网上关于GPU编程优化的文章很多,本篇博客带领读者更深入的理解GPU编程以及各个函数的运行时间,为开发者优化Shader编程提供一些指导。除了Shader编程中的变量定义精度优化,还有函数的优化,下面给读者展示如下:
在PC端执行
Shader代码在PC端使用的函数执行时间:
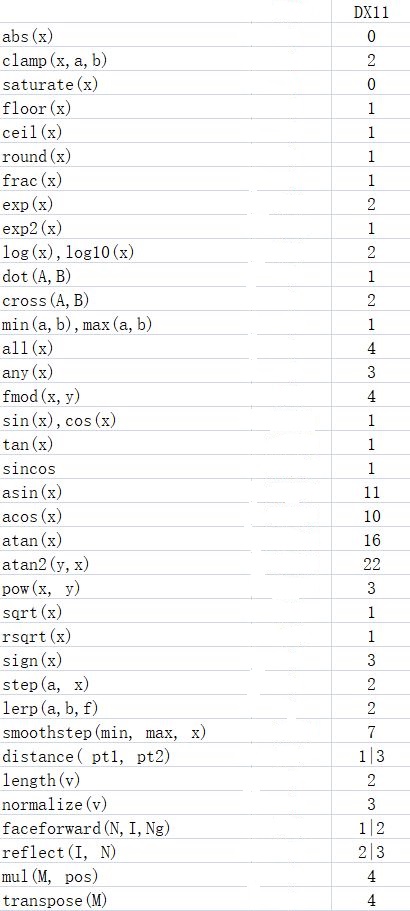
该图是以DX11为例,用|隔开的数据,前面的部分是计算单分量时的指令数,后面的部分是计算float4时的指令数。通过上图给给读者总结一下:
- 反三角函数非常费
- abs和saturate是免费的
- 除了反三角函数外,fmod和smoothstep比预期更费
- log,exp,sqrt(单分量)的成本实际上很低,所以由他们组合成的pow也不高
- sin,cos在DX11使用了专门一条单指令,成为了低成本函数
另外,绝大部分GPU是一次性计算4个分量,计算一个float4和只计算单个float耗时是一样的。当计算float时,剩下三个分量的时长会被浪费。
在移动端执行
由于硬件不同,每条指令的时间成本确实可能是不一样的。下面通过具体的Shader代码样例给出主流GPU的执行时间,供参考:

左边对应的是每行的代码,右边是执行所需时间,通过上图可以看出:1/x, sin(x), cos(x), log2(x), exp2(x), 1/sqrt(x)这些指令的时间成本是一样的,而且和普通的四则运算很接近,但是sin,cos毕竟在旧硬件上成本较高,由于不清楚硬件的具体情况,还是要尽可能少用。
另外Nvidia提供了一个工具:Nvidia ShaderPerf,可以帮助读者分析Shader代码,网址:点击打开链接。
GPU执行是一个多线程的,它最擅长的就是对矩阵和向量的运算,在Shader编程时尽量少用一些函数以及循环语句,这些都会对其执行效率有影响。
另外为了满足帧数的要求,我们可以将骨骼动画放到GPU中执行,也就是常说的Animation GPU Instancing以及GPU Instancing。
优化方案
其中GPU Instancing的代码下载地址:点击打开链接
Animation GPU Instancing的代码下载地址:点击打开链接
当然在使用GPU Instancing时也要注意一个问题就是:每一次的instanced draw,肯定要传一个instance buffer,这样每一帧都要重新生成这个instance buffer然后调用昂贵的glBufferData,或者Dx11的map/unmap来更新这个instance buffer。这种需要每帧更新数据的buffer(一般叫Dynamic buffer)是不可避免的。
但是也应该尽量降低Map/Unmap的大小和次数。在d3d11中,一般会将constant buffer按更新频率分组,通常可以分为PerFrameData, PerMaterialData, PerObjectData。相机相关的viewMatrix, projMatrix放到PerFrameData中,当前材质相关的属性放到PerMaterialData中,当前渲染对象的世界矩阵放到PerObjectData中。PerObjectData就是每次drawcall都需要Map/Unmap的,而你在instance buffer中放的数据,就是本来的PerObjectData的数组。N次instance drawcall总共包含M个instance的话,其实你是将Map/Unmap的次数从M降到了N,是优于非instance draw的。
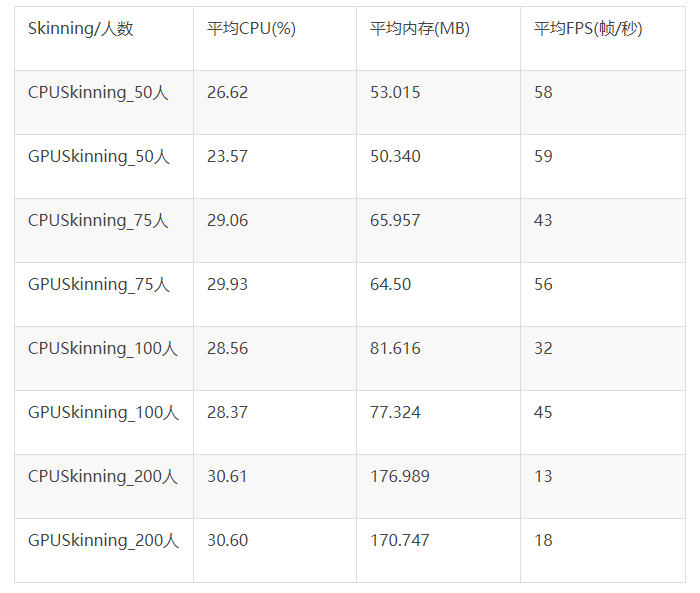
以上数据是通过小米手机测试的:
随人数增加,两者CPU负载趋一致,GPU Skinning比CPU Skinning内存稍低;
随人数增加,GPU Skinning比CPU Skinning FPS高30%左右;
75人以下,GPU Skinning 比 CPU Skinning的CPU负载稍低,内存较低,FPS相近(此时非GPU瓶颈);
是否使用GPUSkinning策略,也取决于CPU或GPU的负载情况。如果当前的CPU负载瓶颈,GPU较轻,可使用GPUSkinning;反之,则建议使用默认的CPUSkinning。详情参考网址:点击打开链接
GPU存储
在GPU中会声明一些变量,这些变量存储在哪里?本节就给读者介绍一下:
首先我们看一下integrated GPU,也就是intel,arm等和CPU处于同一个DIE的GPU,它们的存储体系是如何的。首先,这些GPU自己的video memory都是从CPU可用的主存中分出来的,例如一个PC有4G的物理存储,分给intel核显512MB后,就只剩下3.5G可以给CPU用了。
在这些integrated GPU中,GPU和CPU处于一个DIE中,所以很多时候GPU和CPU可以共享总线。GPU自己的video memory也是在总线上走的。除了GPU自己的video memory之外,CPU和GPU有时候需要共享一些数据,例如,CPU将Vertex Buffer/Index Buffer放入主存中,然后让GPU使用。如我们之前所说,主存是CPU的存储,GPU是无法看到这部分的。为了解决这个问题,业界引入了一个叫做GART的东西,Graphics Address Remapping Table。这个东西长得和CPU用来做地址翻译的page table很像,作用也很类似,就是将GPU用的地址重新映射到CPU的地址空间。有了GART,CPU中的主存就可以对GPU可见了。但是反方向呢?GPU的local memory是否对CPU可见?
integrated GPU的local memory是从主存中分配出来,受限于主存的大小,能够分配出来的空间并不大,一般是256M/512M,最多的也就1GB。这么点儿地址空间,完全可以全部映射到CPU的地址空间中。如果OS是32位系统,可以寻址的地址空间有4G,分出256M/512M来全部映射GPU的local memory也不是多么难的事情。但是分出1G的话似乎有点儿过分了,所以还是建议OS上64位地址空间,这样integrated GPU的local memory就可以全部映射到CPU地址空间中了。
对于独立显卡,也就是所谓的dedicated GPU,情况就又不一样了。一般独立的GPU都有自己独立的存储实体,就是拥有不同于主存的video memory chip。而且目前来看,这些GPU所用的video memory chip都是板载的,也就意味着无法升级和替换。这些GPU自带的video memory有时候太大了,例如拥有4G或者6G的显存,将之完全映射到CPU的地址空间既不现实,也无可能。想象一下,一个带6G显存的显卡,在一个32位OS上,OS整个4G的地址空间都放不下全部6G的显存。所以,这些独立显卡拥有和另一套稍微有点儿不同的存储和地址空间映射机制,来解决这个问题。
一般的解决方法是,只映射一部分区域到CPU的地址空间,典型的大小是256MB/512MB。这段地址空间会通过PCIe的bar获取一个CPU可见的地址空间,所以一般来说,同样也是BIOS设置,并且开机后不可变的。最近PCIe支持resize bar的技术,支持这项技术的GPU可以动态调整大小,因此使用起来也就更加灵活了。
除了暴露给CPU可见部分的video memory之外,其他部分都是CPU不可见的。这部区域一般被驱动用来做一些只有GPU可见的资源的存储,例如临时的Z buffer等。
理解GPU的存储体系结构,对于深刻理解3D渲染管线,以及其他使用GPU的场景时,资源创建的标志位有着非常重要的作用。
详情查看网址: 点击打开链接在Integrated GPU中,GPU一般和CPU共享相同的物理存储。GPU自己的local memory实际上是从CPU的main memory中分配出来一块物理连续的空间来模拟的,即所谓的Unified Memory Architecture模型。注意即使在Unified Memory Architecture,Address也并非是Unified的,GPU和CPU用的地址也不一定位于一个地址空间内。
对于GPU而言,它能用的存储包括自己的local memory(实际上就是远在DRAM地方分出来的一部分),以及一部分通过GART可以访问的system memory(直接访问CPU的物理地址空间)。对于local memory而言,其可以完全映射到CPU的地址空间,因此,CPU要通过local memory往GPU share数据是非常简单的事情。然而local memory是global的,CPU上各自运行的process想要使用local memory来快速传递数据基本上是不可能的,毕竟这种global的resource应该由内核来管理。CPU上各自的process想要往GPU上upload数据,还得依靠GART才行。
GART的原理非常简单,就是将GPU自己的地址空间的一个地址映射到CPU的地址空间。假设GPU的local有128MB,那么可以建立一个简单的映射表,当GPU访问128M-256M的时候,将之映射到CPU地址空间内,一般是不连续的4kB或者64kB的page。这样,CPU上的进程将数据填写到自己分配的地址空间内,然后内核通过GART,将GPU的一段地址空间映射到之前CPU上进程写的地址空间,这样,GPU就可以用另一套地址空间来访问相同的数据了。
再后面就是关于GPU硬件方面的知识了,详情查看:点击打开链接
在这里通过一个案例给读者介绍一下GPU的工作原理,我们开发游戏时,资源从内存上传到显存时,在DX11中都对应哪些过程?
基本有三种方法可以做到这件事情。
1. 建立资源的时候通过initial data传入,就一次。
2. Map->memcpy->Unmap。
3. UpdateSubresource。
4. 先用2把数据放入一个staging资源,再用copyresource放入default资源。
第一种可以认为是同步的。runtime会建立一个资源,让底层map->memcpy->unmap。map的时候资源一定不会在使用,因为都还没建立出来呢。所以这个过程很快。
第二种也可以认为是同步的。原理同前。但在map的时候,资源可能正在被使用,所以如果没有NO_WAIT标志,流水线就会被block,等待资源可用的时候才完成map。
第三种是异步的。驱动会在内部开一块临时空间,把数据拷进去,等待资源不被占用的时候进行map->memcpy->unmap。
第四种,看后面我说的就自然会有解释。
好了,所以核心就在map/unmap上。
根据不同的类型,staging/dynamic/default,所在的位置不同(resident不同),map是做的不一样的事情。
staging: 这个可以认为就是一块线性的sys mem。map就是把它指针给你而已。但dx runtime不保证每次map给你的是同一个地址。我曾经试图这么假设过,被dx组的人无情地修理了。
dynamic: 在runtime里实际上会建立2个资源,一个sys mem一个gpu mem。map的时候给你sys mem的,在unmap之后把新数据同步到gpu mem的。
default: 在gpu mem。不能在API级别map/unmap。只能copyresource过去。
所以,这个过程就是,
app->map (runtime)->map(user mode driver)->address->memcpy->unmap (runtime)->unmap (user mode driver)->copyresource (runtime)->copyresource(user mode driver)->map(kernel mode driver)->memcpy to gpu mem (user mode driver)->unmap(kernel mode driver)。
效率方面:
3比2快,大部分时候3比2快4-8倍,偶尔慢个20%。这一点和nv/amd的ppt很不一样,他们的ppt里假设是任意次序调用。一般好的图形程序不会那样,而仍会在每一帧开始的时候灌几次数据,接下去全都是使用数据。
4如果遇到目标资源正在被使用,就会让copyresource变成异步,从而下一次map的时候会阻塞。解决方法是用多个临时的staging资源(一般来说3个就够),按照ring buffer的方式使用。相当于手动弄成异步拷贝了。
1的话,可以作为4的备选。也就是说,如果遇到目标资源正在被使用,就建立一个新的staging,同时把数据作为初始数据放进去。在上面调用copyresource后就release,不会堵住流水线。
最后,对于有志于成为GPU架构师的读者,在此给出一份学习书籍的清单供参考: