版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/zhangjunbob/article/details/52606854
RCNN学习笔记
一、资源介绍
本篇学习笔记针对《Rich feature hierarchies for accurate object detection and semantic segmentation》这篇paper进行分析。paper地址见点击打开链接。
这篇文章介绍了一种目标检测的方法,作者称为Regions with CNN features(RCNN)。
RCNN的大致步骤如图所示:
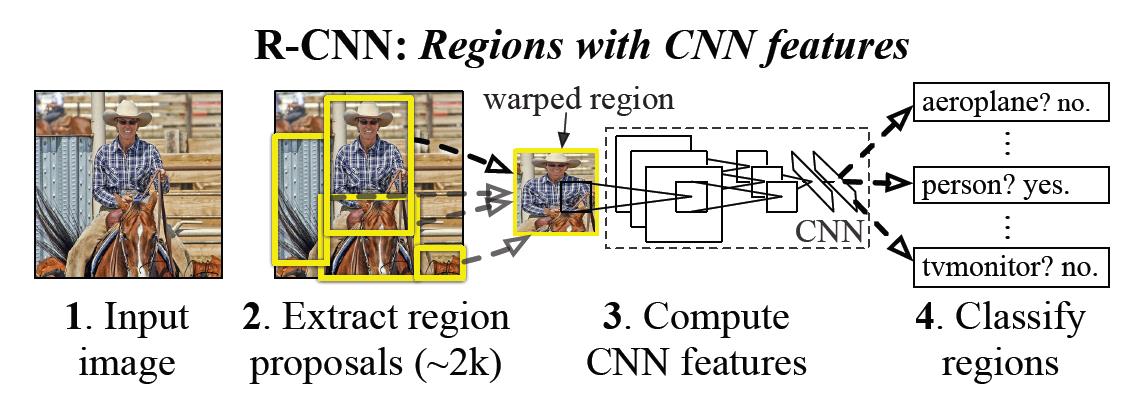
1.输入图像
2.在图像中提取约2000个region proposals(可以理解为提取2000个可能包含需要检测物体的区域)
3.利用已经训练好的CNN网络对于每一个提取出的region得到feature进行评分
4.将图中提取的2000个regions进行svm分类
二、利用R-CNN实现目标检测
2.1 Region proposal 提取区域方案
region proposal的目标就是从输入图像中提取出可能包含检测物体的region,现有的方法有:objectness、selective search 、category-independent object proposals 、constrainedparametric min-cuts (CPMC) 、 multi-scale combinatorialgrouping、和Cires¸an et al。
《Rich feature hierarchies for accurate object detection and semantic segmentation》中在Region proposal方案中选用的是selective search。(seletive search的具体paper参考点击打开链接)
Selective search的重点如下:
2.1.1.采取了hierarchical algorithm分层算法,是一种自底向上的算法。
具体的流程为:
2.1.1.1利用Efficient Graph-Based Image Segmentation点击打开链接这篇论文中的图像分割方法将原始输入图像分割成很多的初始regions的集合
2.1.1.2相邻的region计算相似度,保存在一个相似度集合中。
2.1.1.3在相似度集合中找到最大相似度的两个region,合并成一个region,将这个region存入一个区域集合R中,并更新其与相邻region的相似度产生更新的相似度集合。
2.1.1.4重复上面的步骤知道整个输入图像成为一个region
2.1.1.5区域集合R中的所有区域就是利用分层算法得到的待检测物体的可能位置。
hierarchical algorithm分层算法实现如下:

2.1.2.多样化策略 diversification strategies
在区域相似度的计算中,由于图像的特殊性,需要考虑很多多样化的策略。
在paper中:
2.1.2.1考虑了充足的色彩空间。为了满足不同的场景、光照等条件,作者考虑了8种色彩空间:
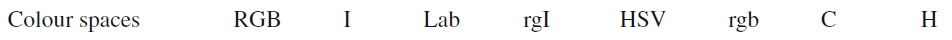
2.1.2.2考虑了充足的相似度计算
对于两个region ri和rj,他们的相似度s计算公式为:
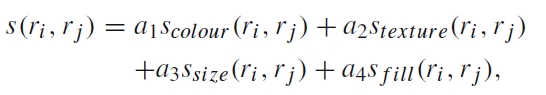
相似度中包括了颜色colour、纹理texture、大小size和吻合度fill四个因素
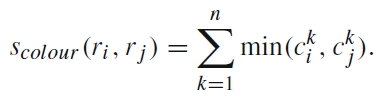
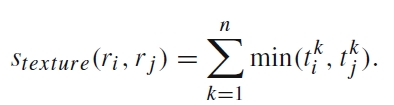
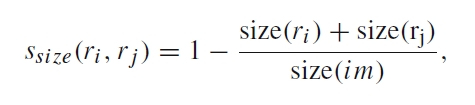
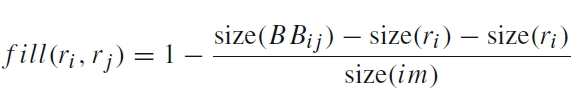
区域提取的过程就告一段落,现在得到了约2000个region,这些region都是可能包含待检测物体的region。
2.2 Feature extraction & SVM特征提取和分类
2.2.1 利用卷积神经网络CNN对于2000个region进行特征提取。得到4096维度的特征向量。
CNN的结构为:输入为227*227的标准RGB图像,网络包含5个卷积层和两个全连接层。
将region转换为227*227的CNN输入时,采取的方法是各向异性缩放warp,选取的padding为16。
效果如下:上一行的padding为0,下一行的padding为16。


对于2000*4096维度的特征向量集合,通过svm分类器对其进行分类。
选取SVM分类得分最高的一些region现实bounding box,从而得到图中的物体检测。
2.3 Training 网络训练
2.3.1
有监督的预训练 supervisedpre-training
paper中作者直接采用的是ILSVRC2012 classification训练库对CNN网络进行了预训练,该网络有大量的数据,可以将输入图像分类到1000个不同分类下。
2.3.2 特定区域的微调 fine-tuning
将网络进行微调,原先的输出为1000个标签,现选取N+1个标签,就是把最后的全连接层的输出改为N+1,其中N为需要识别的物体的个数,1为背景。(假设需要识别图中的汽车和人,则N=2,总共输出3个分类。)判断的依据是,如果region proposal与标定的ground truth的IOU>0.5,则认为是该标签,否则认为是背景。
IOU的定义如下:IOU表示了两个regionA和B的bounding box的重叠度。
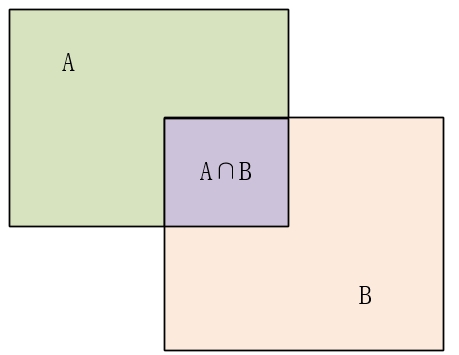
IOU的计算公式:IOU=(A∩B)/(A∪B)
fine-tuning的过程中采用的SGD随机梯度下降的学习率选为0.001,每次训练的过程中选取的样本batchsize为128,其中有32个是正确的待检测物体(正样本),96个是背景region(负样本)。在作者的测试中,将IOU的阈值定为0.3,训练效果最好。也就是说IOU大于0.3的就认为是正样本,小于0.3的就认为是负样本也就是背景。
2.3.3 bounding-box回归
如果ROI与Ground Truth中存在一个长宽或者是比例的变形,那么就需要一个bounding-box的回归使得最终的ROI所对应的bounding-box是最贴合的。
具体的方法是输入检测到的box,回归的是检测到的box的中心点,以及box长和宽到标记的box的映射。
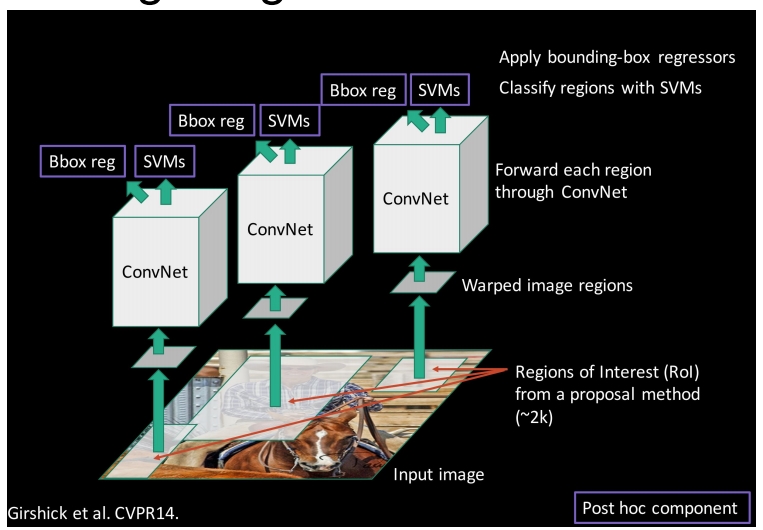
图中的CNN产生的特征向量,需要通过两个步骤,一个是通过SVM产生对应的物体标签,另一个就是这个bounding-box regression来回归得到bounding-box的正确位置。
三、总结
RCNN的过程要点可以简单的表示为:
1.利用selective search方法对输入图像进行region of interest ROI提取
2.将提取的region放入预训练的CNN中进行特征提取
3.将SVM分类器进行fine-tuning,将输出标签改为N+1个
4.训练这个SVM,用训练好的SVM对于CNN出来的特征向量得到检测目标的分类和bounding box的回归
RCNN的主要缺点有:
1.检测速度慢:每一个ROI都需要在CNN网络中进行一次前向传播。
2.训练速度慢:RCNN需要fine-tuning一个SVM分类器,在这之后还要训练一个bounding-box的归回模型。
3.训练过程耗时又占空间:每一个ROI和Feature都需要在训练的过程中存在电脑的内存中,很容易就产生数百G的存储消耗。
因此产生了fast-rcnn和faster-rcnn,今后详细叙述。