由于项目原因,需要对CPU代码进行cuda代码转换,从而达到加速的目的,在这里监督介绍一下整个转换的流程。
cuda代码与c++代码其实相似性很高,其核心点在于如何在cpu调用gpu进行线程分配,从而达到加速计算的目的。
对于gpu,必须包含的头文件有cuda_runtime.h,device_launch_parameters.h
这两个头文件是用来检测gpu显卡以及对其内存进行操作。
1. 确认可使用设备
struct cudaDeviceProp properties;
cudaError_t cudaResultCode = cudaGetDeviceCount(&deviceCount);
if (cudaResultCode != cudaSuccess)
deviceCount = 0;
/* machines with no GPUs can still report one emulation device */
for (device = 0; device < deviceCount; ++device) {
cudaGetDeviceProperties(&properties, device);
if (properties.major != 9999) /* 9999 means emulation only */
if (device == 0)
{
printf("multiProcessorCount %d\n", properties.multiProcessorCount);
printf("maxThreadsPerMultiProcessor %d\n", properties.maxThreadsPerMultiProcessor);
}
}在这里选择获取其最大处理器数量,对于该块显卡的信息有一定的了解,方便之后的thread和block的数量设定。
2.gpu内存分配
若想要在gpu计算,首先要确保数据存储在gpu上,因此需要进行gpu内存分配,与cpu相同使用malloc相同功能的函数。
cudaError_t status = cudaMalloc(&dBuf, sizeof(float) * dBufSize);
if (status != cudaSuccess)
{
printf("****************cuda malloc dbuf error ******************* \r\n");
return;
}在每一次分配时,我们需要确保gpu可以成功分配,根据返回的status进行判断。这里只列举我遇到的返回代码。
- cudaSuccess = 0
API调用返回没有错误。 - cudaErrorIllegalAddress = 700
设备在无效的存储器地址上遇到了加载或存储指令。这会使进程处于不一致状态,并且任何进一步的CUDA工作都将返回相同的错误。要继续使用CUDA,必须终止该过程并重新启动。
如果得到cudaSuccess,成功分配无需担心。但若是遇到700,第一步要查看的就是gpu地址和cpu地址是否混淆。这个错误多出在调用的时候,内存分配基本不会出现。
成功分配空间后,我们需要对开辟的空间进行赋值。
3.内存复制
对于内存赋值,最常用的应该是将cpu的数据复制到gpu当中。
status = cudaMemcpy(xyABD, pP->xyABD[0], NP*sizeof(cuFloatComplex), cudaMemcpyHostToDevice);
if (status != cudaSuccess)
{
printf("****************cuda malloc dbuf error ******************* \r\n");
return;
}
status =cudaMemcpy(aberrationOut, Waberration0, sizeof(float) * NP, cudaMemcpyDeviceToHost);
if (status != cudaSuccess)
{
printf("****************cuda malloc dbuf error ******************* \r\n");
return;
}该函数有四个参数,第一个目标地址,第二个源地址,第三个复制的大小(需要注意的是这里指的是占用的空间大小,第四个是方向)
cudaMemcpyHostToDevice指的是将cpu的数据复制到gpu当中
cudaMemcpyDeviceToHost指的是将gpu的数据复制到cpu当中,多用于将gpu的计算结果返回至cpu当中。
注意:该函数是同步执行函数,在未完成数据的转移操作之前会锁死并一直占有CPU进程的控制权,所以不用再添加cudaDeviceSynchronize()函数
4.函数调用
对于gpu操作,需要特定的函数。这里简单介绍一下函数类型,分别为__global__、__host__、__device__。
(1)__host__
如果没有标明前缀,那么函数默认为__host__,可以理解为CPU函数,这些函数不能被global和device函数所调用。
(2)__global__
前缀注明__global__,则这个函数可以被GPU调用,并且这个函数可以调用__device__前缀的函数。
关于gpu的操作最常用的应该是__global__类型。
__global__ void gconstMulDbl(float* out, float c, float* in, int number)
{
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int threadMax = blockDim.x * gridDim.x;
for (int i = tid; i < number; i = i + threadMax)
{
out[i] = in[i] * c;
}
}
需要注意的是global类型的函数其返回类型必须是void,因此必须要使用指针作为结果的传递。
这里使用的是一维并行,关于并行分配下文详细讲解。
对于该函数(__global__)的调用必须是cpu函数进行调用,也就是__host__类型函数。
gconstMulDbl < <<block,thread>> >(out, c, in, number);需要注意的是除常参数之外,其余参数均需要保存在gpu上,不可对于cpu的参数进行操作,否则会报错700 。
(3)__device__
__device__表明这个函数是在GPU里面运行的。
准确的来说是使用__global__函数进行调用。其参数也是gpu参数,区别在于无需指明block和thread,直接在global函数中直接调用即可。
5.线程分配
CUDA并行编程的基本思路是把一个很大的任务划分成N个简单重复的操作,创建N个线程分别执行执行。Thread,block,grid是CUDA编程上的概念,为了方便程序员软件设计,组织线程。
thread:一个CUDA的并行程序会被以许多个threads来执行。
block:数个threads会被群组成一个block,同一个block中的threads可以同步,也可以通过shared memory通信。
grid:多个blocks则会再构成grid。
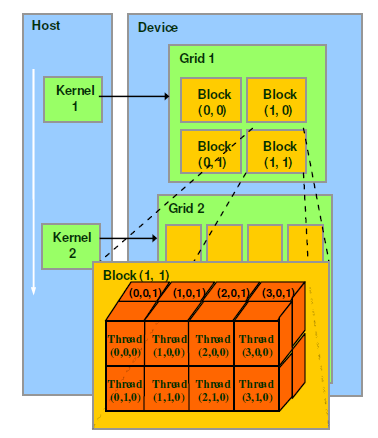
<<<>>>运算符完整的执行配置参数形式是<<<Dg, Db, Ns, S>>>
- 参数Dg用于定义整个grid的维度和尺寸,即一个grid有多少个block。为dim3类型。Dim3 Dg(Dg.x, Dg.y, 1)表示grid中每行有Dg.x个block,每列有Dg.y个block,第三维恒为1(目前一个核函数只有一个grid)。整个grid中共有Dg.x*Dg.y个block,其中Dg.x和Dg.y最大值为65535。
- 参数Db用于定义一个block的维度和尺寸,即一个block有多少个thread。为dim3类型。Dim3 Db(Db.x, Db.y, Db.z)表示整个block中每行有Db.x个thread,每列有Db.y个thread,高度为Db.z。Db.x和Db.y最大值为512,Db.z最大值为62。 一个block中共有Db.x*Db.y*Db.z个thread。计算能力为1.0,1.1的硬件该乘积的最大值为768,计算能力为1.2,1.3的硬件支持的最大值为1024。
- 参数Ns是一个可选参数,用于设置每个block除了静态分配的shared Memory以外,最多能动态分配的shared memory大小,单位为byte。不需要动态分配时该值为0或省略不写。
- 参数S是一个cudaStream_t类型的可选参数,初始值为零,表示该核函数处在哪个流之中。
参数介绍结束,那具体介绍一下不同维度的应用。
下图就是我示例代码的分配方式,一维分配只使用x参数。我这里加了一重循环为了避免block和grid数量设置过小,小于其数组个数从而得到错误结果。
__global__ void gconstMulDbl(float* out, float c, float* in, int number)
{
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int threadMax = blockDim.x * gridDim.x;
for (int i = tid; i < number; i = i + threadMax)
{
out[i] = in[i] * c;
}
}
接下来是二维的应用,即block二维,grid 二维
int blockId = blockIdx.x + blockIdx.y * gridDim.x;
int threadId = blockId * (blockDim.x * blockDim.y) + (threadIdx.y * blockDim.x) + threadIdx.x; 
(图源「hujingshuang」的原创文章,原文链接:https://blog.csdn.net/hujingshuang/article/details/53097222)
这一部分我还没有具体应用过,便不细写了。
6.内存释放
程序运行结束,需要将运算结果拷贝到指定的cpu内存中。对于分配的gpu空间我们需要进行释放。
cudaError_t status= cudaFree((void*)gpuPar->XPupil);与cpu内存释放相同只需要释放当时分配的指针。同样利用cudaError_t 返回的结果判断释放是否成功。
总结
至此,整个cuda编程入门基本就结束了。但是利用gpu加速,优化的道路远不止此,例如block和grid数量的分配,并行计算的方式,线程同步等等都需要不断探索。