利用python爬虫爬取京东商品评论数据,并绘制词云展示。
1. 爬取商品评论数据
在京东商城里搜索三只松鼠,选取一家店铺打开
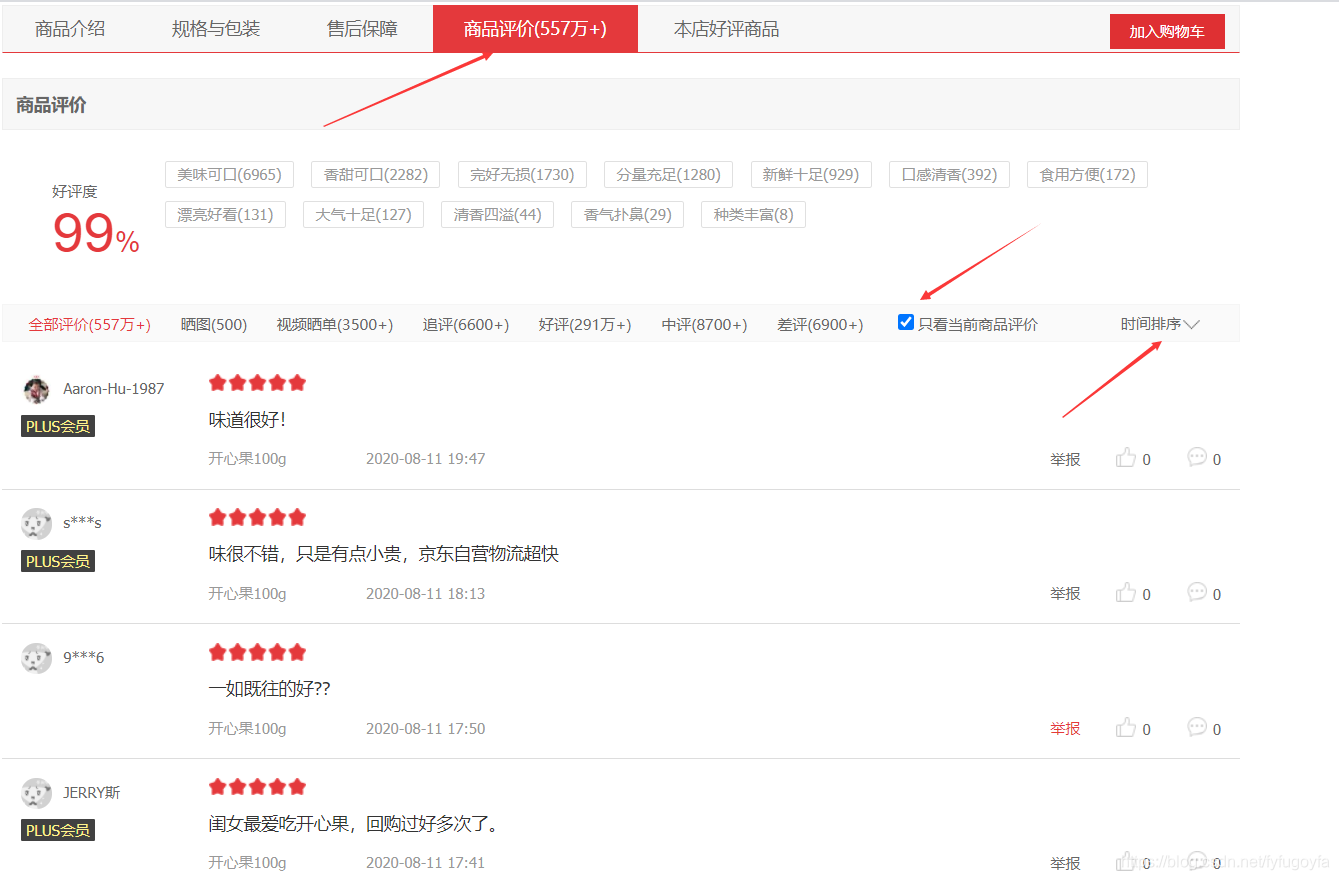
点开商品评价,选择只看当前商品评价,按时间排序查看,发现一页有10条评论。
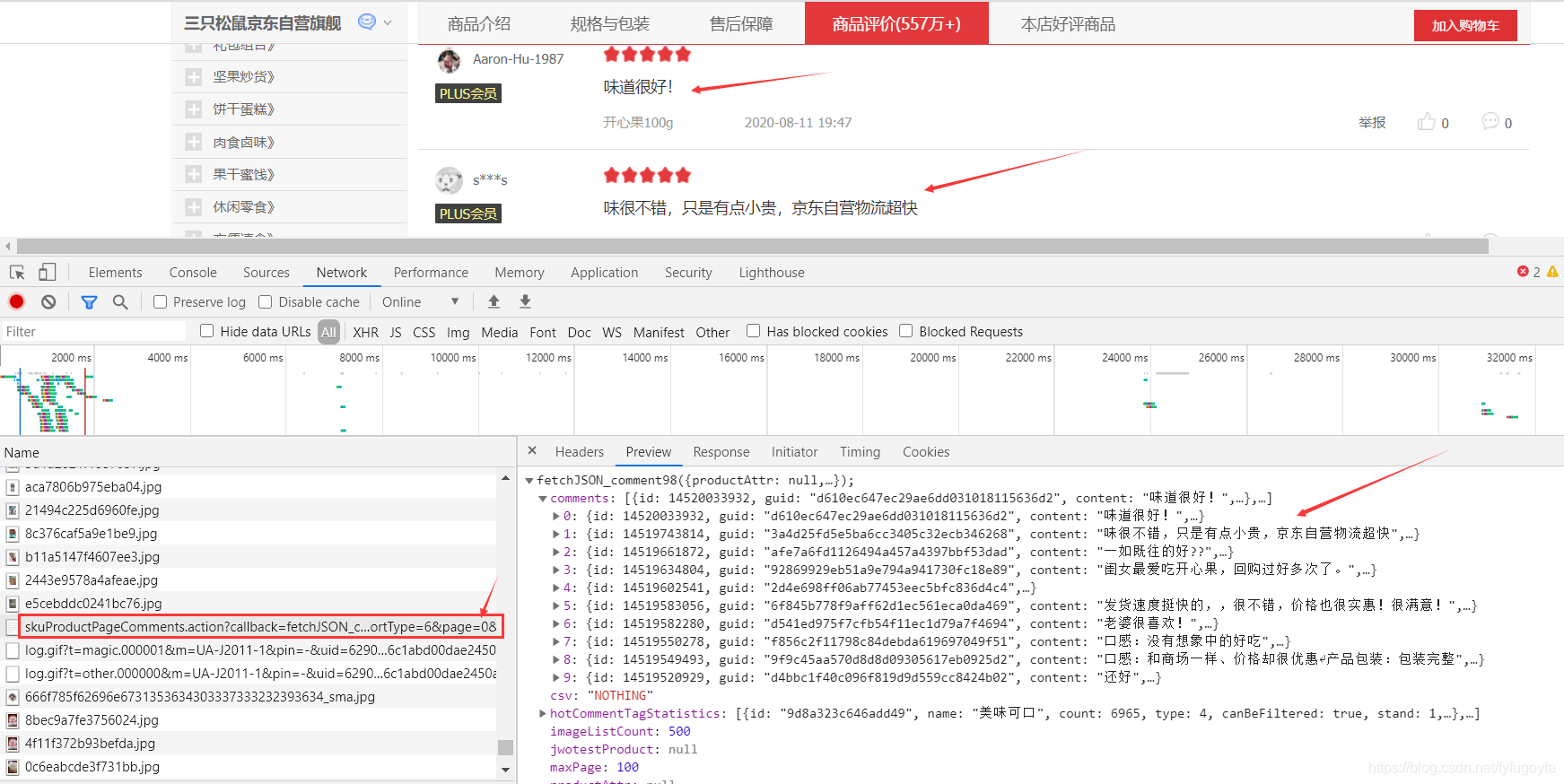
打开谷歌的调试工具,点开Network查看,京东的商品评论信息是存放json包中的。
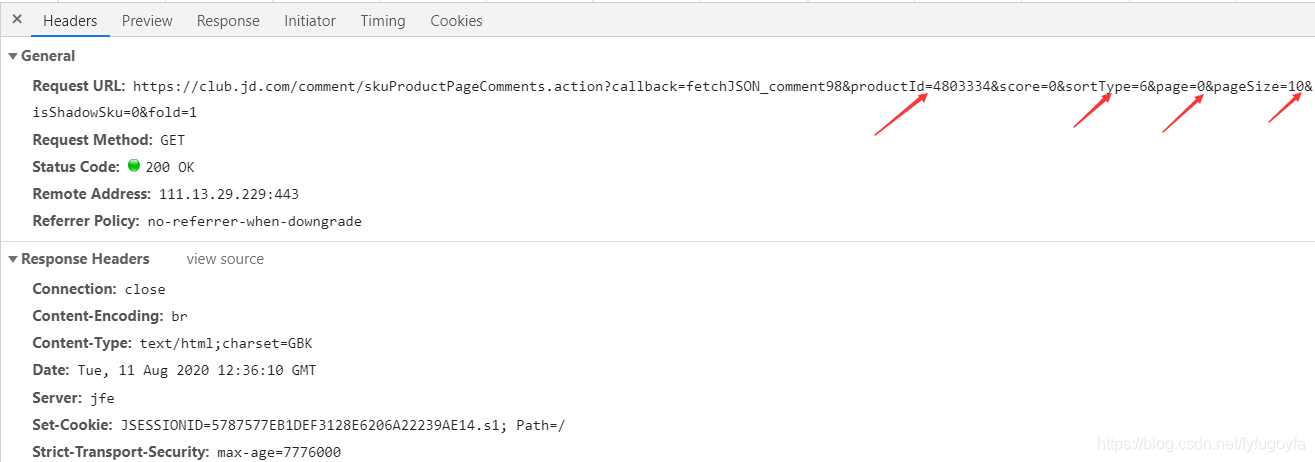
分析Request URL,里面有一些关键参数,productId是这个商品的ID,sortType为评论的排序方式,page为第几页,pageSize表示这一页有10条评论数据,复制Request URL,在浏览器中打开这个链接,可以发现:

改变page参数的值可以实现翻页,效果如下:
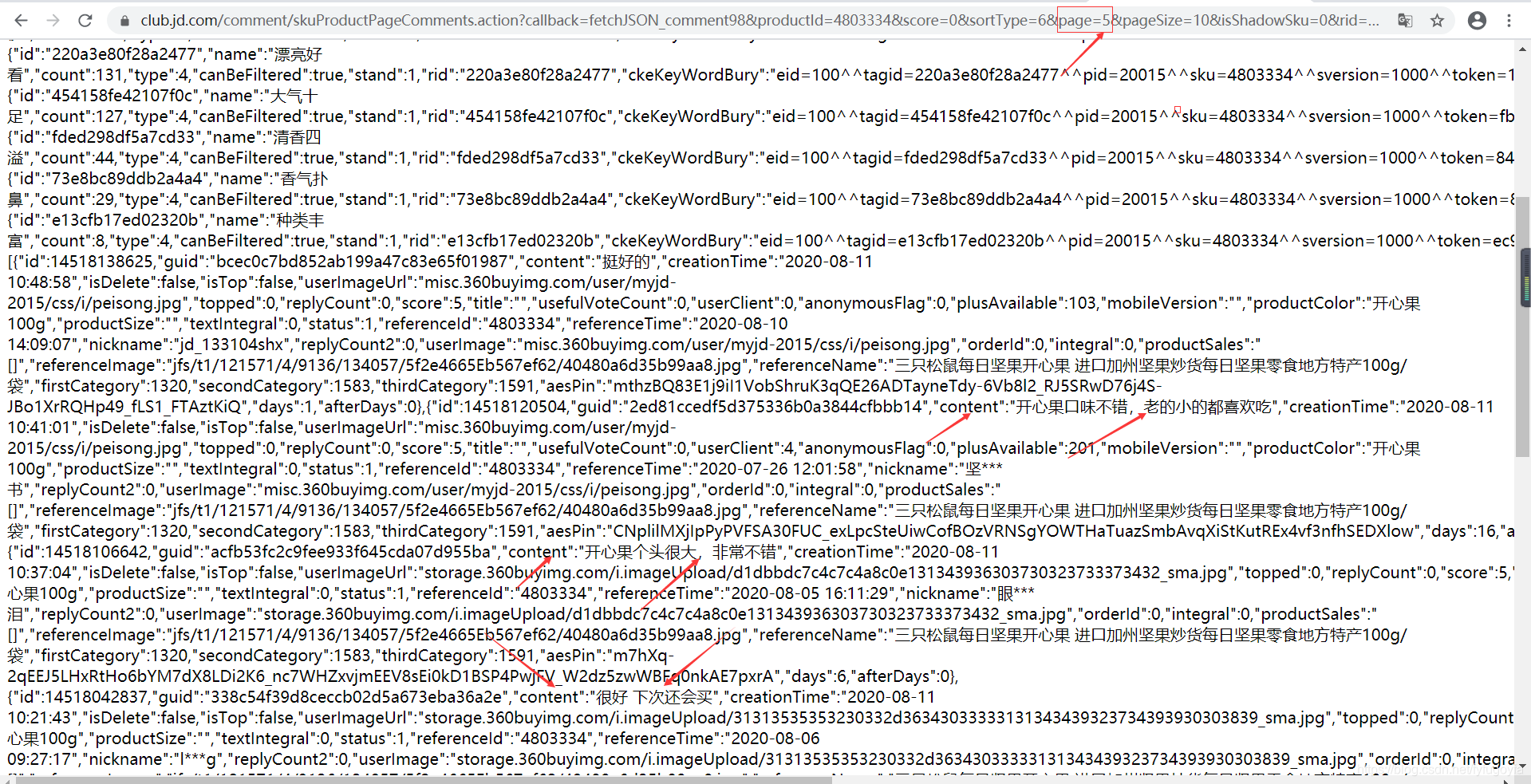
python爬虫,正则匹配提取数据,保存到txt,代码如下:
import asyncio
import aiohttp
import re
import logging
import datetime
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
start = datetime.datetime.now()
class Spider(object):
def __init__(self):
self.semaphore = asyncio.Semaphore(6)
# 伪装请求头
self.header = {
"Host": "club.jd.com",
"Cookie": "shshshfpa=c003ed54-a640-d73d-ba32-67b4db85fd3e-1594895561; shshshfpb=i5%20TzLvWAV56AeaK%20C9q5ew%3D%3D; __jdu=629096461; unpl=V2_ZzNtbUVRFkZ8DUddfRxcBGIEE1hKXhBGIQEVVnNLD1IwBkBeclRCFnQUR1JnGloUZwEZXkZcQxVFCEdkeR1ZAmYBEV1yZ0IXJQ4SXS9NVAZiChAJQAdGFnJfRFQrGlUAMFdACUtVcxZ1OEdkfBpUBG8EF1pCZ3MVfQ92ZDBMAGshQlBtQldEEXAKTlZyGGwEVwMTWUFXQxZ1DkFkMHddSGAAGlxKUEYSdThGVXoYXQVkBBVeclQ%3d; __jdv=122270672|baidu|-|organic|not set|1596847892017; areaId=0; ipLoc-djd=1-72-55653-0; PCSYCityID=CN_0_0_0; __jda=122270672.629096461.1595821561.1596847892.1597148792.3; __jdc=122270672; shshshfp=4866c0c0f31ebd5547336a334ca1ef1d; 3AB9D23F7A4B3C9B=DNFMQBTRNFJAYXVX2JODGAGXZBU3L2TIVL3I36BT56BKFQR3CNHE5ZTVA76S56HSJ2TX62VY7ZJ2TPKNIEQOE7RUGY; jwotest_product=99; shshshsID=ba4014acbd1aea969254534eef9cf0cc_5_1597149339335; __jdb=122270672.5.629096461|3.1597148792; JSESSIONID=99A8EA65B8D93A7F7E8DAEE494D345BE.s1",
"Connection": "keep-alive",
"Referer": "https://item.jd.com/4803334.html",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36"
}
async def scrape(self, url):
async with self.semaphore:
session = aiohttp.ClientSession(headers=self.header)
response = await session.get(url)
result = await response.text()
await session.close()
return result
async def scrape_page(self, page):
url = f'https://club.jd.com/comment/skuProductPageComments.action?callback=fetchJSON_comment98&productId=4803334&score=0&sortType=6&page={page}&pageSize=10&isShadowSku=0&rid=0&fold=1'
text = await self.scrape(url)
await self.parse(text)
async def parse(self, text):
content = re.findall('"guid":".*?","content":"(.*?)"', text)
with open('datas.txt', 'a+') as f:
for con in content:
f.write(con + '\n')
logging.info(con)
def main(self):
# 100页的数据
scrape_index_tasks = [asyncio.ensure_future(self.scrape_page(page)) for page in range(0, 100)]
loop = asyncio.get_event_loop()
tasks = asyncio.gather(*scrape_index_tasks)
loop.run_until_complete(tasks)
if __name__ == '__main__':
spider = Spider()
spider.main()
delta = (datetime.datetime.now() - start).total_seconds()
print("用时:{:.3f}s".format(delta))
2. 词云展示
代码如下:
import jieba
import collections
import re
from wordcloud import WordCloud
import matplotlib.pyplot as plt
with open('datas.txt') as f:
data = f.read()
# 文本预处理 去除一些无用的字符 只提取出中文出来
new_data = re.findall('[\u4e00-\u9fa5]+', data, re.S)
new_data = "/".join(new_data)
# 文本分词
seg_list_exact = jieba.cut(new_data, cut_all=True)
result_list = []
with open('stop_words.txt', encoding='utf-8') as f:
con = f.readlines()
stop_words = set()
for i in con:
i = i.replace("\n", "") # 去掉读取每一行数据的\n
stop_words.add(i)
for word in seg_list_exact:
# 设置停用词并去除单个词
if word not in stop_words and len(word) > 1:
result_list.append(word)
print(result_list)
# 筛选后统计
word_counts = collections.Counter(result_list)
# 绘制词云
my_cloud = WordCloud(
background_color='white', # 设置背景颜色 默认是black
width=800, height=550,
font_path='simhei.ttf', # 设置字体 显示中文
max_font_size=112, # 设置字体最大值
min_font_size=12, # 设置子图最小值
random_state=80 # 设置随机生成状态,即多少种配色方案
).generate_from_frequencies(word_counts)
# 显示生成的词云图片
plt.imshow(my_cloud, interpolation='bilinear')
# 显示设置词云图中无坐标轴
plt.axis('off')
plt.show()
运行效果如下:

从词云图中可以看出,好吃、喜欢、不错、开心都是评论数据中词频较高的。