一、 题目(模式分类duda第二版中文版64页)
(a)假设前面两个类别的先验概率相等(P(ω1) = P(ω2) = 1/2 P(ω1) = P(ω2) = 1/2, P(ω3) = 0) P(ω3) = 0),仅利用x1x1特征值为这两类判别设计一个分类器。
(b)确定样本的经验训练误差,即误分点的百分比。
(d)现在利用两个特征值x1x1和x2x2,重复以上各步。
(e)利用所有3个特征值重复以上各步。
(f)讨论所得的结论。特别是,对于一有限的数据集,是否有可能在更高的数据维数下经验误差会增加?
二、实验过程
首先写出书中69式的函数CH1_b,及题目1_b中删去(d/)ln(2pi):


其中要注意一点是python中矩阵的两种乘法dot与*
np.dot(A, B):对于二维矩阵,计算真正意义上的矩阵乘积,同线性代数中矩阵乘法的定义。对于一维矩阵,计算两者的内积。
在Python中,实现对应元素相乘,有2种方式,一个是np.multiply(),另外一个是*。
因此要根据d的值分情况使用不同的乘法。
有了这个函数后,将书中的数据键入:


Print w1,w2的结果为:

然后写函数CH2:
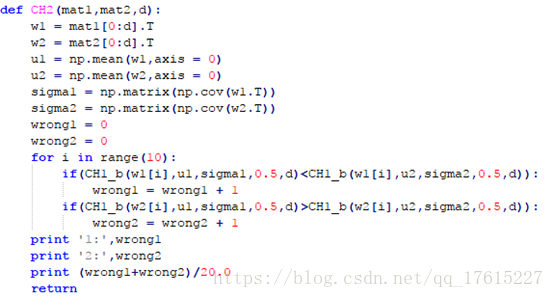
d表示取x1,x2,x3中的几维,w1,w2分别为mat1,mat2根据d截取后的转置。
u1,u2分别为w1,w2的均值,sigma1,sigma2为各自的协方差矩阵。wrong1, wrong2为之后计算的正确个数。
将以上数据代入CH1_b函数中进行比较1类与2类的数值,计算出各自的错误率。
结果:
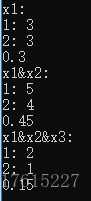
代码(python2.7):
import math
import numpy as np
from numpy.linalg import cholesky
import matplotlib.pyplot as plt
def CH1_b(x,u,sigma,P,d):
if(d==1):
return -0.5*(x-u).T*sigma.I*(x-u)-0.5*math.log(np.linalg.det(sigma)) + math.log(P)
else:
return np.dot(x-u,np.dot(sigma.I,-0.5*(x-u).T))-0.5*math.log(np.linalg.det(sigma)) + math.log(P)
w1 = np.matrix('-5.01,-5.43,1.08,0.86,-2.67,4.94,-2.51,-2.25,5.56,1.03;\
-8.12,-3.48,-5.52,-3.78,0.63,3.29,2.09,-2.13,2.86,-3.33;\
-3.68,-3.54,1.66,-4.11,7.39,2.08,-2.59,-6.94,-2.26,4.33')
w2 = np.matrix('-0.91,1.30,-7.75,-5.47,6.14,3.60,5.37,7.18,-7.39,-7.50;\
-0.18,-2.06,-4.54,0.50,5.72,1.26,-4.63,1.46,1.17,-6.32;\
-0.05,-3.53,-0.95,3.92,-4.85,4.36,-3.65,-6.66,6.30,-0.31')
print w1
print w2
def CH2(mat1,mat2,d):
w1 = mat1[0:d].T
w2 = mat2[0:d].T
u1 = np.mean(w1,axis = 0)
u2 = np.mean(w2,axis = 0)
sigma1 = np.matrix(np.cov(w1.T))
sigma2 = np.matrix(np.cov(w2.T))
wrong1 = 0
wrong2 = 0
for i in range(10):
if(CH1_b(w1[i],u1,sigma1,0.5,d)<CH1_b(w1[i],u2,sigma2,0.5,d)):
wrong1 = wrong1 + 1
if(CH1_b(w2[i],u1,sigma1,0.5,d)>CH1_b(w2[i],u2,sigma2,0.5,d)):
wrong2 = wrong2 + 1
print '1:',wrong1
print '2:',wrong2
print (wrong1+wrong2)/20.0
return
print 'x1:'
CH2(w1,w2,1)
print 'x1&x2:'
CH2(w1,w2,2)
print 'x1&x2&x3:'
CH2(w1,w2,3)