版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/zhangjunbob/article/details/52613860
Fast RCNN学习笔记
一、资源介绍
上一篇博客详细介绍了RCNN的过程,虽然RCNN是图像目标检测的开山之作,但是其缺点也很明显,具体表现在:1.训练是一个分段的过程,先训练CNN、然后fine-tuning一个N+1输出的SVM、最后还要训练一个bounding-box的回归。2.训练的时间和空间消耗过大。3.目标检测速度慢,每一个ROI都要经过CNN网络,效率很低。
随后Ross Girshick又提出了新的改进的算法,称为Fast R-CNN,具体paper参考点击打开链接。
相比于RCNN和SPPnet,Fast RCNN改进在一下4点:
1.更高的检测质量。
2.利用多任务损失将训练变为单次训练
3.训练可以更新所有的网络层
4.特征缓存不再需要保存在内存中
Fast RCNN的大致步骤如下:
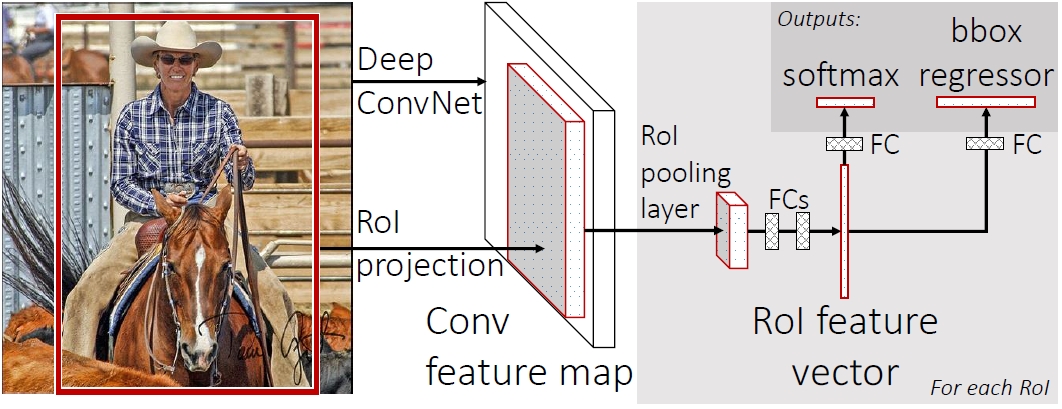
输入一张图片,得到图像中的ROI(方法依旧是ss,selective search),将整个图片放入一个CNN网络中得到一个总的conv feature map。每一个ROI通过ROI pooling层可以在总的feature map中找到对应的固定长度的特征向量。经过两个FC层就可以转变成一个ROI特征向量。该特征向量可以得到两个输出,分别是softmax分类器得到的分类结果和一个bounding-box回归的结果。
二、Fast RCNN结构
2.1 ROI pooling层
ROI pooling层的作用就是让每一个ROI都能在总的conv feature map中找到自己的对应的patch。
具体方法是:
假设一个ROI的尺寸是h*w,需要用max pooling将其池化为一个H*W的map(即用h/H*w/W的窗口滑动进行max pooling),将所有的ROI都pooling到相同的尺寸H*W之后,就可以在总的conv feature map中寻找对应的feature vector。
这一步是fast rcnn的关键,解决了rcnn中需要将每一个ROI都过一遍cnn十分浪费时间的问题。先只需将整个图片过一遍cnn,就可以在feature map中提取出ROI对应的patch。
2.2 初始化pre-trained 网络
利用已经训练好的卷积网络,例如ImageNet、VGG16等,将网络最后一个max pooling层用一个ROI pooling层替换,并且将最后的FC层替换成fit max pooling尺寸的,在VGG16中取H=W=7。
随后将FC层的输出从1000换为N+1层,N为分类类别,1为背景。
最后网络将被调整成可以接纳两个输入更新,分别是图像和RoI。
2.3 Fine-tuning
训练网络的过程可以得到优化。同一张图中的ROI可以共享一个图的Feature map,每一次的随机梯度下降SGD需要N张图片和R个ROI,作者经过试验,发现N=2,R=128时(一次训练两张图,每张图上有128/2 =64个ROi)训练的速度比N=1,R=128(一次训练一张图每张图上128个ROI
)要快64倍。最终选择N=2,R=128。
2.4 多任务损失函数 multi-task loss
fast RCNN有两个输出层,分别对应了ROI对应的分类p,和ROI的bounding-box回归t。
在训练的时候,每一个ROI都与一个ground truth(人为标定的正确的)的分类u和一个ground truth的bounding-box目标v绑定。
作者利用一个损失函数把分类和bounding-box一起考虑了进去。
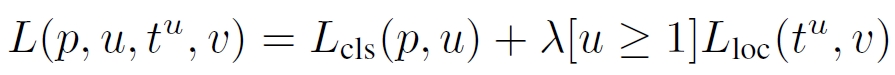
其中Lcls表示class分类的损失函数,Lloc表示bounding-box的损失函数。
分类的损失函数为:
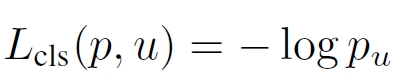
在Fast RCNN中分类不再使用svm,而采用了Softmax。
bounding-box的损失函数为:
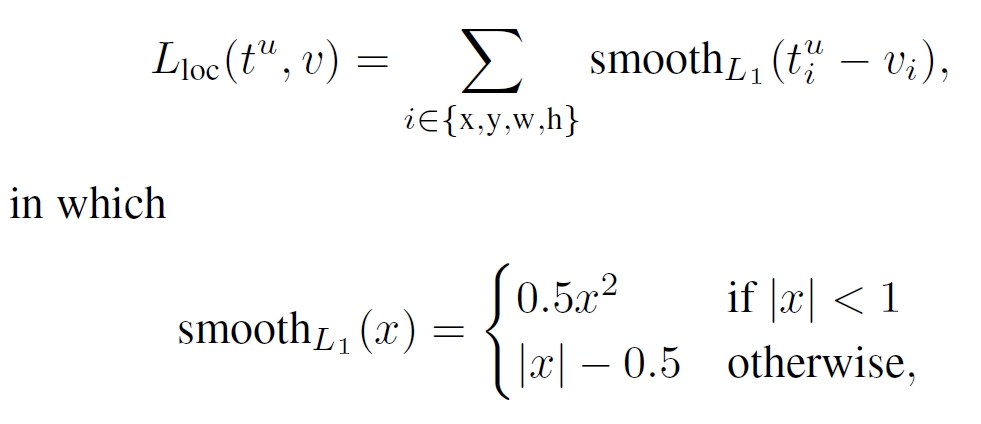
总的loss中的λ控制了两个任务loss的平衡,在所有测试中, λ都取为1。
2.5 SGD的具体参数
作者在paper中详细提及了训练时候参数的设置。
最后的softmax分类器和bounding-box的回归都初始化为一个零均值的高斯分布,标准差分别为0.01和0.001;偏置b都被初始化为0。每一层的权重学习率为1,偏置学习率为2。
2.6 截断奇异值分解 Truncated SVD
传统的图像识别中,FC层的耗时相比于conv层要少很多。但是在目标检测中,由于ROI的数量众多,绝大多数的时间都花费在了后面的FC层中。利用截断奇异值分解可以很有效的降低这个FC所消耗的时间。
假设一个layer的参数为u*v的矩阵W
截断SVD可以表示为如下形式:

U是一个u*t的矩阵,Σt是一个t*t的矩阵,V是一个v*t的矩阵,经过了SVD,可以将u*v个参数转化成 t(u+v)个参数。如果t很小的话,可以大大的降低FC层所用的时间从而降低目标检测的过程。
三、总结
Fast RCNN是在RCNN的基础上进行了改进,将原有的分段的过程进行了合并,不再将所有的ROI都放入CNN计算,而是将整个图片放入cnn中,由ROI pooling得到的映射关系找到ROI对应的feature map。分类函数用softmax分类器替代了svm。在SGD的过程中,loss function也将分类和bounding-box的回归考虑在了一起,降低了训练的时间和空间消耗。最后还提出了利用SGD来进一步降低检测过程的时间。