算
- 吞吐量 :Storm的吞吐量要略差于Spark Streaming,原因一是Storm从spout组件接收源数据,通过发射器发送到bolt,bolt对接收到的数据进行处理,处理完以后,写入到外部存储系统中或者发送到下个bolt进行再处理,所以storm是移动数据,不是移动计算;Spark Streaming获取Task要计算的数据在哪个节点上,然后TaskScheduler把task发送到对应节点上进行数据处理,所以Spark Streaming是移动计算不是移动数据,移动计算也是当前计算引擎的主流设计思想;原因二大家很容易看出来,一个是批处理,一个是实时计算,批处理的吞吐量一般要高于实时触发的计算
- storm是acker(ack/fail消息确认机制)确认机制确保一个tuple被完全处理,Spark Streaming是通过存储RDD转化逻辑进行容错,也就是如果数据从A数据集到B数据集计算错误了,由于存储的有A到B的计算逻辑,所以可以从A重新计算生成B,容错机制不一样,暂时无所谓好坏
- Spark Streaming有一点是Storm绝对比不上的,那就是spark提供了一个统一的解决方案,在一个集群里面可以进行离线计算,流式计算,图计算,机器学习等,而storm集群只能单纯的进行实时计算
二 基本工作原理
接收实时输入数据流,然后将数据拆分成多个 batch,比如每收集1秒的数据封装为一个batch,然后将每个batch交给Spark的计算引擎进行处理,最后会生产出一个结果数据流,其中的数据,也是由一个一个的batch所组成的。

三 DStream
DStream,英文全称为 Discretized Stream,中文翻译为“离散流”,它代表了一个持续不断的数据流。DStream可以通过输入数据源来创建,比如Kafka、Flume和Kinesis;也可以通过对其他DStream应用高阶函数来创建,比如map、reduce、join、window。
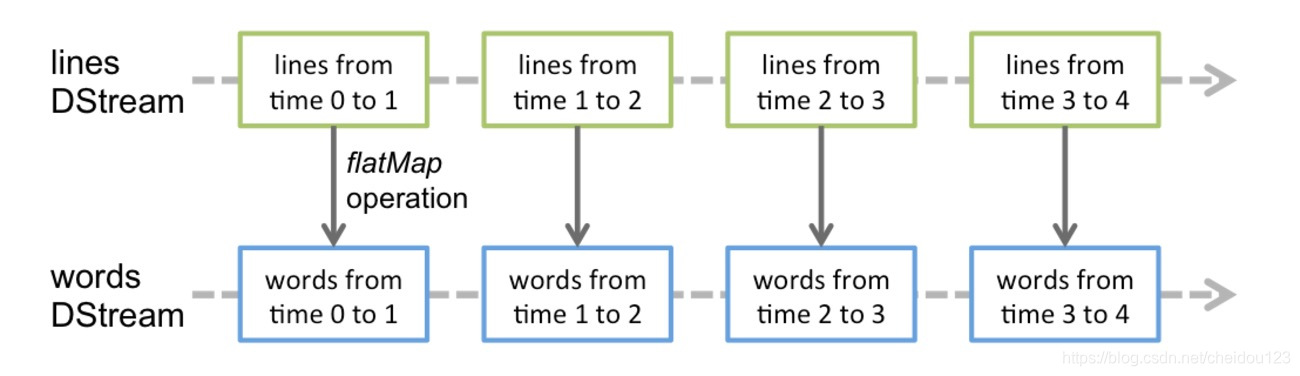
对DStream应用的算子,比如map,其实在底层会被翻译为对DStream中每个RDD的操作。比如对一个DStream执行一个map操作,会产生一个新的DStream。但是,在底层,其实其原理为,对输入DStream中每个时间段的RDD,都应用一遍map操作,然后生成的新的RDD,即作为新的DStream中的那个时间段的一个RDD。底层的RDD的transformation操作,其实,还是由Spark Core的计算引擎来实现的。Spark Streaming对Spark Core进行了一层封装,隐藏了细节,然后对开发人员提供了方便易用的高层次的API。
四 Kafka的Receiver和Direct方式
- 基于Receiver的方式
这种方式使用Receiver来获取数据,如果要启用高可靠机制,让数据零丢失,就必须启用Spark Streaming的预写日志机制,但是预写日志效率低下。而且无法保证数据被处理一次且仅一次。 - 基于Direct方式
这种新的不基于Receiver的直接方式,是在Spark 1.3中引入的,从而能够确保更加健壮的机制。不需要开启WAL机制,只要Kafka中作了数据的复制,那么就可以通过Kafka的副本进行恢复。可以保证数据是消费一次且仅消费一次
五 缓存与持久化
与RDD类似,Spark Streaming也可以让开发人员手动控制,将数据流中的数据持久化到内存中。对DStream调用persist()方法,就可以让Spark Streaming自动将该数据流中的所有产生的RDD,都持久化到内存中。如果要对一个DStream多次执行操作,那么,对DStream持久化是非常有用的。因为多次操作,可以共享使用内存中的一份缓存数据。
对于基于窗口的操作,比如reduceByWindow、reduceByKeyAndWindow,以及基于状态的操作,比如updateStateByKey,默认就隐式开启了持久化机制。即Spark Streaming默认就会将上述操作产生的Dstream中的数据,缓存到内存中,不需要开发人员手动调用persist()方法。
对于通过网络接收数据的输入流,比如socket、Kafka、Flume等,默认的持久化级别,是将数据复制一份,以便于容错。相当于是MEMORY_ONLY_SER_2。
与RDD不同的是,默认的持久化级别,统一都是要序列化的。
六 Checkpoint
将RDD checkpoint到可靠的存储系统上,会耗费很多性能。当RDD被checkpoint时,会导致这些batch的处理时间增加。因此,checkpoint的间隔,需要谨慎的设置。对于那些间隔很多的batch,比如1秒,如果还要执行checkpoint操作,则会大幅度削减吞吐量。而另外一方面,如果checkpoint操作执行的太不频繁,那就会导致RDD的lineage变长,又会有失败恢复时间过长的风险。
对于那些要求checkpoint的有状态的transformation操作,默认的checkpoint间隔通常是batch间隔的数倍,至少是10秒。使用DStream的checkpoint()方法,可以设置这个DStream的checkpoint的间隔时长。通常来说,将checkpoint间隔设置为窗口操作的滑动间隔的5~10倍,是个不错的选择。