原文地址:Mask RCNN
源码:matterport - github(基于Python 3、Keras和TensorFlow)
源码解析:TensorFlow实战:Chapter-8上(Mask R-CNN介绍与实现)
Mask RCNN论文简介
Mask R-CNN是基于R-CNN系列、FPN、FCIS等工作之上的,Mask R-CNN的思路很简洁:Faster R-CNN针对每个候选区域有两个输出:种类标签和bbox的偏移量。那么Mask R-CNN就在Faster R-CNN的基础上通过增加一个分支进而再增加一个输出,即物体掩膜。
模型对图片中的每个对象实例生成包围框(bounding boxes)和分割掩(segmentation masks)。基于特征金字塔网络(FPN)和ResNet101的主干(backbone)。
mask-RCNN实例分割框架:

与Faster RCNN等比较及改进
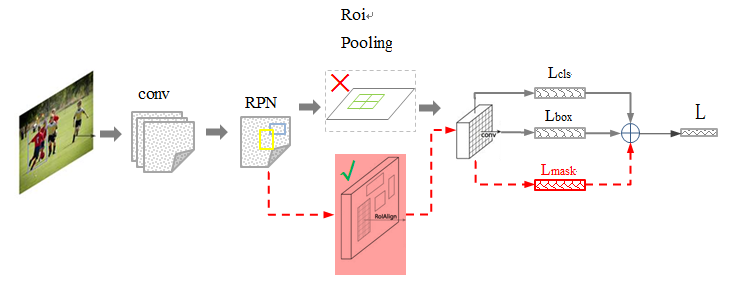
其中 黑色部分为原来的 Faster-RCNN,红色部分为在 Faster网络上的修改:
1)将 Roi Pooling 层替换成了 RoiAlign;
2)添加并列的 FCN 层(mask 层);
先来概述一下 Mask-RCNN 的几个特点(来自于 Paper 的 Abstract):
1)在边框识别的基础上添加分支网络,用于 语义Mask 识别;
2)训练简单,相对于 Faster 仅增加一个小的 Overhead,可以跑到 5FPS;
3)可以方便的扩展到其他任务,比如人的姿态估计 等;
4)不借助 Trick,在每个任务上,效果优于目前所有的 single-model entries;
包括 COCO 2016 的Winners。
技术要点
● 技术要点1 - 强化的基础网络
通过 ResNeXt-101+FPN 用作特征提取网络,达到 state-of-the-art 的效果。
● 技术要点2 - ROIAlign
采用 ROIAlign 替代 RoiPooling(改进池化操作)。引入了一个插值过程,先通过双线性插值到14*14,再 pooling到7*7,很大程度上解决了仅通过 Pooling 直接采样带来的 Misalignment 对齐问题。
PS: 虽然 Misalignment 在分类问题上影响并不大,但在 Pixel 级别的 Mask 上会存在较大误差。
后面我们把结果对比贴出来(Table2 c & d),能够看到 ROIAlign 带来较大的改进,可以看到,Stride 越大改进越明显。
● 技术要点3 - Loss Function
每个 ROIAlign 对应 K * m^2 维度的输出。K 对应类别个数,即输出 K 个mask,m对应 池化分辨率(7*7)。Loss 函数定义:
Lmask(Cls_k) = Sigmoid (Cls_k), 平均二值交叉熵 (average binary cross-entropy)Loss,通过逐像素的 Sigmoid 计算得到。通过对每个 Class 对应一个 Mask 可以有效避免类间竞争(其他 Class 不贡献 Loss )。
实现细节
超参数的设置与现有的Fast/Faster R-CNN基本一致。虽然这些设定是在原始论文中是用于目标检测的,但是我们发现我们的目标分割系统也是可以用。
训练:与Faster R-CNN中的设置一样,如果RoI与真值框的IoU不小于0.5,则为正样本,否则为负样本。掩码损失函数LmaskLmask仅在RoI的正样本上定义。掩码目标是RoI及其对应的真值框之间的交集的掩码。
我们采用以图像为中心的训练1。图像被缩放(较短边)到800像素12。批量大小为每个GPU2个图像,每个图像具有N个RoI采样,正负样本比例为1:31。 C4下层网络的N为64(如1 2),FPN为512(如12)。我们使用8个GPU训练(如此有效的批量大小为16)160k次迭代,学习率为0.02,在120k次迭代时学习率除以10。我们使用0.0001的权重衰减和0.9的动量。
RPN锚点跨越5个尺度和3个纵横比12。为方便消融,RPN分开训练,不与Mask R-CNN共享特征。本文中的,RPN和Mask R-CNN具有相同的下层网络,因此它们是可共享的。
测试:在测试时,C4下层网络(如2)中的候选数量为300,FPN为1000(如12)。我们在这些候选上执行检测框预测分支,然后执行非极大值抑制29。然后将掩码分支应用于评分最高100个检测框。尽管这与训练中使用的并行计算不同,但它可以加速推理并提高精度(由于使用更少,更准确的RoI)。掩码分支可以预测每个RoI的KK个掩码,但是我们只使用第kk个掩码,其中kk是分类分支预测的类别。然后将m×mm×m浮点数掩码输出的大小调整为RoI大小,并使用阈值0.5将其二值化。
请注意,由于我们仅在前100个检测框中计算掩码,Mask R-CNN将边缘运行时间添加到其对应的Faster R-CNN版本(例如,相对约20%)。
实验结果


消融实验结果

结构:表a显示了具有各种使用不同下层网络的Mask R-CNN。它受益于更深层次的网络(50对比101)和高级设计,包括FPN和ResNeXt(我们使用64×4d64×4d的普通的ResNeXt)。我们注意到并不是所有的框架都会从更深层次的或高级的网络中自动获益。
独立与非独立掩码: Mask R-CNN解耦了掩码和类预测:由于现有的检测框分支预测类标签,所以我们为每个类生成一个掩码,而不会在类之间产生竞争(通过像素级Sigmoid和二值化损失)。在表b中,我们将其与使用像素级Softmax和非独立损失的方法进行比较(常用于FCN3)。这些方法将掩码和类预测的任务结合,导致了掩码AP(5.5个点)的严重损失。这表明,一旦目标被归类(通过检测框分支),就可以预测二值化掩码而不用担心类别,这样可以使模型更容易训练。
类相关与类无关掩码:我们默认预测类相关的掩码,即每类一个m×mm×m掩码。有趣的是,这种方法与具有类别无关掩码的Mask R-CNN(即,预测单个m×mm×m输出而不论是那一类)几乎同样有效:对于ResNet-50-C4掩码AP为29.7,而对于类相关的对应的模型AP为30.3 。这进一步突出了我们的方法中的改进:解耦了分类和分割。
RoIAlign:表c显示了对我们提出的RoIAlign层的评估。对于这个实验,我们使用的下层网络为ResNet-50-C4,其步进为16。RoIAlign相对RoIPool将AP提高了约3个点,在高IoU(AP75AP75)结果中增益更多。 RoIAlign对最大/平均池化不敏感,我们在本文的其余部分使用平均池化。
此外,我们与采用双线性采样的MNC 中提出的RoIWarp进行比较。如实验:目标分割所述,RoIWarp仍然四舍五入了RoI,与输入失去了对齐。从表c可以看出,RoIWarp与RoIPool效果差不多,比RoIAlign差得多。这突出表明正确的对齐是关键。
我们还使用ResNet-50-C5下层网络评估了RoIAlign,其步进更大,达到了32像素。我们使用与相同的上层网络,因为res5不适用。表d显示,RoIAlign将掩码AP提高了7.3个点,并将掩码的AP75AP75 提高了10.5个点(相对改善了50%)。此外,我们注意到,与RoIAlign一样,使用步幅为32的C5特征(30.9 AP)比使用步幅为16的C4特征更加精准。 RoIAlign在很大程度上解决了使用大步进特征进行检测和分割的长期挑战。
最后,当与FPN一起使用时,RoIAlign显示出1.5个掩码AP和0.5个检测框AP的增益,FPN具有更精细的多级步长。对于需要更精细对准的关键点检测,即使使用FPN,RoIAlign也显示出很大的增益。
掩码分支:分割是一个像素到像素的任务,我们使用FCN来利用掩码的空间布局。在表e中,我们使用ResNet-50-FPN下层网络来比较多层感知机(MLP)和FCN。使用FCN可以提供超过MLP 2.1个点的AP增益。为了与与MLP进行公平的比较,FCN的上层网络的卷积层没有被预训练。