前言:由于本人今年考研结束后才开始接触ML,入门决定从Andrew Ng的ML课程学起。笔记内容主要来自Andrew Ng教授的讲义和学习视频,以及在学习过程中翻阅的资料,顺序大致按照网易云课堂上的目录,大多是自己觉得有意义的或者难懂的内容,然而其中难免掺杂自己的理解,如有错误,敬请大家批评指正。
一 初识机器学习
这一章主要是对于机器学习的大致介绍,介绍了什么是机器学习、什么是监督/无监督学习并举例帮助同学加以认识。
什么是机器学习呢?
另一个年代近一点的定义,由 Tom Mitchell 提出,来自卡内基梅隆大学,Tom 定义的机器学习是,一个好的学习问题定义如下,他说,一个程序被认为能从经验 E 中学习,解决任务 T,达到性能度量值P,当且仅当,有了经验 E 后,经过 P 评判,程序在处理 T 时的性能有所提升。
比如,在阿法狗“事件”中,经验E就是程序上万次的自我练习的经验,任务T就i是下棋,性能度量值P就是在与一些新的对手比赛时,赢得比赛的概率。
什么是监督学习?什么是无监督学习?
监督学习是指人类教计算机去完成任务,而无监督学习就是人类让计算机自己进行学习。
也可以说,监督学习就是我们给学习算法一个数据集,这个数据集由“正确答案”组成,数据已经进行标注。比如:如果你有标记好的数据,即你已经标注过什么是垃圾邮件什么不是,经过计算机学习以后,他再去区别好是垃圾还是非垃圾邮件,这就是监督学习问题。
而无监督学习没有任何的标签或者是有相同的标签或者就是没标签,已知一个数据集但是不知道怎么处理,也不知道每个数据点是什么,别的什么都不知道,只知道一个数据集。对于这样一个数据集,无监督学习能够判断出数据由两个不同的聚集簇,即这一坨是什么,那一坨是什么,两者是不同的。这也叫做聚类算法。比如:谷歌新闻总是用聚类算法将内容相似的新闻聚类到一起,展示给用户,这就是无监督学习问题。
以下是我目前浅显的认识:
①机器学习就是让机器像人类一样学习,就像是人类学习过程中习惯于寻找模板一样,机器学习也是在通过大量数据寻找某个或者某些个可以解决这类问题的规律(函数、参数)并加以应用
②监督学习就是有lable即人为的标注了lable,人为的已经对其进行了分类;无监督学习反之。
二 单变量线性回归
模型表示
线性回归问题是学习的第一个学习算法。
h表示假设函数,也就是用来进行预测的函数,一般表示为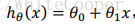
由于只含有一个特征/输入变量,因此这样的问题叫做单变量线性回归问题。
代价函数(Cost Function)
模型所预测的值与训练集中实际值之间的差距(下图中蓝线所指)就是建模误差(modeling error)。
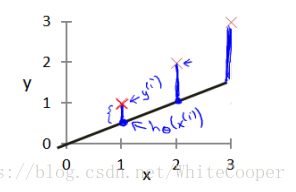
我们的目标便是选择可以使得建模误差的平方和能够最小的模型参数。即使得代价函数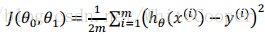
一开始我也不明白为什么代价函数是这个,误差函数为什么要使用平方和,后来查了查资料才知道由于回归函数具有误差,而该误差接近于0,因此满足平均值为0的高斯分布,也就是正态分布。那么x和y的条件概率也就是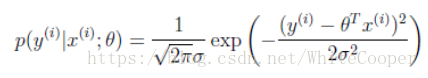
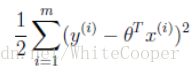
梯度下降(Gradient Descent)
梯度下降是一个用来求函数最小值的算法,我们将使用梯度下降算法来求出代价函数的最小值。
批量梯度下降(Batch Gradient Descent)算法公式为:
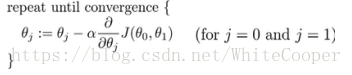
其中a是学习率(learning rate),他决定了我们沿着能够让代价函数下降程度最大的方向向下迈出的步子最大,在批量梯度下降中,我们每一次都同时让所有的参数减去学习速率乘以代价函数的导数。
如果学习速率太小,结果就是只能这样像小宝宝一样一点点地挪动,去努力接近最低点,这样就需要很多步才能到达最低点,所以如果a太小的话,可能会很慢,因为它会一点点挪动,它会需要很多步才能到达全局最低点。
如果a太大,那么梯度下降法可能会越过最低点,甚至可能无法收敛,下一次迭代又移动了一大步,越过一次,又越过一次,一次次越过最低点,直到你发现实际上离最低点越来越远,所以,如果a太大,它会导致无法收敛,甚至发散。
在梯度下降法中,当我们接近局部最低点时,梯度下降法会自动采取更小的幅度,这是因为当我们接近局部最低点时,很显然在局部最低时导数等于零,所以当我们接近局部最低时,导数值会自动变得越来越小,所以梯度下降将自动采取较小的幅度,这就是梯度下降的做法。所以实际上没有必要再另外减小a。
梯度下降算法,你可以用它来最小化任何代价函数J,不只是线性回归中的代价函数J
注:吴恩达老师机器学习课程笔记下载地址:https://github.com/fengdu78/Coursera-ML-AndrewNg-Notes
吴恩达老师深度学习课程笔记下载地址:https://github.com/fengdu78/deeplearning_ai_books