数据结构学习之Hash
一、Hash定义:
可译作“散列”,即把任意长度的输入(预映射),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,即散列值的空间常小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来唯一的确定输入值。
二、常用Hash函数:
- 直接取余法:
- 乘法取整法:取关键字被某个不大于散列表表长m的数p除后所得的余数为散列地址。即H(key) = key MOD p , p<=m。
- 平方取中法:取关键字平方后的中间几位作为散列地址
hash 本质是一个函数,该函数实现的是一种算法,通过一系列的算法来得到一个hash值。
Hash表:通过hash算法得到的hash值就在这张表中。即hash表是所有hash值组成的。
三、HashCode:
hashcode 是通过hash函数得来的,即hashcode就是在hash表中对应的位置。hashcode代表的是对象的地址,说的是对象在hash表中的位置,物理地址说的是对象存放在内存中的地址。
那么对象如何得到hashCode呢?通过对象的内部地址(物理地址)转换成一个整数,然后该整数通过hash函数的算法就得到了hashcode。
四、HashCode的意义:
意义:主要是为了查找的快捷性,hashcode是用来在散列存储结构中确定对象的存储地址的。
思考:为甚么查找更快呢?
栗子:现有一个能存放1000个数的内存,要在其中放1000个不一样的数字,最笨的办法是存放一个就遍历一遍,看是否有相同的数字,当存到900个数,开始存901个数时,需要和900个数比较,效率太低了。但是使用hashcode记录对象的位置会快很多,假设hash表中有9个位置,存第一个数时,hashcode为1,就放在hash表为1的位置,hashcod为2就放在2的位置,等等,存到100个数的时候,假设hash表为2的位置有了20个数据,现在存101个数据的时候,得到的hashcode为2,那么就是20个数和他的hascode相同,只需要和这个20个数比较(equals),这样比较的次数就少了。
五、equals方法和hashcode的关系:
思考:如何判断两个对象是否相等?
通过上面的栗子,可知,先通过hashcode来比较,如果hashcode一样,那么就用equals方法来比较两个对象是否相当。
通过上面栗子,能得到2个结论:
1.如果2个对象equals相当等,那么这两个对象的hashcode一定相同;
2.两个对象的hashcode相同,不代表2个对象就相同,只能说明这2个对象在散列存储结构中,存放在同一个位置,即hash表的同一个位置上。
六、为什么重写equals方法时,建议也重写hashcode方法?
栗子: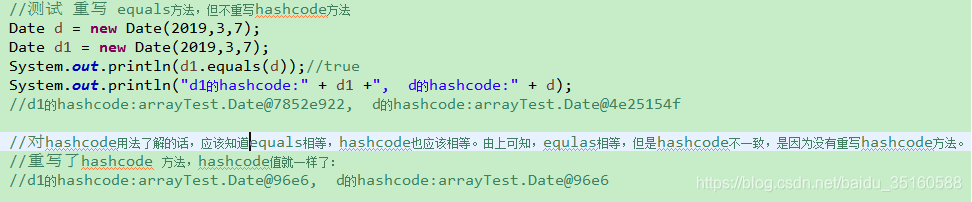
七、Hash表的特点
数组的查询很快,时间复杂度是o(1),但是增删很慢o(n),因为要维护索引;
链表的存储方式在内存上是不连续的,每个元素都保存这个下个元素的内存地址,通过这个地址找到下个元素,所以查询速度慢,时间复杂度是o(n),在插入和删除是o(1)。
思考:如果想要一个查询很快,删除也很快的数据结构,该怎么办呢?
此时Hash(哈希表)就应运而生了,通过哈希函数计算出键在哈希表中的位置,称为hash地址,然后将值存到这个哈希地址上,通过键就可以直接操作到值,故增删查都很快,即o(1)。
既然键是通过hash函数算出存储位置的,那么哈希函数的好坏直接影响到哈希表的操作效率,例如会出现浪费存储空间、大量冲突(即不同的键计算出的存储位置一样)。
Hash冲突是不可以避免的,常用下面两种解决哈希冲突:
1.链地址法(拉链法)
采用数组和链表结合的方法,将哈希表中每个哈希地址建立一个线性表,将哈希地址相同的数据结构存在线性表中,将链表的指针保存在数组中,哈希地址、键、值等信息保存在链表节点中。
2.开放定址法(线性探测法):
基本思想:将哈希表T[0…m-1]看成一个循环向量,若初始探测地址为d,则最长探测地址为d,d+i,d+2i,…m-1。i为自定义常数。
弊端:容易产生堆聚现象。即哈希表中的数据连成一片,在加入新元素就容易产生哈希冲突。
3.两者比较:
拉链法处理冲突简单,无堆聚现象,插入和删除简单,适合经常插入删除操作。
线性探测法:为了避免冲突,要求负载因子较小,当节点规模较大,浪费空间,在删除节点是不能简单将节点所在空间置为null,否则会断掉在它之后节点的查找路径。故只能做逻辑删除,即做删除标记。