参考 https://www.cnblogs.com/ourroad/p/4891648.html
https://blog.csdn.net/hjkl950217/article/details/78039691
在redis里,哈希又是另一种键值对结构。redis本身就是key-value型,哈希结构相当于在value里又套了一层kv型数据。哈希和C#里的字典,java里的map结构是一样的。
Redis一个重要的基础数据结构:dict。
-
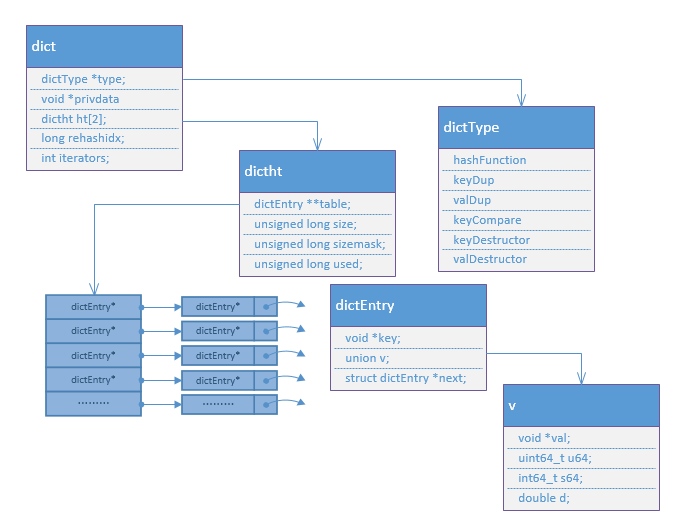
dict是一个用于维护key和value映射关系的数据结构,与很多语言中的Map或dictionary类似。Redis的一个database中所有key到value的映射,就是使用一个dict来维护的。不过,这只是它在Redis中的一个用途而已,它在Redis中被使用的地方还有很多。比如,一个Redis hash结构,当它的field较多时,便会采用dict来存储。再比如,Redis配合使用dict和skiplist来共同维护一个sorted set
-
dict本质上是为了解决算法中的查找问题(Searching),一般查找问题的解法分为两个大类:一个是基于各种平衡树,一个是基于哈希表。我们平常使用的各种Map或dictionary,大都是基于哈希表实现的。在不要求数据有序存储,且能保持较低的哈希值冲突概率的前提下,基于哈希表的查找性能能做到非常高效,接近O(1),而且实现简单。
-
dict也是一个基于哈希表的算法。和传统的哈希算法类似,它采用某个哈希函数从key计算得到在哈希表中的位置,采用拉链法解决冲突,并在装载因子(load factor)超过预定值时自动扩展内存,引发重哈希(rehashing)。Redis的dict实现最显著的一个特点,就在于它的重哈希。它采用了一种称为增量式重哈希(incremental rehashing)的方法,在需要扩展内存时避免一次性对所有key进行重哈希,而是将重哈希操作分散到对于dict的各个增删改查的操作中去。这种方法能做到每次只对一小部分key进行重哈希,而每次重哈希之间不影响dict的操作。dict之所以这样设计,是为了避免重哈希期间单个请求的响应时间剧烈增加,这与前面提到的“快速响应时间”的设计原则是相符的。
内部编码
有两种:
ziplist:
内部更加紧凑。
当键的个数小于hash-max-ziplist-entries(默认512)的配置时
同时所有值小于hash-max-ziplist-value(默认64)的配置时
才会使用ziplist
hashtable:
当不能使用ziplist时,就会使用这个结构,因为不满足上面两个条件时,ziplist的读写效率会降低。而hashtable的读写时间复杂度为O(1)。