作者:Jeff Barr
时至今日,观察并收集大量与特定系统、产品或者流程相关的运行数据相对而言已经较为简单,其成本也变得更易于接受。
不出所料,总量庞大的信息被淹没在了数以GB计的客户采购数据、网站导航路径乃至电子邮件响应等类型的数据当中。不过好消息是,全部上述数据都能够在得到适当分析的前提下带来良好的统计结果,进而被用于更为高效地制定商业决策。然而坏消息也同样存在:大家需要找到拥有丰富机器学习相关知识的出色数据科学人才,祈祷自己的基础设施有能力支持他们所选用的工具集合,最后还要期待着这些工具集合能够提供生产环境所必需的切实可靠性与可扩展能力。
机器学习(通常被简称为ML)科学能够提供运行分析流程并保证结果具备现实意义的数学基础。它可以帮助大家从纷繁复杂的各类数据当中找到并整理出既定模式以及不同内容之间的相互关联,进而以此为基础将其切实转化为可资运用的高质量预测结果。只要使用得当,机器学习机制能够作为一系列系统方案的起效基础,其中包括欺诈检测(判断相关事务是否合法)、需求预测(帮助销售人员作出准确的销量预测)以及广告定向(弄清不同广告内容应该展示给哪些用户)等等。
Amazon机器学习简介
今天我们要介绍的是Amazon Machine Learning方案。这项全新AWS服务旨在帮助大家利用自己已经收集到的各类数据对现有决策制定机制加以改进。大家可以利用规模庞大的数据集合构建并具体调整预测模型,而后利用Amazon Machine Learning以规模化方式作出预测(包括以批量方式或者以实时方式)。即使大家并不具备统计学方面的丰富知识储备或者不打算亲手安装、运行并维护自己的处理及存储基础设施,这套机器学习解决方案仍然能够为各位带来切实助益。
我会在一分钟之后正式切入与之相关的具体细节。不过在此之前,我打算首先带大家回顾之后可能会涉及的一部分术语及概念。有了解了这些背景知识之后,相信大家一定能更充分地了解机器学习的既定目标以及如何充分运用由其带来的巨大能力。
机器学习技术简介
为了从机器学习技术当中切实受益,大家需要先对现有数据进行整理以用于演练及早期演练。比较理想的办法是利用数据库或者电子表格中的数据行作为演练素材。每一行代表着单一一个数据元素(一项采购额、一条出货量或者一个分类项等)。数据列则用于表示该元素的属性,例如客户邮政编码、采购价格、信用卡类别以及型项大小等等。
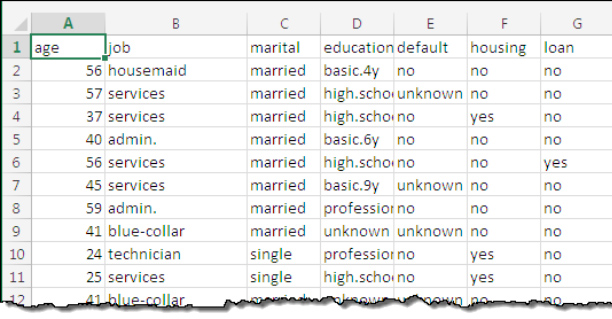
用于演练的数据中必须包含实际结果的对应范例。举例来说,如果大家的数据行表示的是已经完成的事务属于合法或者欺诈类型,那么每一行就必须具备对应列来表示该结果,这也就是我们经常说的目标变量。该数据的作用在于创建一套机器学习模型,从而在待处理的事务中出现新数据时对其进行表示。Amazon MachineLearning支持三种不同预测类型:二进制类型、多类类型以及回归。接下来让我们一一了解其作用:
二进制类型的作用是在两种可能的结果当中预测其中一种。例如相关事务是否合法、客户是否会购买这款产品或者送货目标地址是否属于公寓住宅等等。
多类类型的作用是在三种或者更多可能的结果当中预测其中一种,并罗列各种可能性的各自比例。例如该产品属于书籍、影音产品或者是衣着类商品。该电影属于喜剧片、纪录片抑或是恐怖片。哪一种产品类别最可能受到客户的喜爱等等。
回归的作用是预测一项数字性结果。例如我们应该在库存当中准备多少台28英寸显示器、我们应当为其设置怎样的销售价格、其中有多大比例可能会以礼品的形式被售出等等。
一套经过妥善调谐的模型能够被用于回答前面提到的任意一种问题。在某些情况下,大家不妨利用同样的演练型数据构建两种甚至更多参考模型。
大家应当在计划中指定一部分时间来扩充现有数据内容,从而确保其能够确切匹配演练流程中的实际需要。举个简单的例子,大家在起步阶段可能只需要考虑以邮政编码或者邮递区号为对象的地置数据。但经过一系列分析之后,大家很可能发现自己可以利用包含有更宏观或者更具体信息的其它定位表现方式来进一步提高结果的准确程度。机器学习演练流程具备迭代性,大家应该在计划中划拨一部分时间来了解并评估自己的初始分析结果,而后利用它们扩充自己的现有数据。
大家可以选择一组经过计算得出并能够切实使用的性能水平指标,并将其导入自己的每一套模型以了解后者给出的分析结果的实际质量。举例来说,曲线下面积(简称AUC)指标用于监控一种二进制类型的性能水平。这项具体数字在0.0到1.0之间波动的浮点值能够表示对应模型在对全新数据内容进行预测分析时,给出正确答案的具体比率。当该模型的分析质量提升时,相关值会由0.5向1.0趋近。事实上,0.5这一得分意味着该模型的分析水平基本相当于随机猜测,但0.9则代表着这套模型在大多数情况下都能给出相当准确的分析结果。不过如果得分为0.9999,那么大家可别忙着窃喜:这种太过理想的成绩反倒值得加以怀疑,而且很可能代表着所分析的数据对象中存在问题。
当大家构建起自己的二进制预测模型后,接下来要做的是拿出点时间审视其分析结果并利用其中某项已知值作为评估参考素材。这项数值代表着该模型给出正确预测结果的可能性。大家可以根据具体实例中伪阳性(即预测结果应该为假,但实际预测结果却为真)以及伪阴性(即预测结果应当为真,但实际预测结果却为假)的相对重要性水平上调或者下调这一数值。如果大家打算为自己的电子邮件系统构建一套垃圾邮件过滤方案,那么假阴性状况意味着其中一部分垃圾内容仍会被发送到用户的收件箱当中,而假阳性状况则意味着某些合法邮件被丢弃到垃圾箱内。在这种情况下,假阳性无疑是不可接受的。如何在假阳性与假阴性之间取得平衡点将取决于大家的实际业务情况以及计划如何将这套模型引入到生产设置当中。
Amazon Machine Learning实际使用
接下来,让我们开始动手创建一套模型并利用《AmazonMachine Learning开发者指南》当中提供的分步介绍生成相关预测结果。大家可以登录至Amazon网站以查看Amazon Machine Learning相关指导内容,并遵循指南中的分步教程了解整个实现过程。这份指南使用到了来自加州大学欧文分校机器学习库中银行营销数据集的公开性副本内容。我们所构建出的这套模型将用于回应以下问题:“客户是否会订购我们的新产品?”
banking.csv副本并将其上传到了Amazon Simple StorageService(简称S3)当中,而后允许控制台为其添加一套IAM政策、这样Amazon Machine Learning就能对其进行访问了:
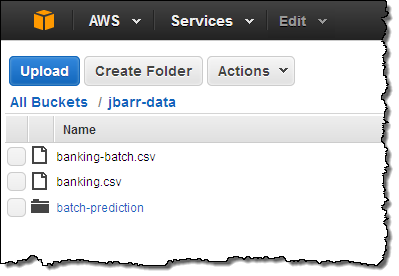
接下来,我在该存储桶内对该项目进行参考并创建了一个Amazon Machine Learning Datasource对象,并为该对象设定了一个名称。这个对象中包含有数据位置、变量名称与类型、目标变量名称以及针对每项变量的描述性统计。Amazon Machine Learning体系中的大部分运作机制都需要参考Datasource。下面我们来分步了解如何完成上述一系列设置工作:
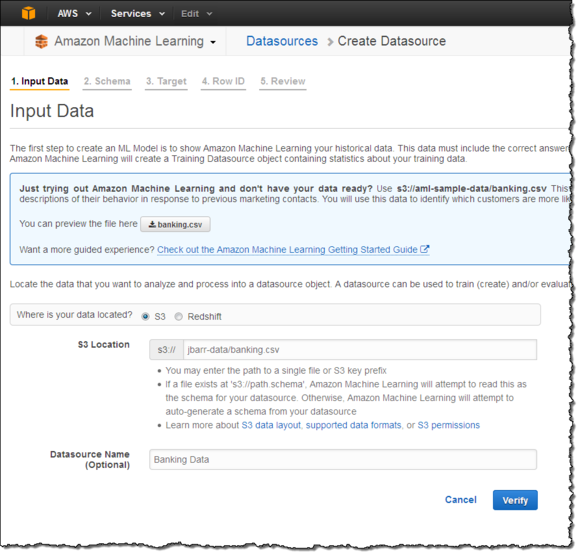
AmazonMachine Learning还能够从AmazonRedShift或者Amazon RDS MySQL数据库当中创建Datasource。在上图所示的界面中选择Redshift选项,接下来我们需要为自己的Amazon Redshift集群输入一个名称,之后还有数据库名称、访问证书以及一项SQL查询。Machine Learning API能够被用于从Amazon RDS或者MySQL数据库当中创建Datasource。
AmazonMachine Learning会打开并扫描该文件,猜测其中的变量类型,而后提取出以下关系模式:
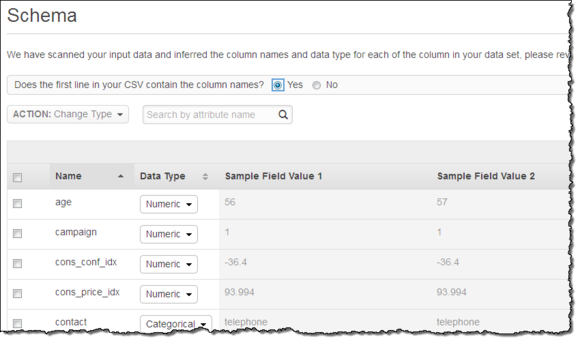
在此次示例中,其提出的所有预测模式都是正确的。如果其中存在错误模式,我们可以选中一行或者多行,而后点击Change Type(变更类型)以修正该错误。
因为我会利用Datasource来创建并评估一套机器学习模型,因此我需要选择演练变量。在这套数据集中,演练变量(y)拥有二进制数据类型,因此该模型会以此为基础利用二进制类型进行生成。
在经过多次点击之后,我已经做好了创建Datasource的一切前期准备: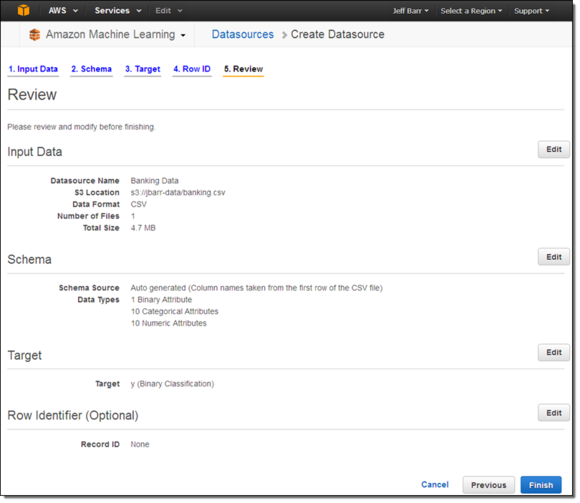
我的Datasource即将在几分钟之后彻底准备就绪:
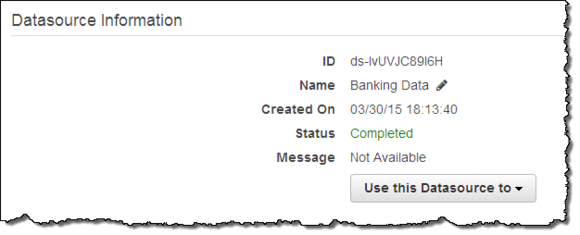
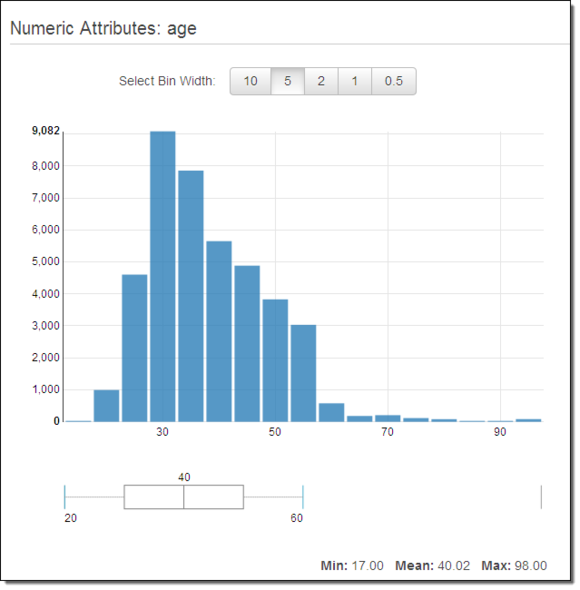
正如在前文中所提到,大家可以通过对数据内容的进一步探究来改进自己的机器学习模型。Amazon Machine Learning控制台为大家提供多种不同工具选项,从而帮助各位利用其了解到更多数据内容。举例来说,大家可以查看某一Datasource当中任意变量的数值分布情况。以下为我在对自己的Datasource进行age(即年龄)变量进行审视时得出的结果:
下一步是创建自己的机器学习模型:
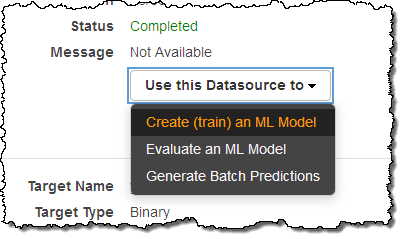
我选择使用默认设置选项。在默认情况下,Amazon Machine Learning利用其中70%数据进行演练,而30%用于进行模型评估:

如果我在以上界面中选择了Custom(自定义)项目,那么我就能够自行对该“配置方案”加以定制,从而根据实际需要指导Amazon Machine Learning如何转换并处理来自Datasource的数据:
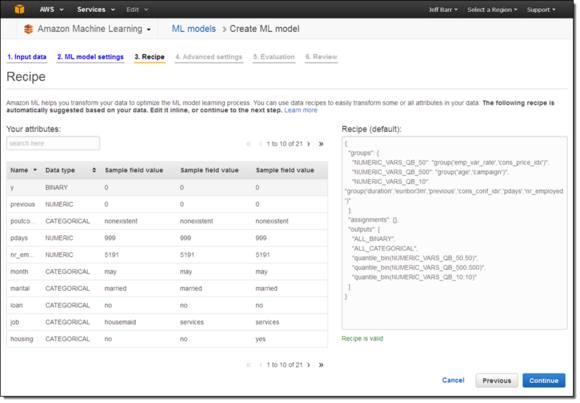
在经过一系列点击操作后,Amazon Machine Learning开始创建我的模型。在这段时间里,我去浇了浇自己的小苗圃。在返回办公桌前时,我发现自己的模型已经创建完毕,如下图所示:

我快速查看了其性能指标:
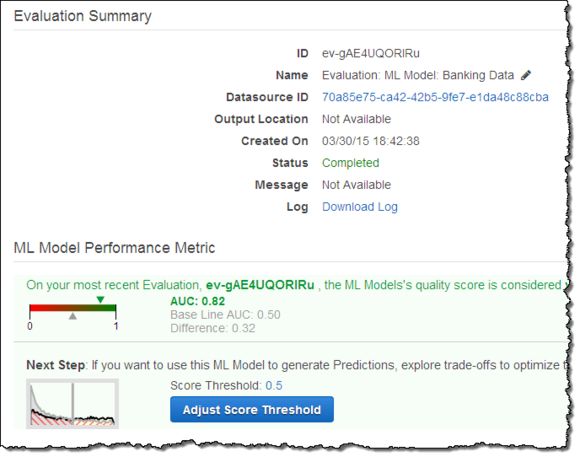
为了选出最佳客户(也就是那些最可能购买产品的群体),我点击了Adjust Score Threshold(调整评分阈值)并不断上调限定值,从而保证只有5%的记录内容能够在这一数值限定条件之下满足预测值y为“1”:
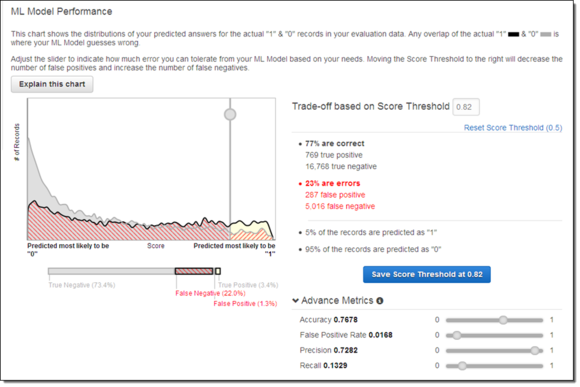
经过这样的设置,只有1.3%的预测结果属于假阳性,而22%属于假阴性,另外77%则属于正确预测结果。我选择将假阳性结果理解为客户认为产品价格过高,并决定上调阈值以避免此类状况。从商业角度来看,这样的设定能帮助我避免将价格太过昂贵的宣传材料交付给“错误”的客户群体手中。
至此我的模型已经构建完成,现在我能够利用它创建批量预测(大家应该还记得,Amazon Machine Learning支持批量与实时两类预测模式)。批量预测模式允许我针对一组观察对象一次性生成预测结果集合。为了完成这项任务,我首先从下图所示的菜单处着手:
我利用上手指南中提供的推荐文件创建了另一个Datasource。与第一个不同,这次使用的文件并不包含任何与y变量相关的数值。
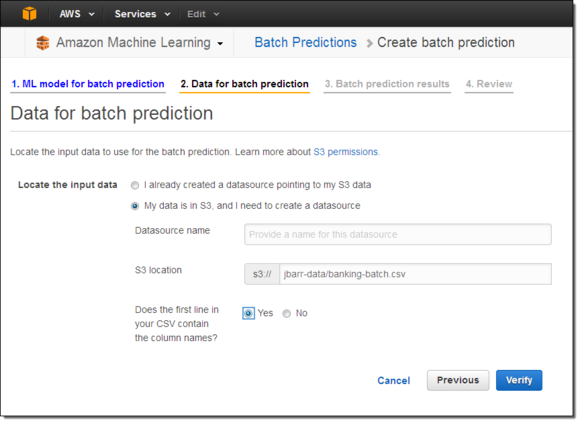
接下来,我在S3当中选定了一个位置来保存预测结果,审查我的选定内容并进行批量预测初始化:
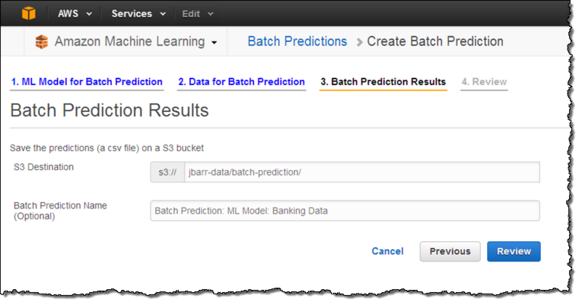
在又一次去苗圃转了几圈后,我的预测方案已经准备就绪。我从存储桶中下载了该文件,进行解压缩,得到的结果如下图所示:
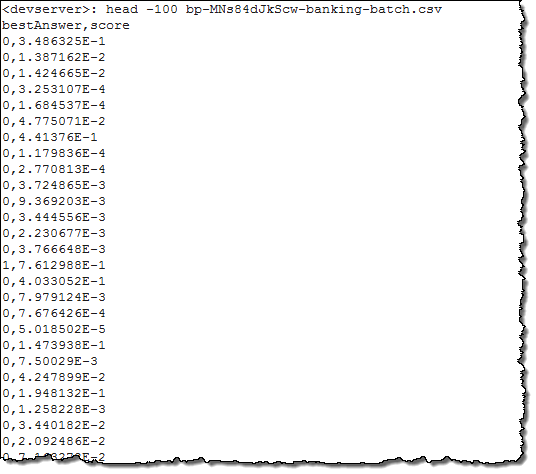
其中各行与原始文件内容一一对应。第一个数值代表着预测得出的y变量(具体计算方式为将预测评分与我在构建该模型时所设定的划分值进行比较),而第二个数值则为实际得分。如果我将行标识符引入其中,那么每个预测值内都将包含一个特殊的“主键”、从而劲旅我将结果与源数据对应起来。
如果打算构建一套实时性应用方案,那么我需要将预测结果作为请求响应周期内的组成部分加以生成,下图所示为我如何将该模型用于处理实时预测工作:

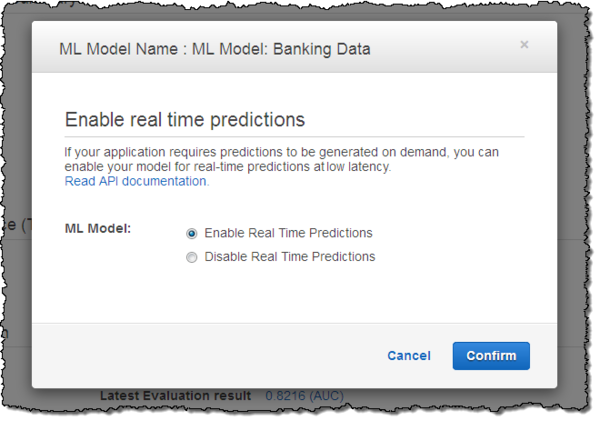
在实时预测能力正式起效后,我可以通过编写代码来调用Amazon Machine Learning中的 Predict函数。以下为一部分Java代码,用于检索与机器学习模型(即代码中的mlModelId)相关的元数据,找到元数据中的服务端点,执行实时预测并显示出预测结果:
AmazonMachineLearningClient client = new AmazonMachineLearningClient();
GetMLModelRequest modelRequest = new GetMLModelRequest()
.withMLModelId(mlModelId);
GetMLModelResult model = client.getMLModel(modelRequest);
String predictEndpoint = model.getEndpointInfo().getEndpointUrl();
PredictRequest predictRequest = new PredictRequest()
.withMLModelId(mlModelId)
.withPredictEndpoint(predictEndpoint)
.withRecord(record);
PredictResult prediction = client.predict(predictRequest);
System.out.println(prediction);上述代码的输出结果如下所示:
{Prediction: {PredictedLabel: 0,PredictedScores: {0=0.10312237},Details: {PredictiveModelType=BINARY, Algorithm=SGD}}}这意味着该机器学习模型的类别为二进制类型,所得出的预测结果为0.10312237,而且该代码在以与该模型相关的预测阈值为基础加以运行时,所得出的预测响应结果为“0”。
感兴趣的朋友可以查看我们的 MachineLearning示例并了解更多与市场营销定位、社交媒体监控以及移动预测相关的示例代码(采用Python与Java语言)。需要了解的相关信息
Amazon Machine Learning目前已经正式上线,身处美国东部(包括弗吉尼亚州北部)地区的朋友们从今天起即可加以使用。
与其它服务一样,Amazon Machine Learning的计费方式仍然采用按使用量收费原则:
· 数据分析、模型演练与模型评估费用为每台计算机每小时0.42美元。
· 批量预测情况下每1000次预测收费0.10美元,不足1000次按1000次取整计算。
· 实时预测情况下每1000次预测收费0.10美元,此外模型当中所配置的第10MB内存容量每小时收费0.001美元。在模型创建过程中,我们会根据大家为该模型指定的、用于管理以及预测性能控制的最大内存容量计费。
· 存储于S3、Amazon RDS以及AmazonRedshift当中的数据需分别进行计费。
了解更多信息
欲了解更多与Amazon Machine Learning相关的细节信息,请大家认真阅读Amazon Machine Learning说明文档。