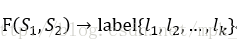
意思是给定两个句子,需要学习一个映射函数,输入是两个句子对,经过映射函数变换,输出是任务分类标签集合中的某类标签。
典型的例子就是Paraphrase任务,即要判断两个句子是否语义等价,所以它的分类标签集合就是个{等价,不等价}的二值集合。除此外,还有很多其它类型的任务都属于句子对匹配,比如问答系统中相似问题匹配和Answer Selection。
由于本文只是一个Word2vec和Doc2vec的应用,是一种无监督的句子对匹配方法,所以这里的映射函数F即为计算两个句子的cosin相似度。
cosin相似度计算公式如下:

基于Word2vec和Doc2vec的句子对匹配方法主要分为三步:
1.训练语料库的Doc2vec和Word2vec模型;
2.用Doc2vec或Word2vec得到句子的向量表示;
3.计算句子向量的cosin相似度,即为两个句子的匹配程度。
其中,语料库使用的是Quora发布的Question Pairs语义等价数据集,可以点击这个链接下载点击打开链接,其中包含了40多万对标注好的问题对,如果两个问题语义等价,则label为1,否则为0。统计之后,共有53万多个问题。具体格式如下图所示:

将这53万多个问题作为语料库,训练Doc2vec和Word2vec模型,即完成了第一步;
# -*- coding: utf-8 -*-
import logging
import os.path
import sys
import multiprocessing
from gensim.models import Doc2Vec
from gensim.models.word2vec import LineSentence
from gensim.models.doc2vec import TaggedLineDocument
if __name__ == '__main__':
program = os.path.basename(sys.argv[0])
logger = logging.getLogger(program)
logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s')
logging.root.setLevel(level=logging.INFO)
logger.info("running %s" % ' '.join(sys.argv))
outp1 = "D:/dataset/quora/vector_english/quora_duplicate_question_doc2vec_model.txt"
outp2 = "D:/dataset/quora/vector_english/quora_duplicate_question_word2vec_100.vector"
outp3 = "D:/dataset/quora/vector_english/quora_duplicate_question_doc2vec_100.vector"
model = Doc2Vec(TaggedLineDocument(inp), size=100, window=5, min_count=0, workers=multiprocessing.cpu_count(), dm=0,
hs=0, negative=10, dbow_words=1, iter=10)
# trim unneeded model memory = use(much) less RAM
#model.init_sims(replace=True)
model.save(outp1)#save dov2vec model
model.wv.save_word2vec_format(outp2, binary=False)#save word2vec向量
#保存doc2vector向量
outid = file(outp3, 'w')
print "doc2vecs length:", len(model.docvecs)
for id in range(len(model.docvecs)):
outid.write(str(id)+"\t")
for idx,lv in enumerate(model.docvecs[id]):
outid.write(str(lv)+" ")
outid.write("\n")
outid.close()由于Doc2vec训练得到的就是句子的向量表示,所以可以直接拿来使用,而Word2vec训练得到的是词的向量表示,不能直接得到句子的向量表示,这里直接将句子中词的词向量相加求均值作为句子的向量表示。
得到句子的向量表示之后,就可以直接用cosin相似度公式直接计算两个句子的相似度啦(这里是用doc2vec表示句子向量的代码)。
import numpy as np
import pandas as pd
# import sys
# reload(sys)
# sys.setdefaultencoding('utf-8')
class ParaPhrase_word2vec:
def load_doc2vec(self, word2vecpath):
f = open(word2vecpath)
embeddings_index = {}
count = 0
for line in f:
# count += 1
# if count == 10000: break
values = line.split('\t')
id = values[0]
print id
coefs = np.asarray(values[1].split(), dtype='float32')
embeddings_index[int(id)+1] = coefs
f.close()
print('Total %s word vectors.' % len(embeddings_index))
return embeddings_index
def load_data(self, datapath):
data_train = pd.read_csv(datapath, sep='\t', encoding='utf-8')
print data_train.shape
qid1 = []
qid2 = []
labels = []
count = 0
for idx in range(data_train.id.shape[0]):
# for idx in range(400):
# count += 1
# if count == 10: break
print idx
q1 = data_train.qid1[idx]
q2 = data_train.qid2[idx]
print q1
qid1.append(q1)
qid2.append(q2)
labels.append(data_train.is_duplicate[idx])
return qid1, qid2, labels
def sentence_represention(self, qid, embeddings_index):
vectors = np.zeros((len(qid), 100))
for i in range(len(qid)):
print i
vectors[i] = embeddings_index.get(qid[i])
return vectors
def consin_distance(self, vectors1, vectors2):
sim = []
for i in range(vectors1.shape[0]):
vec1 = vectors1[i]
vec2 = vectors2[i]
vec0 = np.dot(vec1, vec2)
vec1 = np.power(vec1, 2)
vec2 = np.power(vec2, 2)
vec1 = np.sum(vec1)
vec2 = np.sum(vec2)
vec1 = np.sqrt(vec1)
vec2 = np.sqrt(vec2)
sim.append(vec0/(vec1 * vec2))
return sim
def write2file(self, texts1, texts2, sim, labels, outfile):
f = file(outfile, "w+")
for i in range(len(sim)):
f.writelines(str(sim[i]) + '\t' + str(labels[i]) + '\n')
# if __name__ == '__main__':
# texts1, texts2, labels = load_data(datapath)
# embeddings_index =load_word2vec(word2vecpath=word2vecpath)
# vectors1 = sentence_represention(texts1, embeddings_index)
# vectors2 = sentence_represention(texts2, embeddings_index)
# sim = consin_distance(vectors1, vectors2)
# write2file(texts1, texts2, sim, outfile=outfile)
if __name__ == '__main__':
# doc2vecpath = "D:/dataset/quora/vector2/quora_duplicate_question_doc2vec_100.vector"
# # word2vecpath = "D:/dataset/cn_word2vec_100.vector"
# datapath = 'D:/dataset/quora/quora_duplicate_questions_Chinese_seg.tsv'
# outfile = 'D:/dataset/quora/quora_duplicate_questions_Chinese_sim_doc2vec.tsv'
# # outfile = 'D:/dataset/quora/quora_duplicate_questions_Chinese_sim_word2vec_1.tsv'
doc2vecpath = "D:/dataset/quora/vector_english/quora_duplicate_question_doc2vec_100.vector"
datapath = 'D:/dataset/quora/quora_duplicate_questions.tsv'
outfile = 'D:/dataset/quora/quora_duplicate_questions_English_sim_doc2vec.tsv'
para = ParaPhrase_word2vec()
qid1, qid2, labels = para.load_data(datapath)
embeddings_index = para.load_doc2vec(word2vecpath=doc2vecpath)
vectors1 = para.sentence_represention(qid1, embeddings_index)
vectors2 = para.sentence_represention(qid2, embeddings_index)
sim = para.consin_distance(vectors1, vectors2)
para.write2file(qid1, qid2, sim, labels, outfile=outfile)得到句子的cosin相似度之后,还可以通过与标注label比较计算匹配的准确率。由于cosin计算得到的是两个句子之间的相似度,而标注label是0或1,所以这里需要设置一个阈值,当相似度大于这个阈值是认为两个句子语义等价(1),否则为0.
#-*- coding: UTF-8 -*-
import os, sys
def get_prf(fpred, thre=0.1):
"""
get Q-A level and Q level precision, recall, fmeasure
"""
right_num = 0
count = 0
with open(fpred, "rb") as f:
for line in f:
count += 1
print count,line
parts = line.split('\r\n')[0].split('\t')
p, l = float(parts[0]), float(parts[1])
if p > thre and l == 1.0:#预测label为1
right_num += 1
elif p < thre and l == 0.0:
right_num += 1
return float(right_num) / count
if __name__ == "__main__":
# refname, predname = sys.argv[1], sys.argv[2]
thre = 0.9
# if len(sys.argv) > 3:
# thre = float(sys.argv[3])
# predname = 'D:/dataset/quora/quora_duplicate_questions_Chinese_sim_doc2vec.tsv'
# predname = 'D:/dataset/quora/quora_duplicate_questions_Chinese_sim_word2vec.tsv'
predname = 'D:/dataset/quora/quora_duplicate_questions_English_sim_doc2vec.tsv'
# predname = 'D:/dataset/quora/quora_duplicate_questions_Chinese_sim_word2vec.tsv'
result = get_prf(predname, thre=thre)
print "WikiQA Question Triggering: %.4f" %(result)
最终的结果如下:
阈值为0.9:
word2vec 0.5629
doc2vec 0.6791
阈值为0.8:
word2vec 0.4258
doc2vec 0.6110
由此可见,doc2vec对句子的表达还是要优于直接使用Word2vec加和求均值的结果的。
具体的代码见我的GitHub,地址为:点击打开链接