| x | y |
| 自变量(independent variable) | 因变量(dependent variable) |
| 解释变量(explanatory variable) | 被解释变量(explained variable) |
| 原因变量(causal variable) | 结果变量(effect variable) |
回归分析都是统计学的核心。它其实是一个广义的概念,通指那些用一个或多个预测变量(也称自变量或解释变量)来预测响应变量(也称因变量、效标变量或结果变量)的方法。通常,回归分析可以用来挑选与响应变量相关的解释变量,可以描述两者的关系,也可以生成一个等式,通过解释变量来预测响应变量。
| 回归类型 | 用途 |
| 简单线性 | 用一个量化的解释变量预测一个量化的响应变量 |
| 多项式 | 用一个量化的解释变量预测一个量化的响应变量,模型的关系是n阶多项式 |
| 多元线性 | 用两个或多个量化的解释变量预测一个量化的响应变量 |
| 多变量 | 用一个或多个解释变量预测多个响应变量 |
| Logistic | 用一个或多个解释变量预测一个类别型响应变量 |
| 泊松 | 用一个或多个解释变量预测一个代表频数的响应变量 |
| Cox比例风险 | 用一个或多个解释变量预测一个事件(死亡、失败或旧病复发)发生的时间 |
| 时间序列 | 对误差项相关的时间序列数据建模 |
| 非线性 | 用一个或多个解释变量预测一个量化的响应变量,不过模型是非线性的 |
| 非参数 | 用一个或多个解释变量预测一个量化的响应变量,模型的形式源自数据形式,不事先设定 |
| 稳健 | 用一个或多个解释变量预测一个量化的响应变量,能抵御强影响点的干扰 |
普通最小二乘法(ordinary least squares,OLS)的基本原则:最优拟合直线应该使得各点到直线的距离的和最小,也可表述为距离的平方和最小。
普通最小二乘(OLS)回归法,包括简单线性回归、多项式回归和多元线性回归。OLS回归是通过预测变量的加权和来预测量化的因变量,其中权重是通过数据估计而得的参数。一个示例情景如下:
一个工程师想找出跟桥梁退化有关的最重要的因素,比如使用年限、交通流量、桥梁设计、建造材料和建造方法、建造质量以及天气情况,并确定它们之间的数学关系。他从一个有代表性的桥梁样本中收集了这些变量的相关数据,然后使用OLS回归对数据进行建模。这种方法的交互性很强。他拟合了一系列模型,检验它们是否符合相应的统计假设,探索了所有异常的发现,最终从许多可能的模型中选择了“最佳”的模型。如果成功,那么结果将会帮助他完成以下任务。
- 在众多变量中判断哪些对预测桥梁退化是有用的,得到它们的相对重要性,从而关注重要的变量。
- 根据回归所得的等式预测新的桥梁的退化情况(预测变量的值已知,但是桥梁退化程度未知),找出那些可能会有麻烦的桥梁。
- 利用对异常桥梁的分析,获得一些意外的信息。比如他发现某些桥梁的退化速度比预测的更快或更慢,那么研究这些“离群点”可能会有重大的发现,能够帮助理解桥梁退化的机制。

1)简单线性回归 (当回归模型包含一个因变量和一个自变量时)
> wh<-data.frame(weight=c(45,50,48,40,51,55,48,53,47,55),
+ height=c(156,154,162,152,156,164,152,172,159,167))
> fit1<-lm(weight~height,data=wh)
> summary(fit1)
结果:
Call:
lm(formula = weight ~ height, data = wh) ## y~x
Residuals:
Min 1Q Median 3Q Max
-5.6093 -2.4247 0.0531 3.1629 3.5679
Coefficients:
Estimate Std. Error t value Pr(>|t|) ##估值,标准误差,T值,P值
(Intercept) -28.1467 27.9654 -1.006 0.3437 ## p<0.05 拒绝原假设,认为有关
height 0.4852 0.1753 2.768 0.0244 * ## 级别:一个*
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 ## 标注预测变量的显著性
Residual standard error: 3.534 on 8 degrees of freedom ## 残差误差 自由度8??10-1-1??
Multiple R-squared: 0.4892, Adjusted R-squared: 0.4254 ## 拟合优度 修正的拟合优度 越
F-statistic: 7.662 on 1 and 8 DF, p-value: 0.02437 ##F统计量(F检验)
解释:
身高每增高1英寸,体重将预期增加0.4852磅;
R平方项( 0.4892)表明模型可以解释体重 48.92%的方差,它也是实际和预测值之间的相关系数;
残差标准误则可认为是模型用身高预测体重的平均误差;
p值在0~0.001之间是非常非常显著,通常用‘***’号表示;在0.001~0.01之间是非常显著,通常用‘**’号表示;在0.01~0.05之间是比较显著,通常用‘**’号表示;在0.05~0.1之间是显著,通常用‘.’号表示;在0.1~1之间是不显著
稍微这样总结一下:
T检验是检验解释变量的显著性的;
R-squared是查看方程拟合程度的;
F检验是检验方程整体显著性的;
>fit1$coefficients ## 返回回归直线的截距intercept和斜率
(Intercept) height
-28.1466535 0.4852362
解释:
weight=0.4852*height-28.1467
## fitted()的结果是你得到相应的模型后,(x1,x2,...,xn)相应的值,也就是(y1,y2,...,yn)的估计值
> fitted(fit1)
1 2 3 4 5 6 7 8
47.55020 46.57972 50.46161 45.60925 47.55020 51.43209 45.60925 55.31398
9 10
49.00591 52.88780
## predict()中你可以用(x1,x2,...,xn)的值,也可以用新的值
> predict(fit1,newdata=data.frame(height=c(150,149)))
1 2
44.63878 44.15354
PS:
1)F值是方差分析中的一个指标,一般方差分析是比较组间差异的,F值越大,P值越小,表示你的结果越可靠。比如:P值=0.01,表示有99%的把握认为你的结论是正确的。(根据设定的自由度和显著水平查t值表,若大于表中的t值,就拒绝原假设)
2)自由度是指当以样本的统计量来估计总体的参数时, 样本中独立或能自由变化的资料的个数。对于回归分析,df=n-k-1,其中k是不含常数项的变量个数,1代表常数项。对于非回归分析,描述性概率论题,t统计量的自由度就是n-1,是因为用样本均值替代总体均值损失了一个自由度。以上二者的t检验的不是同一个命题
2)多项式回归 (当只有一个预测变量,但同时包含变量的幂(比如,X1、X 2、X 3)时)
> fit2<-lm(weight~height+I(height^2),data=wh)
> summary(fit2)
Call:
lm(formula = weight ~ height + I(height^2), data = wh)
Residuals:
Min 1Q Median 3Q Max
-4.8603 -2.8123 0.4423 3.0822 3.5744
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -495.81972 809.11609 -0.613 0.559
height 6.29550 10.04740 0.627 0.551
I(height^2) -0.01802 0.03115 -0.578 0.581
Residual standard error: 3.691 on 7 degrees of freedom
Multiple R-squared: 0.5125, Adjusted R-squared: 0.3732
F-statistic: 3.68 on 2 and 7 DF, p-value: 0.08089
解释:
提高了拟合度,但p值过大哎,可能瞎编的数据不大好> fit3<-lm(weight~height+I(height^2)+I(height^3),data=wh)
> summary(fit3)
Call:
lm(formula = weight ~ height + I(height^2) + I(height^3), data = wh)
Residuals:
Min 1Q Median 3Q Max
-5.2726 -2.3616 0.3487 2.6649 3.8115
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 8.501e+03 2.612e+04 0.325 0.756
height -1.609e+02 4.852e+02 -0.332 0.751
I(height^2) 1.016e+00 3.002e+00 0.339 0.746
I(height^3) -2.132e-03 6.185e-03 -0.345 0.742
Residual standard error: 3.948 on 6 degrees of freedom
Multiple R-squared: 0.522, Adjusted R-squared: 0.2829
F-statistic: 2.184 on 3 and 6 DF, p-value: 0.1909
> plot(wh$height,wh$weight,xlab="height",ylab="weight")
> lines(wh$height,fitted(fit3)) ## n次多项式生成一个n-1个弯曲的曲线
### 虽然更高次的多项式也可用,但几乎没有必要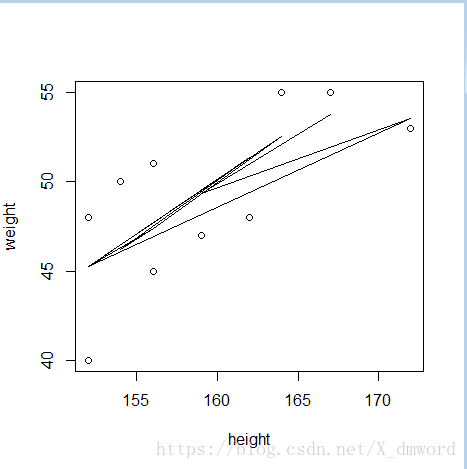
3)多元线性回归 (有不止一个预测变量时)
多元回归分析中,第一步最好检查一下变量间的相关性。cor()函数提供了二变量之间的相关系数,car包中scatterplotMatrix()函数则会生成散点图矩阵。scatterplotMatrix()函数默认在非对角线区域绘制变量间的散点图,并添加平滑(loess)和线性拟合曲线。对角线区域绘制每个变量的密度图和轴须图。
探究一个州的犯罪率和其他因素的关系,包括人口、文盲率、平均收入和结霜天数(温度在冰点以下的平均天数):

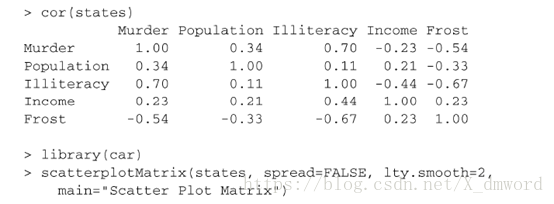
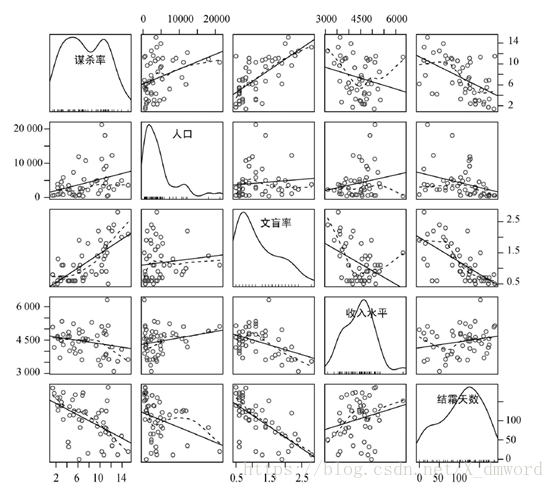
从图中可以看到,谋杀率是双峰的曲线,每个预测变量都一定程度上出现了偏斜。谋杀率随着人口和文盲率的增加而增加,随着收入水平和结霜天数增加而下降。同时,越冷的州府文盲率越低,收入水平越高。
PS:
1)data.frame一般被翻译为数据框,感觉就像是R中的表,由行和列组成,与Matrix不同的是,每个列可以是不同的数据类型,而Matrix是必须相同的,数据框(Data frame)数据框可以由函数read.table 间接创建;这里也可以用函数data.frame来创建。数据框中的向量必须有相同的长度,如果其中有一个比其它的短,它将“循环”整数次(以使得其长度与其它向量相同)
> x<-1:4
> y<-9
> z<-c(8,6)
> w<-4:5 ####也可以c(4:5)
> q<-c(2:4) ## 必须循环整数次,即个数要是它的约数
> data.frame(x,y)
x y
1 1 9
2 2 9
3 3 9
4 4 9
> data.frame(x,z)
x z
1 1 8
2 2 6
3 3 8
4 4 6
> data.frame(x,w)
x w
1 1 4
2 2 5
3 3 4
4 4 5
> data.frame(x,q)
Error in data.frame(x, q) : 参数值意味着不同的行数: 4, 3
2)as.data.frame(x, row.names = NULL, optional = FALSE, ...),
如果一个列表的各个成分满足数据框成分的要求,它可以用as.data.frame()函数强 制转换为数据框
> as.data.frame(x,y)
x
1 1
2 2
3 3
4 4
Warning message:
In as.data.frame.integer(x, y) :
'row.names' is not a character vector of length 4 -- omitting it. Will be an error!
> m<-data.frame(x,y)
> m
x y
1 1 9
2 2 9
3 3 9
4 4 9
> as.data.frame(m)
x y
1 1 9
2 2 9
3 3 9
4 4 9
3)区别两者
data.frame() can be used to build a data frame while
as.data.frame() can only be used to coerce other object to a data frame.(只用于强制其他对象到数据帧)
> df1 <- data.frame(matrix(1:12,3,4),1:3)
> df2 <- as.data.frame(matrix(1:12,3,4),1:3) ## 不会添加最后一列
> df3 <- data.frame(matrix(1:12,3,4),X5=13:15)
> df1
X1 X2 X3 X4 X1.3
1 1 4 7 10 1
2 2 5 8 11 2
3 3 6 9 12 3
> df2
V1 V2 V3 V4
1 1 4 7 10
2 2 5 8 11
3 3 6 9 12
> df3
X1 X2 X3 X4 X5
1 1 4 7 10 13
2 2 5 8 11 14
3 3 6 9 12 15