论文链接:https://arxiv.org/abs/1512.00567
1、introduction
GoogLeNet与VGG在2014年ImageNet比赛中均取得了较好的成绩,但是在参数数量和计算资源方面,GoogLeNet更少,GoogLeNet有大约5百万个参数,相比较与6000万参数的AlexNet,少了12倍,而VGG的参数数量是AlexNet参数数量的3倍多,因此GoogLeNet更适合大数据处理,特别是计算资源受限的场景。但是由于Inception结构的复杂性导致其较难改进,并且对于GoogLeNet网络各部分的贡献没有清晰明确的描述,因此,本文主要提出了一些GoogLeNet设计原理和优化思路。
2、General Design Principles
- 避免表示瓶颈以及过度压缩,特征表示从输入到输出应该缓慢的减小。
- 高维特征更适合网络的局部处理,在卷积网络中逐步增加激活响应可以解耦合更多的特征,网络也会训练的更快。
- 在进行较大卷积之前,利用空间降维,不会造成特征表示的丢失,甚至可以加速学习。(应该就是1*1的降维)
- 平衡网络的宽度和深度。
3、Factorizing Convolutions with Large Filter Size
3.1. Factorization into smaller convolutions
- 大尺寸滤波器的卷积计算量很大。例如一个 5*5 的卷积比一个3*3卷积滤波器多25/9=2.78倍计算量。
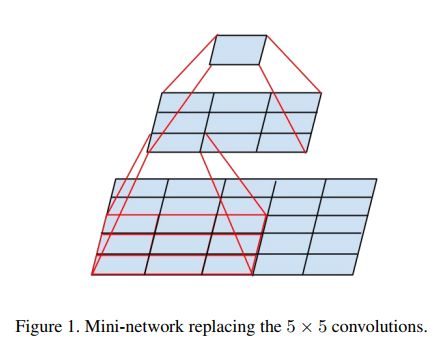
- 我们就可以用两个3*3卷积级联起来代替一个 5*5卷积。如下图所示,直观明了。
- 如果卷积后维度发生变化(如:卷积前是3个特征图,用9个卷积核进行卷积,卷积后将得到9个特征图,公式表示为:n = a m),则在级联过程中,每次增加 倍的卷积核数量。
- 实验证明,级联加入ReLU单元效果更好。
3.2. Spatial Factorization into Asymmetric Convolutions
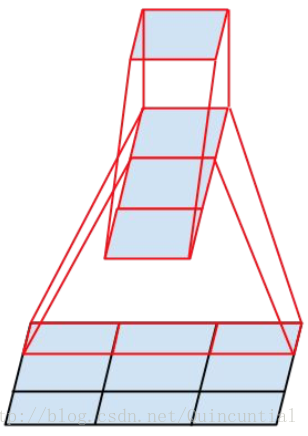
- 对于3*3的卷积可以进一步分解为1*3和3*1的卷积,可以进一步减少计算量,如下图所示。拓展一下,我们可以将nxn的卷积分解成1xn和nx1两个卷积,n越大,降低的计算量越大。
- 这样的分解在浅层效果并不好,在中层的时候效果不错,对于nxn的feature map来说,对于n从12到20,7x1和1x7的组合最好。
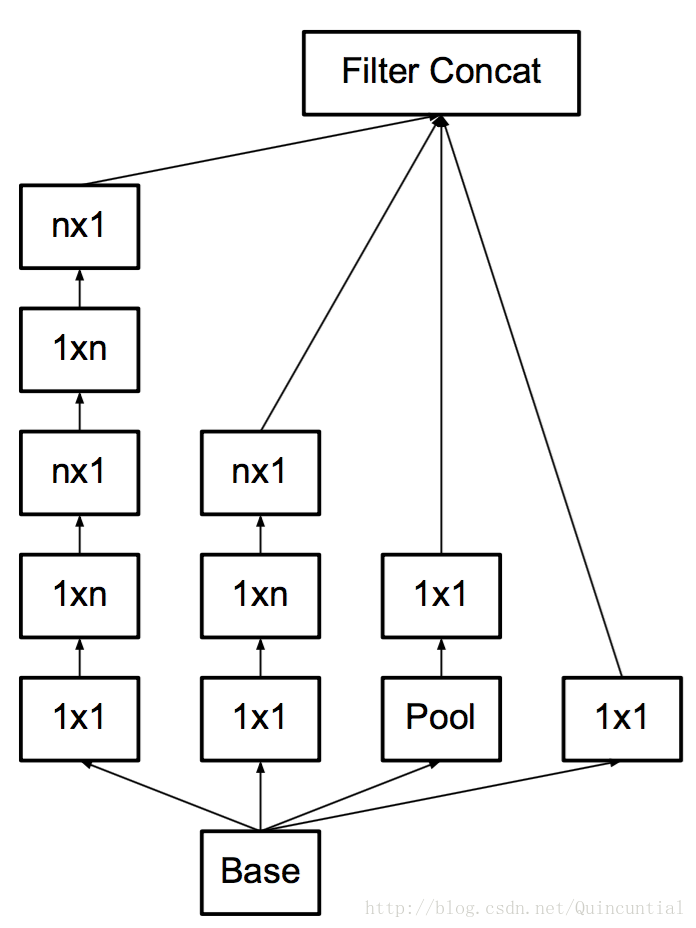
4. Utility of Auxiliary Classifiers
作者通过实验发现,加入辅助分类器,在训练初期的时候对结果并没有特别大的帮助,在训练后期的时候会超上没有使用辅助分类器的模型,作者解释说辅助分类器其实起着regularizer的作用。当辅助分类器使用了batch-normalized或dropout时,主分类器效果会更好。
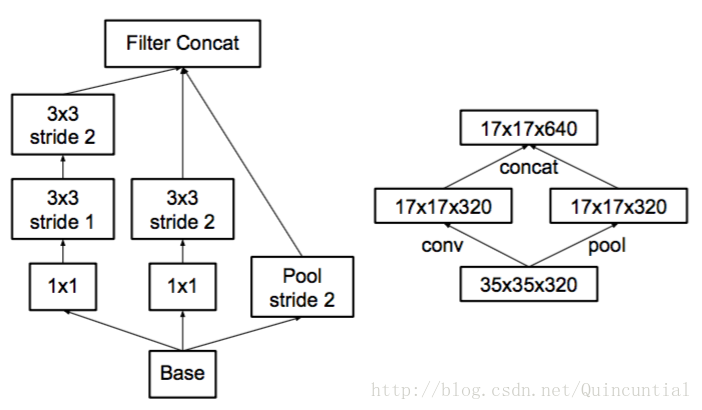
5. Efficient Grid Size Reduction
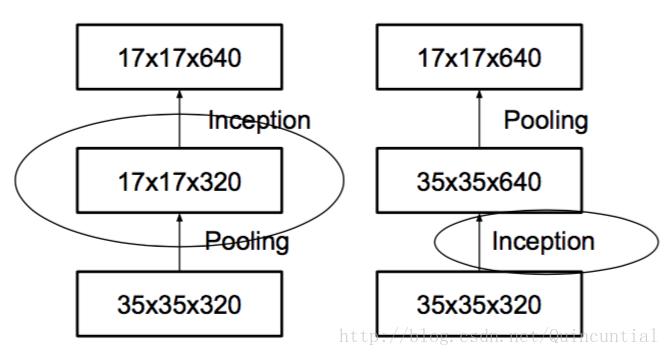
k个d*d特征图,经过卷积变为2k 个d/2 * d/2的特征图。
- stride = 1 进行卷积,然后pooling,使用 次
- 直接利用卷积完成,因此导致 次运算,将计算成本降低为原来的四分之一。然而,由于表示的整体维度下降到 ,会导致表示能力较弱。如下图所示。
并行处理,如下图所示。
6. Inception v3
把7x7卷积替换为3个3x3卷积。包含3个Inception部分。第一部分是35x35x288,使用了2个3x3卷积代替了传统的5x5;第二部分减小了feature map,增多了filters,为17x17x768,使用了nx1->1xn结构;第三部分增多了filter,使用了卷积池化并行结构。网络有42层,但是计算量只有GoogLeNet的2.5倍。
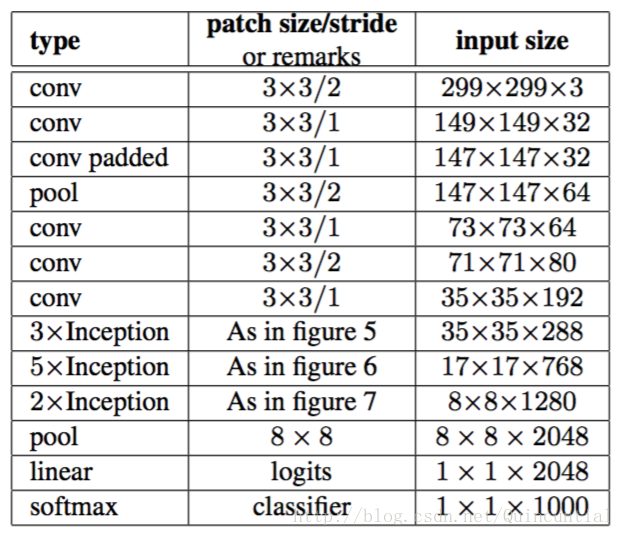
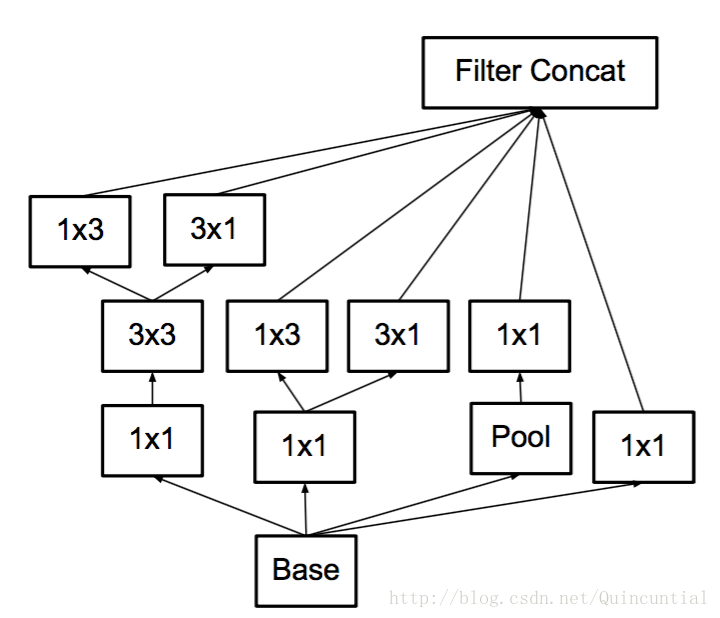
图7,具有扩展的滤波器组输出的Inception模块。这种架构被用于最粗糙的(8×8)网格,以提升高维表示,如第2节原则2所建议的那样。我们仅在最粗的网格上使用了此解决方案,因为这是产生高维度的地方,稀疏表示是最重要的,因为与空间聚合相比,局部处理(1×1 卷积)的比率增加。
7. Model Regularization via Label Smoothing
如果实际标签单元数远大于其他的单元数,则计算损失时候的对数概率比较大,这样会带来两个问题:
- 可能导致过拟合:如果模型学习到对于每一个训练样本,分配所有概率到实际标签上,那么它不能保证泛化能力。
- 鼓励最大的单元与所有其它单元之间的差距变大,降低模型的适应能力。
本文做法:
输入x,模型计算得到类别为k的概率
假设真实分布为q(k),交叉熵损失函数
引入一个独立于样本分布的变量u(k)
本文实验中,
8. Performance on Lower Resolution Input
对于低分辨有图像,使用“高分辨率”receptive field。简单的办法是减小前2个卷积层的步长,去掉第一个pooling层。
为了验证不同的感受野对于分类效果的影响,进行了以下三个实验:
1. 步长为2,大小为299×299的感受野和最大池化。
2. 步长为1,大小为151×151的感受野和最大池化。
3. 步长为1,大小为79×79的感受野和第一层之后没有池化。
实验结果如下:
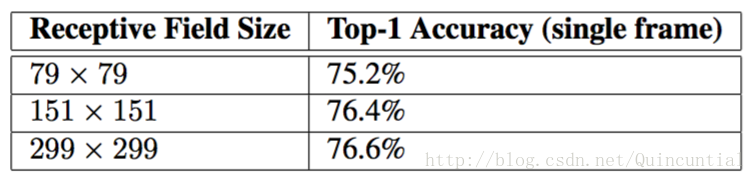
表2。当感受野尺寸变化时,识别性能的比较,但计算代价是不变的。
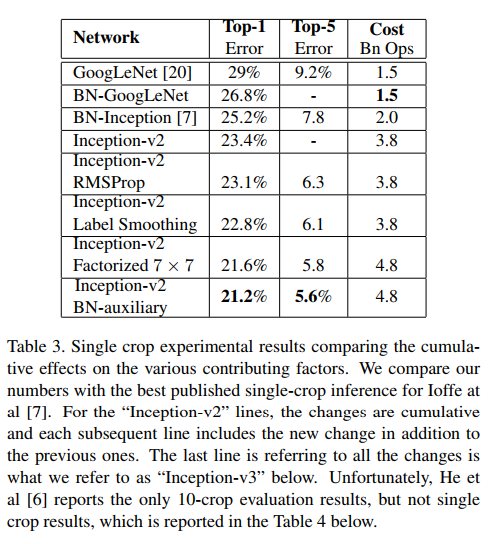
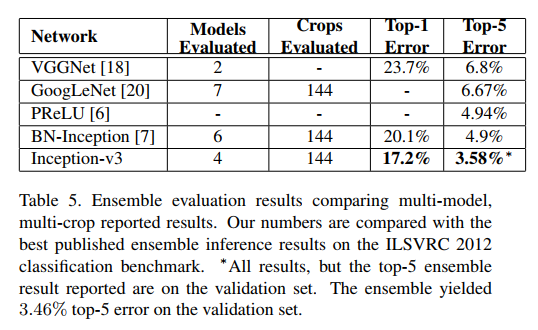
8、实验

参考博客1:http://blog.csdn.net/Quincuntial/article/details/78564397?locationNum=6&fps=1