一 哈希对象简介
- 几乎所有的编程语言都提供了哈希(hash)类型,它们的叫法可能是哈希、字典、关联数组;
- 哈希又称散列
在Redis中,哈希类型是指键值本身又是一个键值对结构,形如value={
{field1,value1},…{fieldN,valueN}},Redis键值对和哈希类型二者的关系可以下图表示

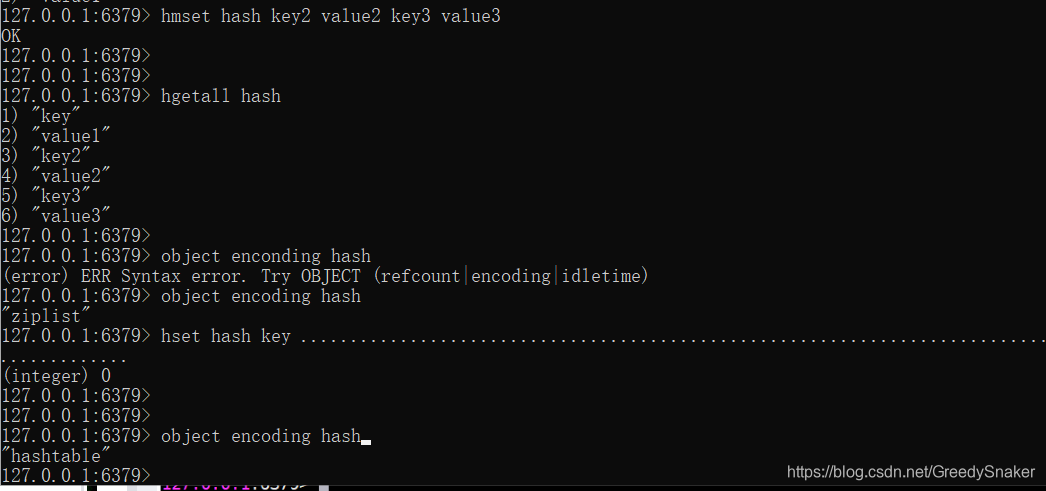
二 常用命令
命令 最好亲自去敲一下。
三、内部编码
哈希类型的内部编码有两种:
- ziplist(压缩列表):当哈希类型元素个数小于hash-max-ziplist-entries 配置(默认512个)、同时所有值都小于hash-max-ziplist-value配置(默认64 字节)时,Redis会使用ziplist作为哈希的内部实现,ziplist使用更加紧凑的结构实现多个元素的连续存储,所以在节省内存方面比hashtable更加优秀
- hashtable(哈希表):当哈希类型无法满足ziplist的条件时,Redis会使用hashtable作为哈希的内部实现,因为此时ziplist的读写效率会下降,而 hashtable的读写时间复杂度为O(1)
具体区别看 两种编码的理解
四 数据结构
dictht是一个散列表结构,使用拉链法保存哈希冲突的dictEntry。
typedef struct dictht{
//哈希表数组
dictEntry **table;
//哈希表大小
unsigned long size;
//哈希表大小掩码,用于计算索引值
unsigned long sizemask;
//该哈希表已有节点的数量
unsigned long used;
}
typedef struct dictEntry{
//键
void *key;
//值
union{
void *val;
uint64_tu64;
int64_ts64;
}
struct dictEntry *next;
}
Redis的字典dict中包含两个哈希表dictht,这是为了方便进行rehash操作。在扩容时,将其中一个dictht上的键值对rehash到另一个dictht上面,完成之后释放空间并交换两个dictht的角色。
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
rehash操作并不是一次性完成、而是采用渐进式方式,目的是为了避免一次性执行过多的rehash操作给服务器带来负担。
渐进式rehash通过记录dict的rehashidx完成,它从0开始,然后没执行一次rehash例如在一次 rehash 中,要把 dict[0] rehash 到 dict[1],这一次会把 dict[0] 上 table[rehashidx] 的键值对 rehash 到 dict[1] 上,dict[0] 的 table[rehashidx] 指向 null,并令 rehashidx++。
在 rehash 期间,每次对字典执行添加、删除、查找或者更新操作时,都会执行一次渐进式 rehash。采用渐进式rehash会导致字典中的数据分散在两个dictht中,因此对字典的操作也会在两个哈希表上进行。例如查找时,先从ht[0]查找,没有再查找ht[1],添加时直接添加到ht[1]中。