一、模型
随机负采样方法,是后来对word2vec输出层做的一种改进,舍弃复杂的层次分类和huffman树
在已知词w上下文的情况下,对应的输出正样本就是w,负样本就是剩下的所有词,非常多,所以我们用某种方法,采样很小的部分,集合为NEG(w)。每个词u都有自己的辅助参数θ
我们希望最大化的函数为,正样本的概率尽可能大,负样本的概率尽可能小
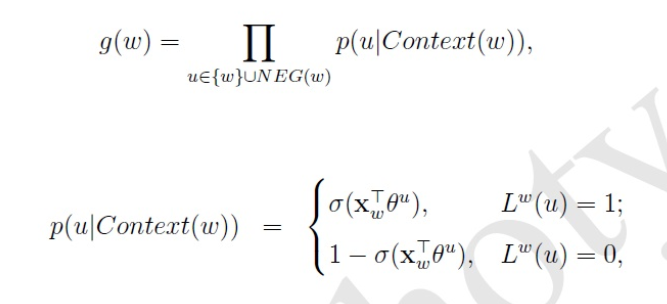
对它取对数就得到损失函数
二、负采样方法
采样方法有很多,大致要求是,高频词被采到的概率大一些,因此叫“带权采样问题”。
一、模型
随机负采样方法,是后来对word2vec输出层做的一种改进,舍弃复杂的层次分类和huffman树
在已知词w上下文的情况下,对应的输出正样本就是w,负样本就是剩下的所有词,非常多,所以我们用某种方法,采样很小的部分,集合为NEG(w)。每个词u都有自己的辅助参数θ
我们希望最大化的函数为,正样本的概率尽可能大,负样本的概率尽可能小
对它取对数就得到损失函数
二、负采样方法
采样方法有很多,大致要求是,高频词被采到的概率大一些,因此叫“带权采样问题”。