R软件提供了非常方便地进行逐步回归分析的计算函数step(),它是以AIC信息统计量为准则,通过选择最小的AIC信息统计量。来达到提出或添加变量的目的。
1.前进法
代码实现如下:
data3.1<-read.csv("C:/Users/Administrator/Desktop/data3.1.csv",head=TRUE)
lmo3.1<-lm(y~1,data=data3.1)
lm3.1.for<-step(lmo3.1,scope=list(upper=~x1+x2+x3+x4+x5+x6+x7+x8+x9,lower=~1),direction="forward")
summary(lm3.1.for)
输出结果如下:
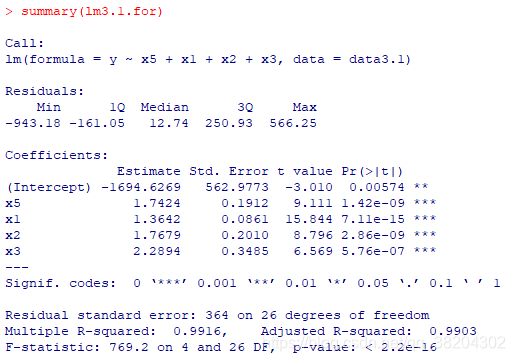
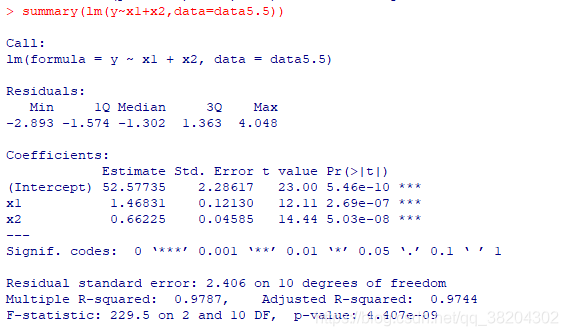
由上述结果可以看到,前进法一次引入了
,最优回归模型为
模型整体上高度显著,且各变量的回归系数均及其显著,复决定系数
,调整的复决定系数
。
2.后退法
代码实现如下:
data3.1<-read.csv("C:/Users/Administrator/Desktop/data3.1.csv",head=TRUE)
lm3.1<-lm(y~x1+x2+x3+x4+x5+x6+x7+x8+x9,data=data3.1)
lm3.1.back<-step(lm3.1,direction="backward")
summary(lm3.1.back)
输出结果为:
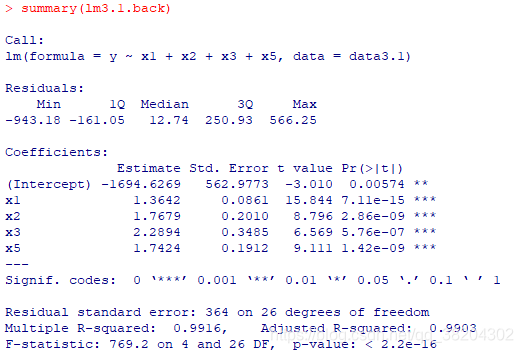
前进法和后退法都有明显的不足。前进法可能存在这样的问题:它不能反映引进新的自变量值之后的变化情况。因为某个自变量开始被引入后得到回归方程对应的AIC最小,但是当再引入其他变量后,可能将其从回归方程中提出会是的AIC值变小,但是使用前进法就没有机会将其提出,即一旦引入就会是终身制的。这种只考虑引入而没有考虑剔除的做法显然是不全面的。类似的,后退法中一旦某个自变量被剔除,它就再也没有机会重新进入回归方程。
根据前进法和后退法的思想及方法,人们比较自然地想到将两种方法结合起来,这就产生了逐步回归。
3.逐步回归法
代码实现如下:
data5.5<-read.csv("C:/Users/Administrator/Desktop/data5.5.csv",head=TRUE)
lm5.5<-lm(y~.,data=data5.5)
lm5.5_step<-step(lm5.5,direction="both")
summary(lm5.5_step)
输出结果为:
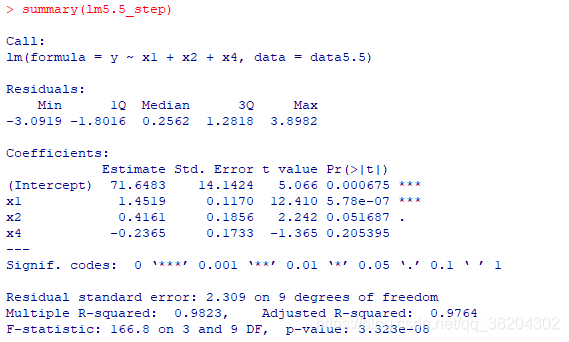
从输出结果看到,逐步回归筛选的最优子集为
,但在显著水平为0.05时,
的回归系数不显著。从上述结果可知,由AIC值选出来的模型在整体最优,但是可能会包含不显著的变量。故需要删去不显著的变量
,得到新的回归结果。