爬取网页
- 函数:askUrl(url)
- 浏览器:Chrome开发者版(最好使用这个,其他可能会有问题)
其中“url”,是我们所要爬取的页面的网址,这里我们爬取的是豆瓣电影前250的数据。
https://movie.douban.com/top250?start=
1. 获取代理
首先我们要获取浏览器的头部文件,得到一个User-Agent,以此来进行伪装。
获取方式:
(1) 在打开的页面使用F12,打开页面调试窗口。
(2) 在调试窗口上的导航栏中找到Network
(3) 在页面空白处,左键点击重新加载,注意此时要确保下面这个红点是亮着的。
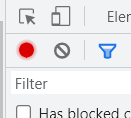
(4) 之后点击下图所示的地方
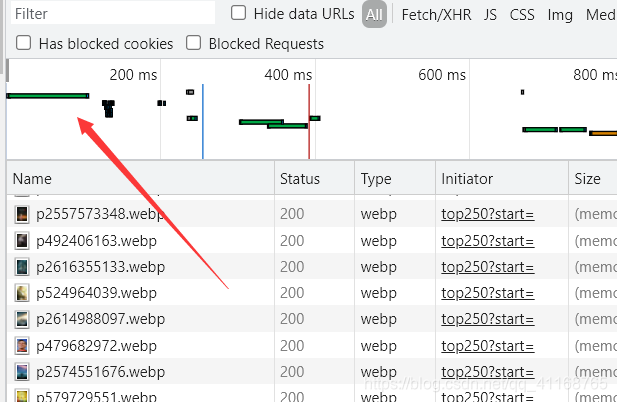
(5)点击之后,下面的任务栏中就只剩一行,点击打开,并下拉,之后便会找到User-Agent
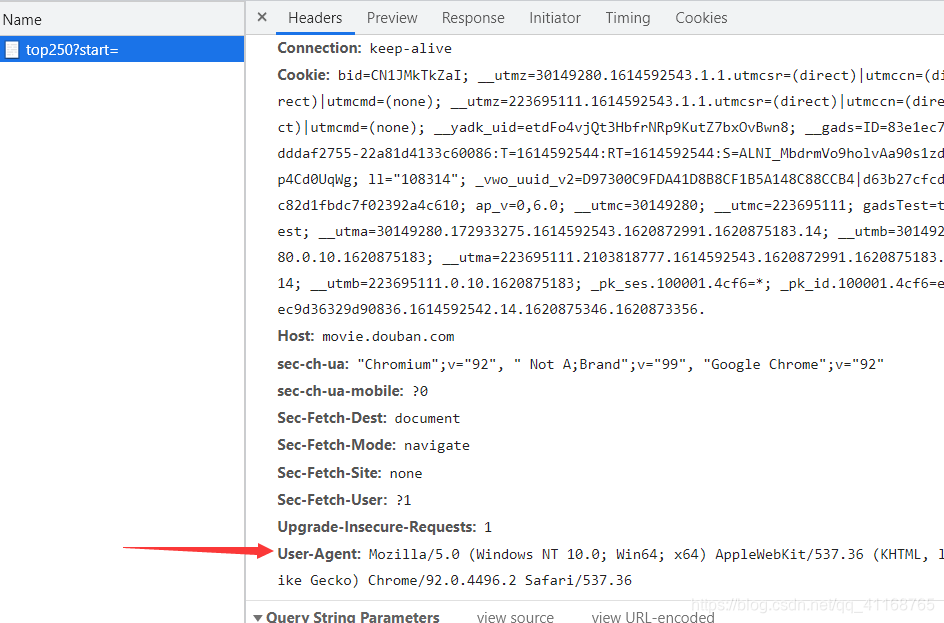
(6)将User-Agent复制到我们的代码中,消除回车,放在head里面
head={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4427.5 Safari/537.36"
}
2. 发送请求
我们使用python3的urllib库,其中主要使用urllib.request与urllib.error
import urllib.request,urllib.error
首先用respond接收打开的页面,之后用定义过的空字符串读取respond中的HTML页面代码,注意使用“UTF-8”形式哦。
response = urllib.request.urlopen(request)#发送请求,得到响应
html = response.read().decode("utf-8")#读取代码
由于在访问页面时,经常出现没网,被封IP之类的异常情况,因此在此处我们增加一个异常处理。
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e,'code'):
print(e.code)
if hasattr(e,'result'):
print(e.code)
3. 爬取成功
这便可以将页面的实体代码以字符串的形式存储在html中了,让我们先来看看所爬取的内容(篇幅有限,我们在此只展示一部分)
<ol class="grid_view">
<li>
<div class="item">
<div class="pic">
<em class="">1</em>
<a href="https://movie.douban.com/subject/1292052/">
<img width="100" alt="肖申克的救赎" src="https://img2.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg" class="">
</a>
</div>
<div class="info">
<div class="hd">
<a href="https://movie.douban.com/subject/1292052/" class="">
<span class="title">肖申克的救赎</span>
<span class="title"> / The Shawshank Redemption</span>
<span class="other"> / 月黑高飞(港) / 刺激1995(台)</span>
</a>
<span class="playable">[可播放]</span>
</div>
<div class="bd">
<p class="">
导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...<br>
1994 / 美国 / 犯罪 剧情
</p>
<div class="star">
<span class="rating5-t"></span>
<span class="rating_num" property="v:average">9.7</span>
<span property="v:best" content="10.0"></span>
<span>2348614人评价</span>
</div>
<p class="quote">
<span class="inq">希望让人自由。</span>
</p>
</div>
</div>
</div>
</li>
<li>
<div class="item">
<div class="pic">
<em class="">2</em>
<a href="https://movie.douban.com/subject/1291546/">
<img width="100" alt="霸王别姬" src="https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2561716440.jpg" class="">
</a>
</div>
<div class="info">
<div class="hd">
<a href="https://movie.douban.com/subject/1291546/" class="">
<span class="title">霸王别姬</span>
<span class="other"> / 再见,我的妾 / Farewell My Concubine</span>
</a>
<span class="playable">[可播放]</span>
</div>
<div class="bd">
<p class="">
导演: 陈凯歌 Kaige Chen 主演: 张国荣 Leslie Cheung / 张丰毅 Fengyi Zha...<br>
1993 / 中国大陆 中国香港 / 剧情 爱情 同性
</p>
<div class="star">
<span class="rating5-t"></span>
<span class="rating_num" property="v:average">9.6</span>
<span property="v:best" content="10.0"></span>
<span>1747542人评价</span>
</div>
<p class="quote">
<span class="inq">风华绝代。</span>
</p>
</div>
</div>
</div>
</li>
可见上面的代码不是我们想要的形式,因此我们还需要对其进行一些简单的分析和裁剪来获得我们想要的数据,这就放在下一篇讲吧,一篇写的多了,你们看着又困。=。=!