问题:
- 分别基于SVM的iris数据集和识别
(1)构建SVM程序,实现对iris数据集、pima-indians-diabetes数据集的分类。
(2)要求分别使用线性SVM和核化SVM方法实现。并对比分析两种方法的区别。(将数据集划分成训练集和测试集(或将数据7:3分,或采用5折交叉);
数据集下载地址:http://archive.ics.uci.edu/ml/datasets/Iris
对于iris数据集:
#作 者:Asita
#开发时间:2021/11/19 20:45
from sklearn import svm
from sklearn.svm import LinearSVC
import numpy as np
from sklearn.model_selection import train_test_split
# define converts(字典)
def Iris_label(s):
it = {
b'Iris-setosa': 0, b'Iris-versicolor': 1, b'Iris-virginica': 2}
return it[s]
# 1.读取数据集
path = 'F:/研究生/课程/机器学习/SVM/Iris.data'
data = np.loadtxt(path, dtype=float, delimiter=',', converters={
4: Iris_label})
# converters={4:Iris_label}中“4”指的是第5列:将第5列的str转化为label(number)
# print(data)
# print(data.shape)
# 2.划分数据与标签
x, y = np.split(data, indices_or_sections=(4,), axis=1) # x为数据,y为标签
# indices_or_sections: 如果是一个整数,就用该数平均切分,如果是一个数组,为沿轴切分的位置(左开右闭)
# axis=1表示纵向切分,默认为0(横向)
train_data, test_data, train_label, test_label = train_test_split(x, y, random_state=1, train_size=0.7,
test_size=0.3) # sklearn.model_selection.
# print(train_data.shape)
# 3.训练svm分类器
#C:误差项惩罚系数,默认值是1 kernel=linear表示线性核
classifier1 = svm.SVC(C=2, kernel='rbf', gamma=10, decision_function_shape='ovo') # ovr:一对多策略
classifier2=LinearSVC(C=1e9)
classifier1.fit(train_data, train_label.ravel()) # ravel函数在降维时默认是行序优先
classifier2.fit(train_data,train_label.ravel())
# 4.计算svc分类器的准确率
print("准确率:")
print("rbf:")
print("训练集:", classifier1.score(train_data, train_label))
print("测试集:", classifier1.score(test_data, test_label))
print("线性:")
print("训练集:", classifier2.score(train_data, train_label))
print("测试集:", classifier2.score(test_data, test_label))
运行结果:
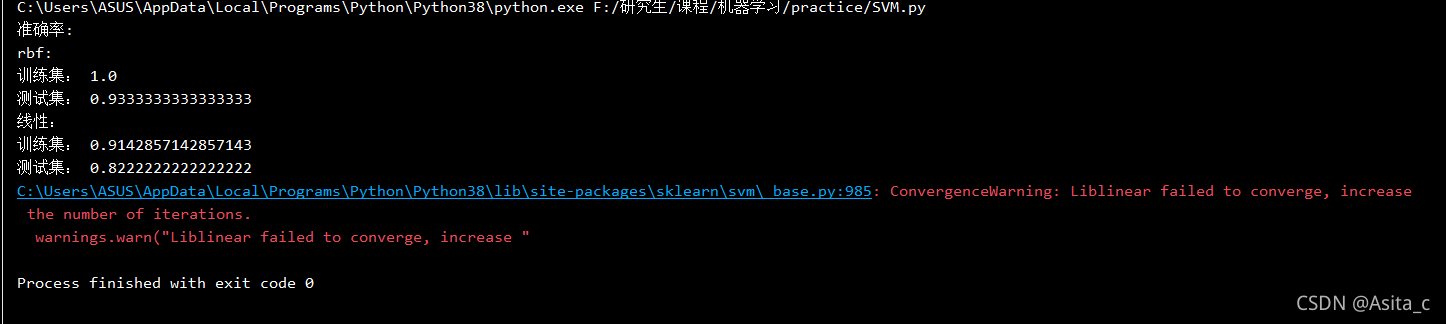
这里代码是直接调库训练SVM的,分别使用的是线性SVM的核函数和rcf核函数在Iris数据集上的结果。
在pima-indians-diabetes数据集上跑的大同小异,只是标签是只有两类(0,1),在代码上做了一些小改动。
完整代码:
#作 者:Asita
#开发时间:2021/11/19 20:45
from sklearn import svm
import numpy as np
from sklearn.model_selection import train_test_split
# 1.读取数据集
path = 'F:/研究生/课程/机器学习/SVM/pima-indians-diabetes.data'
data = np.loadtxt(path)
# print(data)
# print(data.shape)
# 2.划分数据与标签
x, y = np.split(data, indices_or_sections=(8,), axis=1) # x为数据,y为标签
# indices_or_sections: 如果是一个整数,就用该数平均切分,如果是一个数组,为沿轴切分的位置(左开右闭)
# axis=1表示纵向切分,默认为0(横向)
train_data, test_data, train_label, test_label = train_test_split(x, y, random_state=1, train_size=0.7,
test_size=0.3) # sklearn.model_selection.
# print(train_data.shape)
# 3.训练svm分类器
#C:误差项惩罚系数,默认值是1 kernel=linear表示线性核
classifier= svm.SVC(C=2, kernel='rbf', gamma=10, decision_function_shape='ovo') # ovr:一对多策略
classifier.fit(train_data, train_label.ravel()) # ravel函数在降维时默认是行序优先
# 4.计算svc分类器的准确率
print("准确率:")
print("rbf:")
print("训练集:", classifier.score(train_data, train_label))
print("测试集:", classifier.score(test_data, test_label))
运行结果:
