说明:
- 我们所说的string、hash、list、set、zset是Redis对外提供的数据结构名称,而对于Redis内部来说,每个对外的数据结构会根据数据的数量与单个元素的最大值,内部选用不同的内部实现。这样做的好处是选择合适的存储结构来提高内存利用率与执行效率。另外向Redis的使用者屏蔽内部细节,当有一种新的更合适的数据结构时,在内部替换对Redis的使用者是透明的。
外部数据结构与内部数据结构之间的对应关系:
string:int;embstr;row
hash: ziplist;hashtable
list: ziplist;linkedlist;quicklist
set: intset;hashtable
zset: ziplist;skiplist+hashtable
- 无论使用string、hash、list、set、zset中的哪种,key都是string,所指的string、hash、list、set、zset指的是value。
一、String:
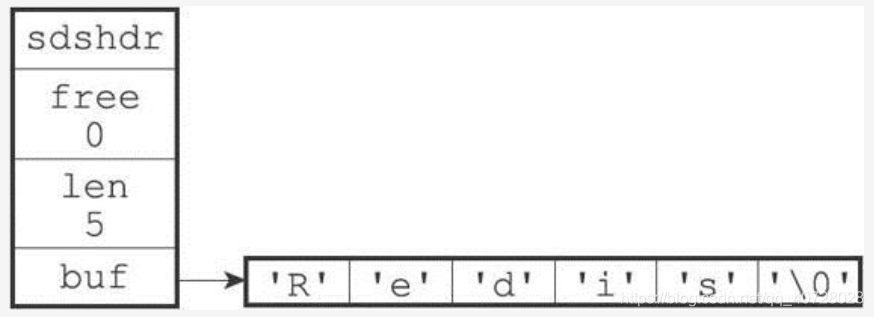
为什么使用SDS,而不是C语言原生的字符串表示方式:
效率、安全、功能 三方面的考虑。
-
c的字符串获取长度O(n),SDS,O(1)。(效率)
-
C语言的字符拼接函数
strcat(char * s1,char * s2)如果s1分配的空间不能容下s2,那么s2的后半截就可能覆盖掉s1右边界以外的部分。 而SDS提供的拼接函数sdscat在拼接前,会先看free记录的值是否能够容下s2,不能的话,会先将字符数组的容量扩充至2倍的s1+s2长度,然后进行拼接,也就是说len的值为s1+s2的长度和,并且free也会是这个值。(安全) -
C语言字符串在修改时会存在内存重分配问题: 比如“redis”拼接上“nice”时,需要重分配内存大小为10(’\0’),不然就会出现上面的数据覆盖问题。 另外在截取字符串后,也会进行内存重分配来回收不用的内存空间,来防止内存泄漏。
而SDS,从上面拼接操作可以看到,会多扩容一倍容量来减少内存重分配。另外在执行完截取操作后,也不会立即回收截取后的内存空间,而是将截取掉的内存空间长度记录在free字段中,便于后面再次进行复用。(效率+安全) -
C语言字符串由于以’\0’作为结尾标识的特性,C语言字符串不能够用来存储字符串中间含’\0’的字符串。也就是说C语言字符串的存储是不安全的,可能出现存储的时候与取出的时候数据被改变的现象。
SDS使用len属性值来判断是否结束,所以说SDS是二进制安全的。
二、linkedlist:
linkedlist就是个链表的实现,没啥好说的。



三、Hashtable:
Redis数据库本身就是一个hash,即无论是string、hash、list、set、zset都是以K-V的形式存储在hash结构中的。
另外hash、set当数据量或者数据元素的大小超出限制时,也是使用的是hash结构。
hash结构:


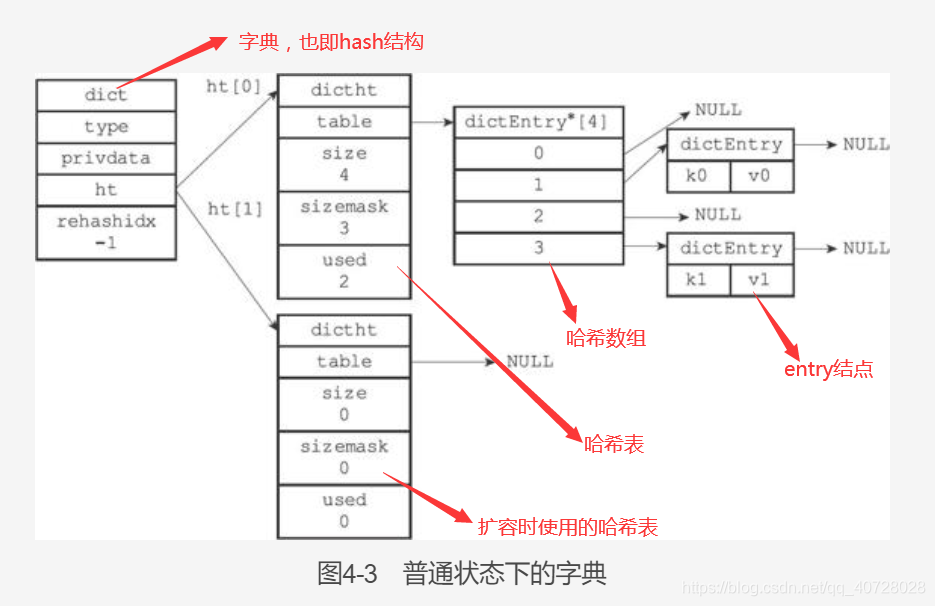
一个hash结构,包含大小为2的一个哈希表数组ht,ht[0]用来存储实际的K-V对,ht[1]用来进行rehash,当rehashindex为-1时表示目前没有在进行rehash。
注意现在ht[1]这个哈希表对应的哈希数组是空的。
哈希算法:
与hashmap基本一致:
先通过hash函数(key)计算出key的hash值,然后将hash值与哈希表中的sizemark字段(该字段值为哈希数组长度-1)进行&操作,计算出应该存储在哈希数组上的下标index。
解决哈希冲突采用的也是链地址法,并使用头插(书中说的是直接在O(1)时间复杂度里直接头插在头部,未进行遍历进行替换操作)。
rehash:
Redis的rehash不仅会在数量增大到不满足负载因子时进行,还会在数量减小到不满足负载因子时进行。

触发rehash的时机:
- 扩增情景:
当未在进行GBSAVE命令或者是BGREWRITEAOF命令时,当装载因子大于等于1 时;
当正在进行BGSAVE命令或者是GBREWRITEAOF命令时,当装载因子大于等于5时。
装载因子计算方法:used/size 。(used是会大于size的,因为哈希数组下标会放置一个链表,即存在多个结点)
之所以执行BGSAVE命令或者是GBREWRITEAOF命令时的装载因子更大,是因为这2个操作会fork一个子进程,采用copy-on-write技术,即父子进程共享一个内存数据,当主进程某个数据发生变化时,会复制一份给主进程进行修改。此时提高装载因子就是为了避免在此期间进行rehash带来的不必要的内存与CPU消耗。
- 收缩情景:
当装载因子达到0.1时,会触发收缩。
渐进式rehash:
上面提到到将ht[0]的数据在rehash到ht[1]中,并不是一次性执行完的。

渐进式rehash过程:
四、skiplist:
skiplist,即跳表。用来维护一组有序的数据,增删改查的时间复杂度都为O(lgN)。
与红黑树的性能差不多,这里使用跳表实现zset,有2个原因:一是跳表比红黑树实现简单很多;另一个比较重要的原因是zset有范围查询,所以使用跳表效率更高。
实现:
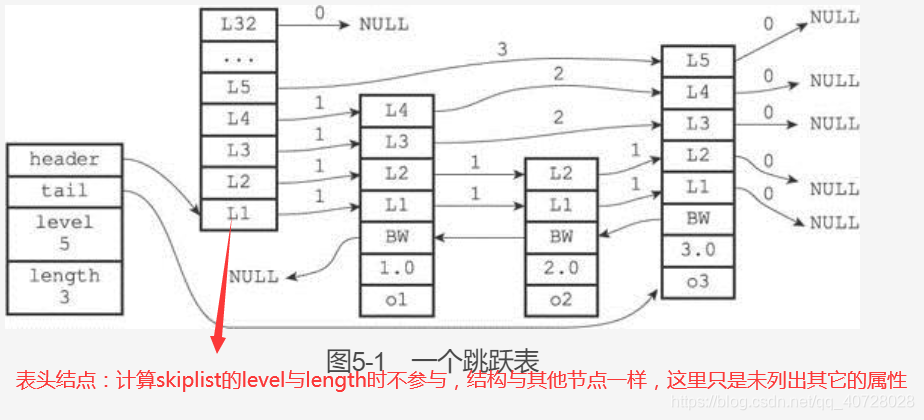

主要是看zskiplistNode的实现:


- 每个Level结点不仅记录了指向下一个同层的指针,还记录同层之间的跨度span,span用于计算某个成员的排名rank。在查找某个元素的过程中,累加走过的跨度就可以计算出查找元素的rank。
- zskiplistNode结点的obj指向一个SDS对象,也就是成员的名称。
- zskiplistNode结点的成员名不能重复,但score可以相同,对于score相同的成员,按照成员名的字典序进行排序。
五、intset:





六、ziplist:
当hash、list、zset三种结构的数据量较小时,采用的都是ziplist来存储。
压缩列表的构成:

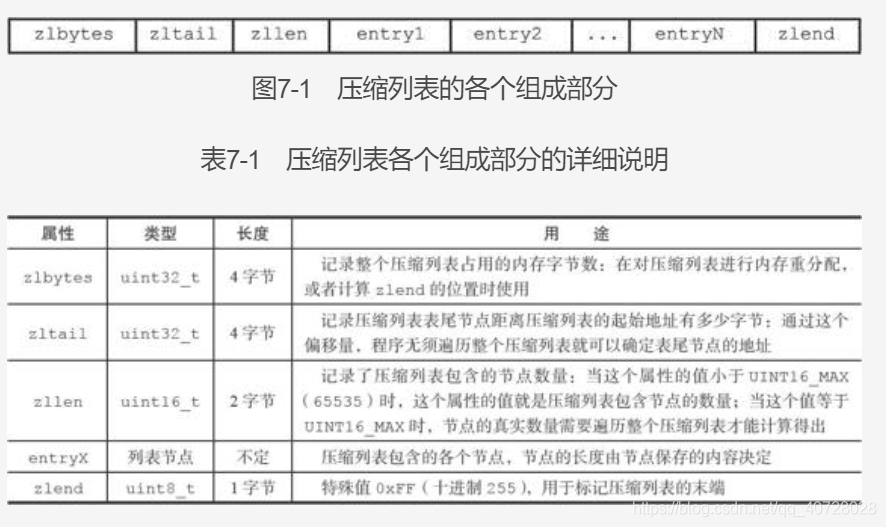
压缩列表中每个结点的组成:




假设已经有3个字节长度为250-253的压缩结点,现在添加一个字节长度大于254的结点在这3个结点的前面,此时后面的结点依次都需要重新分配内存。

七、值对象:

基本介绍看:redisObject的介绍
1. string对象:
string有int, embstr, row三种实现。
当设置的内容为一个可以用long表示的整形数值时采用int:
(浮点数用embstr或者row表示)

当设置的内容为字符串且长度大于32时,采用row,也就是SDS:

当为字符串且长度不大于32时,采用embstr:

2. list对象:
list有ziplist,linkedlist,quicklist(结合了前2种的优点)三种实现。
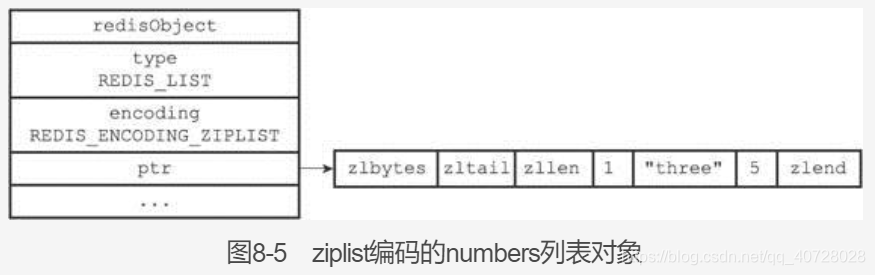
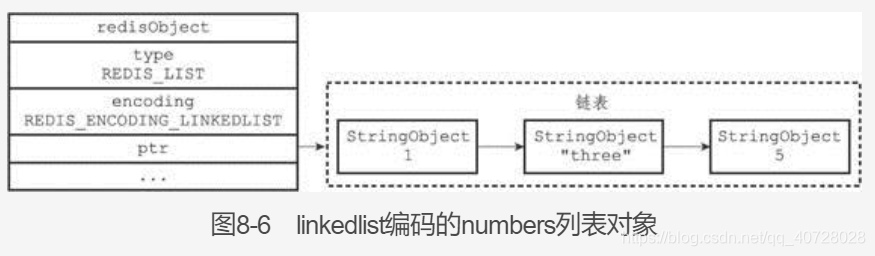


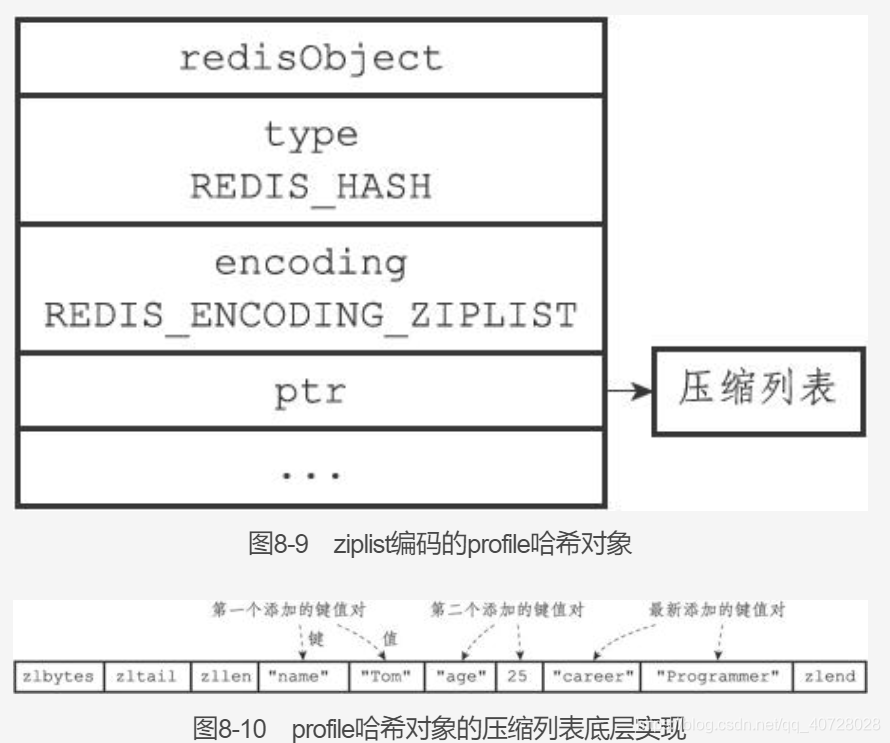
3. hash对象:
hash对象的实现有ziplist与hashtable。

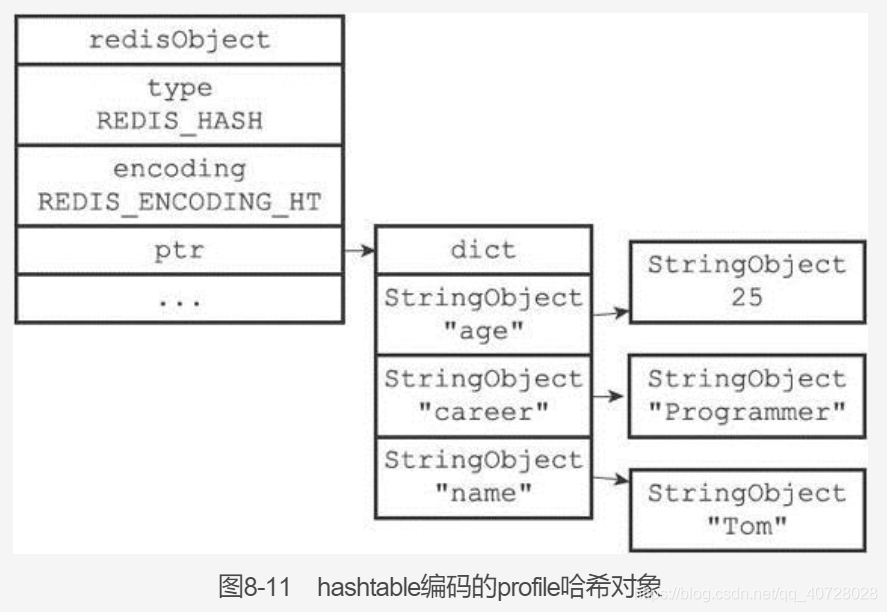
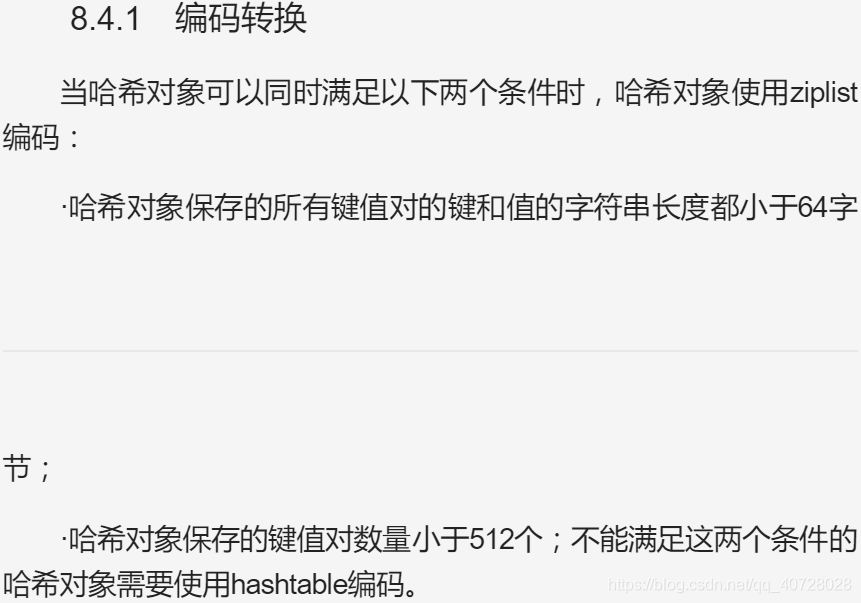
4. set对象:
set实现有intset与Hashtable。
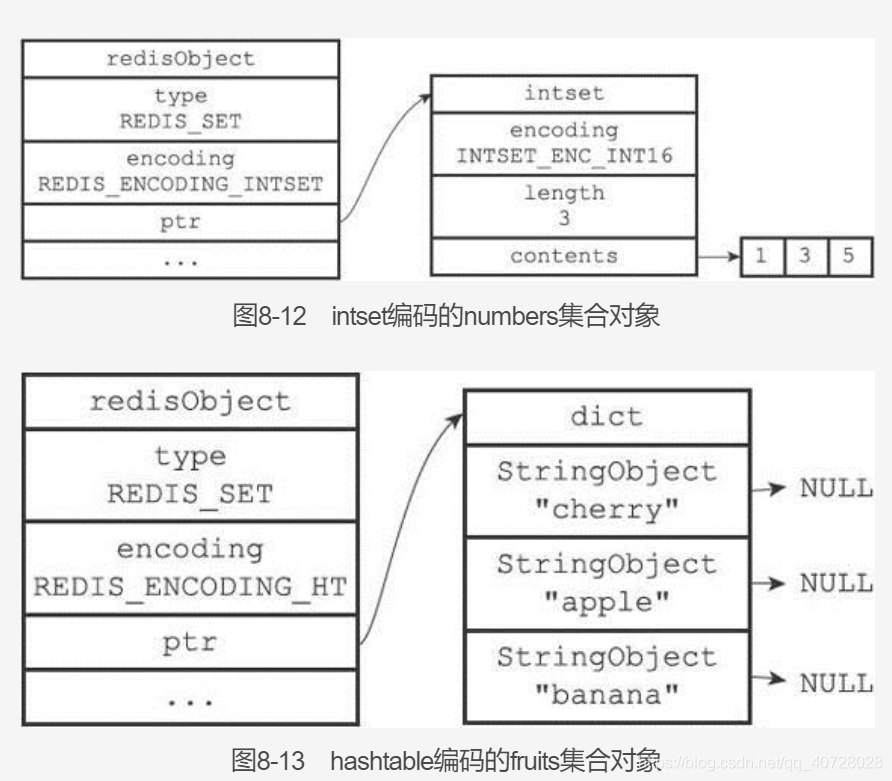

5. zset对象:
zset有实现有ziplist与skiplist。

ziplist实现:

skiplist实现:

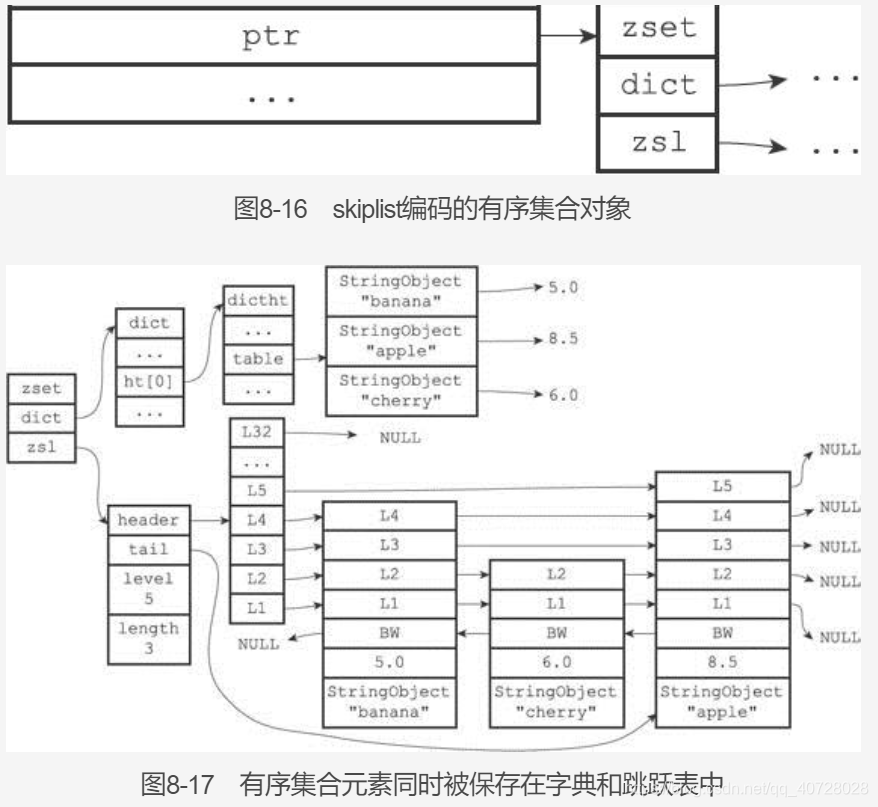

摘抄自《Redis设计与实现》