本系列博文介绍常见概率语言模型及其变形模型,主要总结PLSA、LDA及LDA的变形模型及参数Inference方法。初步计划内容如下
第一篇:PLSA及EM算法
第三篇:LDA变形模型-Twitter LDA,TimeUserLDA,ATM,Labeled-LDA,MaxEnt-LDA等
第四篇:基于变形LDA的paper分类总结
第二篇 LDA及Gibbs Sampling
[本文PDF版本下载地址 LDA及Gibbs Sampling-yangliuy]
1 LDA概要
LDA是由Blei,Ng, Jordan 2002年发表于JMLR的概率语言模型,应用到文本建模范畴,就是对文本进行“隐性语义分析”(LSA),目的是要以无指导学习的方法从文本中发现隐含的语义维度-即“Topic”或者“Concept”。隐性语义分析的实质是要利用文本中词项(term)的共现特征来发现文本的Topic结构,这种方法不需要任何关于文本的背景知识。文本的隐性语义表示可以对“一词多义”和“一义多词”的语言现象进行建模,这使得搜索引擎系统得到的搜索结果与用户的query在语义层次上match,而不是仅仅只是在词汇层次上出现交集。
2 概率基础
2.1 随机生成过程及共轭分布
要理解LDA首先要理解随机生成过程。用随机生成过程的观点来看,文本是一系列服从一定概率分布的词项的样本集合。最常用的分布就是Multinomial分布,即多项分布,这个分布是二项分布拓展到K维的情况,比如投掷骰子实验,N次实验结果服从K=6的多项分布。相应的,二项分布的先验Beta分布也拓展到K维,称为Dirichlet分布。在概率语言模型中,通常为Multinomial分布选取的先验分布是Dirichlet分布,因为它们是共轭分布,可以带来计算上的方便性。什么是共轭分布呢?在文本语言模型的参数估计-最大似然估计、MAP及贝叶斯估计一文中我们可以看到,当我们为二项分布的参数p选取的先验分布是Beta分布时,以p为参数的二项分布用贝叶斯估计得到的后验概率仍然服从Beta分布,由此我们说二项分布和Beta分布是共轭分布。这就是共轭分布要满足的性质。在LDA中,每个文档中词的Topic分布服从Multinomial分布,其先验选取共轭先验即Dirichlet分布;每个Topic下词的分布服从Multinomial分布,其先验也同样选取共轭先验即Dirichlet分布。
2.2 Multinomial分布和 Dirichlet分布
上面从二项分布和Beta分布出发引出了Multinomial分布和Dirichlet分布。这两个分布在概率语言模型中很常用,让我们深入理解这两个分布。Multinomial分布的分布律如下

多项分布来自N次独立重复实验,每次实验结果可能有K种,式子中为实验结果向量,N为实验次数,
为出现每种实验结果的概率组成的向量,这个公式给出了出现所有实验结果的概率计算方法。当K=2时就是二项分布,K=6时就是投掷骰子实验。很好理解,前面的系数其实是枚举实验结果的不同出现顺序,即
后面表示第K种实验结果出现了次,所以是概率的相应次幂再求乘积。但是如果我们不考虑文本中词出现的顺序性,这个系数就是1。 本文后面的部分可以看出这一点。显然有
各维之和为1,所有
之和为N。
Dirichlet分布可以看做是“分布之上的分布”,从Dirichlet分布上Draw出来的每个样本就是多项分布的参数向量。其分布律为

为Dirichlet分布的参数,在概率语言模型中通常会根据经验给定,由于是参数向量
服从分布的参数,因此称为“hyperparamer”。
是Dirichlet delta函数,可以看做是Beta函数拓展到K维的情况,但是在有的文献中也直接写成
。根据Dirichlet分布在
上的积分为1(概率的基本性质),我们可以得到一个重要的公式
这个公式在后面LDA的参数Inference中经常使用。下图给出了一个Dirichlet分布的实例

在许多应用场合,我们使用对称Dirichlet分布,其参数是两个标量:维数K和参数向量各维均值. 其分布律如下

关于Dirichlet分布,维基百科上有一张很有意思的图如下

这个图将Dirichlet分布的概率密度函数取对数

并且使用对称Dirichlet分布,取K=3,也就是有两个独立参数  ,分别对应图中的两个坐标轴,第三个参数始终满足
,分别对应图中的两个坐标轴,第三个参数始终满足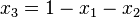 且
且  ,图中反映的是
,图中反映的是 从0.3变化到2.0的概率对数值的变化情况。
从0.3变化到2.0的概率对数值的变化情况。
3 unigram model
我们先介绍比较简单的unigram model。其概率图模型图示如下

关于概率图模型尤其是贝叶斯网络的介绍可以参见 Stanford概率图模型(Probabilistic Graphical Model)— 第一讲 贝叶斯网络基础一文。简单的说,贝叶斯网络是一个有向无环图,图中的结点是随机变量,图中的有向边代表了随机变量的条件依赖关系。unigram model假设文本中的词服从Multinomial分布,而Multinomial分布的先验分布为Dirichlet分布。图中双线圆圈表示我们在文本中观察到的第n个词,
表示文本中一共有N个词。加上方框表示重复,就是说一共有N个这样的随机变量
。
和
是隐含未知变量,分别是词服从的Multinomial分布的参数和该Multinomial分布的先验Dirichlet分布的参数。一般
由经验事先给定,
由观察到的文本中出现的词学习得到,表示文本中出现每个词的概率。
4 LDA
理解了unigram model之后,我们来看LDA。我们可以假想有一位大作家,比如莫言,他现在要写m篇文章,一共涉及了K个Topic,每个Topic下的词分布为一个从参数为的Dirichlet先验分布中sample出来的Multinomial分布(注意词典由term构成,每篇文章由word构成,前者不能重复,后者可以重复)。对于每篇文章,他首先会从一个泊松分布中sample一个值作为文章长度,再从一个参数为
的Dirichlet先验分布中sample出一个Multinomial分布作为该文章里面出现每个Topic下词的概率;当他想写某篇文章中的第n个词的时候,首先从该文章中出现每个Topic的Multinomial分布中sample一个Topic,然后再在这个Topic对应的词的Multinomial分布中sample一个词作为他要写的词。不断重复这个随机生成过程,直到他把m篇文章全部写完。这就是LDA的一个形象通俗的解释。用数学的语言描述就是如下过程

转化成概率图模型表示就是

图中K为主题个数,M为文档总数,是第m个文档的单词总数。
是每个Topic下词的多项分布的Dirichlet先验参数,
是每个文档下Topic的多项分布的Dirichlet先验参数。
是第m个文档中第n个词的主题,
是m个文档中的第n个词。剩下来的两个隐含变量
和
分别表示第m个文档下的Topic分布和第k个Topic下词的分布,前者是k维(k为Topic总数)向量,后者是v维向量(v为词典中term总数)。
给定一个文档集合,是可以观察到的已知变量,
和
是根据经验给定的先验参数,其他的变量
,
和
都是未知的隐含变量,也是我们需要根据观察到的变量来学习估计的。根据LDA的图模型,我们可以写出所有变量的联合分布

那么一个词初始化为一个term t的概率是

也就是每个文档中出现topic k的概率乘以topic k下出现term t的概率,然后枚举所有topic求和得到。整个文档集合的似然函数就是

5 用Gibbs Sampling学习LDA
5.1 Gibbs Sampling的流程
从第4部分的分析我们知道,LDA中的变量,
和
都是未知的隐含变量,也是我们需要根据观察到的文档集合中的词来学习估计的,那么如何来学习估计呢?这就是概率图模型的Inference问题。主要的算法分为exact inference和approximate inference两类。尽管LDA是最简单的Topic Model, 但是其用exact inference还是很困难的,一般我们采用approximate inference算法来学习LDA中的隐含变量。比如LDA原始论文Blei02中使用的mean-field variational expectation maximisation 算法和Griffiths02中使用的Gibbs Sampling,其中Gibbs Sampling 更为简单易懂。
Gibbs Sampling 是Markov-Chain Monte Carlo算法的一个特例。这个算法的运行方式是每次选取概率向量的一个维度,给定其他维度的变量值Sample当前维度的值。不断迭代,直到收敛输出待估计的参数。可以图示如下

初始时随机给文本中的每个单词分配主题,然后统计每个主题z下出现term t的数量以及每个文档m下出现主题z中的词的数量,每一轮计算
 ,即排除当前词的主题分配,根据其他所有词的主题分配估计当前词分配各个主题的概率。当得到当前词属于所有主题z的概率分布后,根据这个概率分布为该词sample一个新的主题
,即排除当前词的主题分配,根据其他所有词的主题分配估计当前词分配各个主题的概率。当得到当前词属于所有主题z的概率分布后,根据这个概率分布为该词sample一个新的主题。然后用同样的方法不断更新下一个词的主题,直到发现每个文档下Topic分布
和每个Topic下词的分布
收敛,算法停止,输出待估计的参数
和
,最终每个单词的主题
也同时得出。实际应用中会设置最大迭代次数。每一次计算
的公式称为Gibbs updating rule.下面我们来推导LDA的联合分布和Gibbs updating rule。
5.2 LDA的联合分布
由LDA的概率图模型,我们可以把LDA的联合分布写成

第一项和第二项因子分别可以写成


可以发现两个因子的展开形式很相似,第一项因子是给定主题Sample词的过程,可以拆分成从Dirichlet先验中SampleTopic Z下词的分布和从参数为
的多元分布中Sample词这两个步骤,因此是Dirichlet分布和Multinomial分布的概率密度函数相乘,然后在
上积分。注意这里用到的多元分布没有考虑词的顺序性,因此没有前面的系数项。
表示term t被观察到分配topic z的次数,
表示topic k分配给文档m中的word的次数.此为这里面还用到了2.2部分中导出的一个公式
因此这些积分都可以转化成Dirichlet delta函数,并不需要算积分。第二个因子是给定文档,sample当前词的主题的过程。由此LDA的联合分布就可以转化成全部由Dirichlet delta函数组成的表达式

这个式子在后面推导Gibbs updating rule时需要使用。
5.3 Gibbs updating rule
得到LDA的联合分布后,我们就可以推导Gibbs updating rule,即排除当前词的主题分配,根据其他词的主题分配和观察到的单词来计算当前词主题的概率公式

里面用到了伽马函数的性质

同时需要注意到

这一项与当前词的主题分配无关,因为无论分配那个主题,对所有k求和的结果都是一样的,区别只在于拿掉的是哪个主题下的一个词。因此可以当成常量,最后我们只需要得到一个成正比的计算式来作为Gibbs updating rule即可。
5.4 Gibbs sampling algorithm
当Gibbs sampling 收敛后,我们需要根据最后文档集中所有单词的主题分配来计算和
,作为我们估计出来的概率图模型中的隐含变量。每个文档上Topic的后验分布和每个Topic下的term后验分布如下

可以看出这两个后验分布和对应的先验分布一样,仍然为Dirichlet分布,这也是共轭分布的性质决定的。
使用Dirichlet分布的期望计算公式

我们可以得到两个Multinomial分布的参数和
的计算公式如下

综上所述,用Gibbs Sampling 学习LDA参数的算法伪代码如下

关于这个算法的代码实现可以参见
* yangliuy's LDAGibbsSampling https://github.com/yangliuy/LDAGibbsSampling
* Gregor Heinrich's LDA-J
* Yee Whye Teh's Gibbs LDA Matlab codes
* Mark Steyvers and Tom Griffiths's topic modeling matlab toolbox
* GibbsLDA++
6 参考文献及推荐Notes
本文部分公式及图片来自 Parameter estimation for text analysis,感谢Gregor Heinrich详实细致的Technical report。 看过的一些关于LDA和Gibbs Sampling 的Notes, 这个是最准确细致的,内容最为全面系统。下面几个Notes对Topic Model感兴趣的朋友也推荐看一看。
[1] Christopher M. Bishop. Pattern Recognition and Machine Learning (Information Science and Statistics). Springer-Verlag New York, Inc., Secaucus, NJ, USA, 2006.
[2] Gregor Heinrich. Parameter estimation for text analysis. Technical report, 2004.
[3] Wang Yi. Distributed Gibbs Sampling of Latent Topic Models: The Gritty Details Technical report, 2005.
[4] Wayne Xin Zhao, Note for pLSA and LDA, Technical report, 2011.
[5] Freddy Chong Tat Chua. Dimensionality reduction and clustering of text documents.Technical report, 2009.
[6] Wikipedia, Dirichlet distribution , http://en.wikipedia.org/wiki/Dirichlet_distribution