1、主题模型 LDA
- 文本类
- 社交
- 推荐
1.1 Introduction
-
有大量的文本资料
-
LDA接受的最小单元是document
-
学习出每个文本的主题
-
设定超参数K
-
output:每个文档会有一个概率的分布,主题分布,选择概率最大的簇作为当前文档分类后的主题。 θ \theta θ

-
词主题:在每个主题下,每个单词出现的概率有多大。每个单词在每个主题下出现的概率。 ϕ \phi ϕ
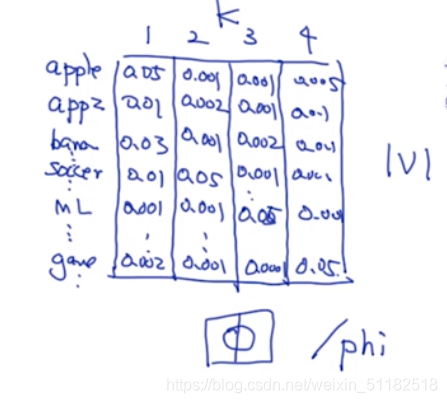
-
Topic 是一个隐变量。
-
对于词主题,把每一个簇中出现概率最大的几个单词拿出来,查看它们的类别,那么簇有很大的概率属于这一个类别。
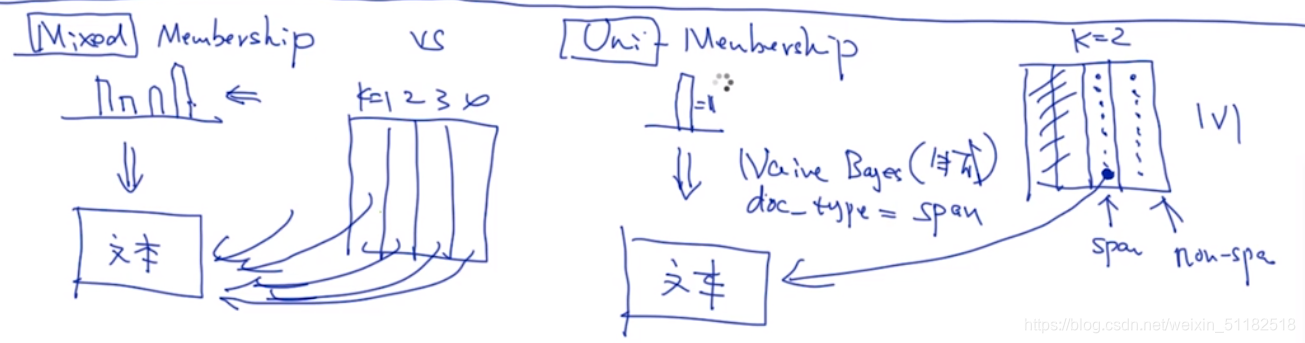
朴素贝叶斯与LDA的区别
朴素贝叶斯每次只考虑当前的一个topic,只考虑对于当前topic中的词对于topic的影响。
2、不同模型的范畴 Model estimation
贝叶斯模型的定义:
MLE和MAP的都是频率派
通过学习估算出一个最优解
1、MLE
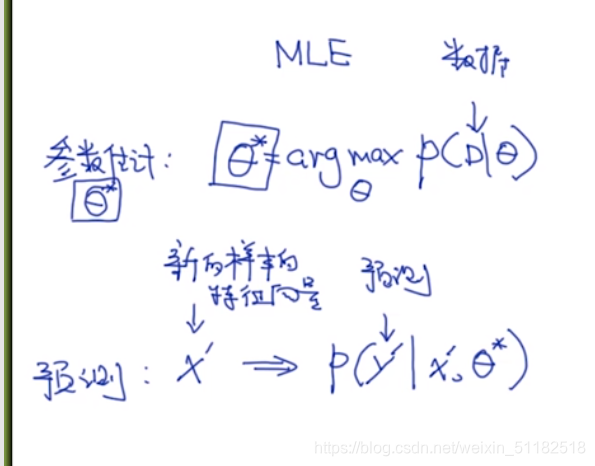
2、MAP:后验概率 既考虑likelihood也考虑先验概率

3、Bayesian
不是估计哪个参数最好,计算所有可能的 θ \theta θ求积分
在训练值已知的情况下,预测出 θ \theta θ的分布。
贝叶斯模型的核心:计算
p ( θ ∣ D ) p(\theta|D) p(θ∣D)的分布概率

3、LDA 预测的过程
计算训练集中所有的模型参数的可能的是很困难的,所以使用蒙特卡洛方法进行近似采样。
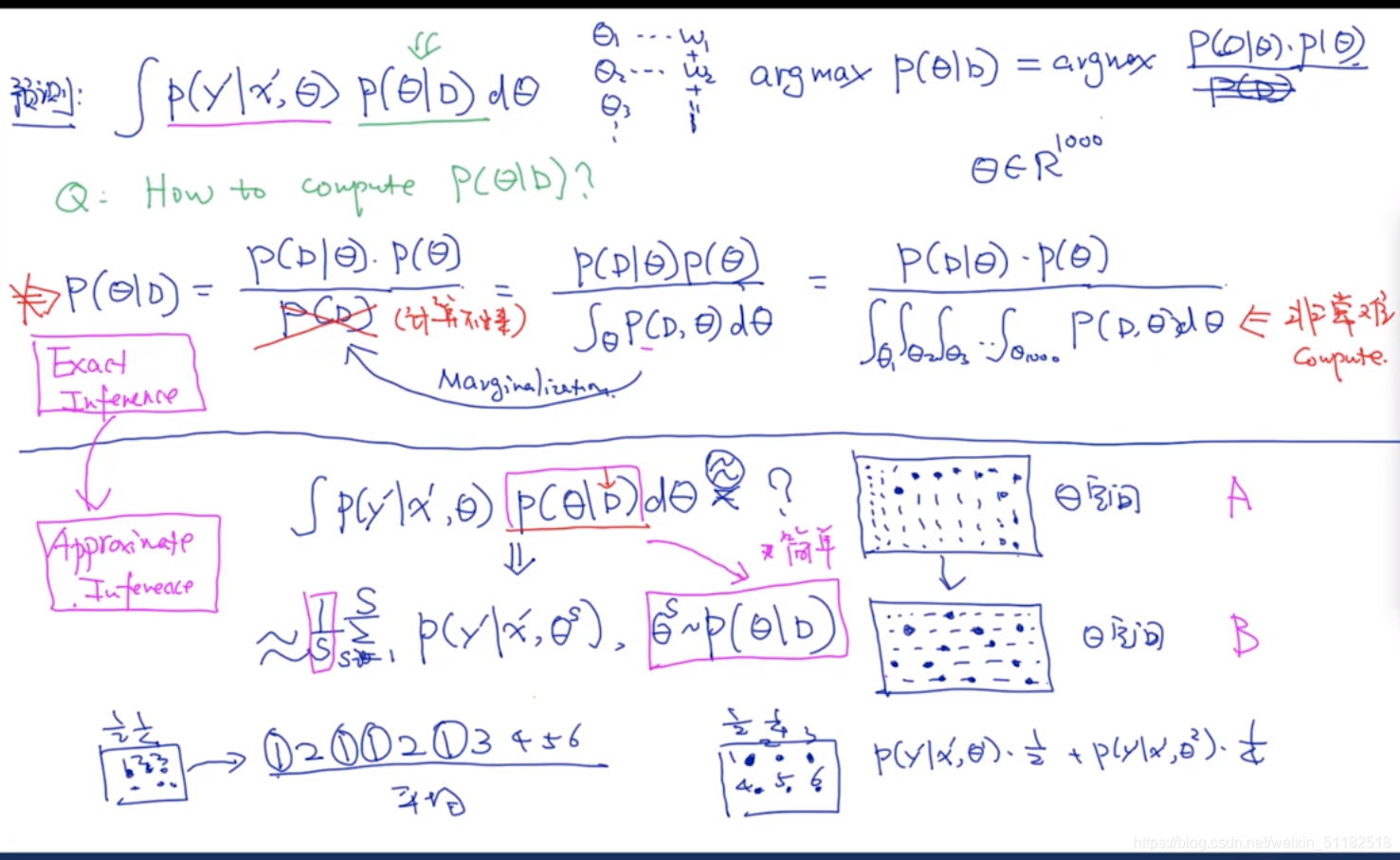
- 先采样
- 再把采样的结果放到预测的里面
4、Monte Carlo Sample
Markov chain Monte Cartlo(增加依赖关系)

5、如何使用LDA
5.1 LDA 的使用
- 加载数据集
- 文本处理(count-based)
- 使用LDA API(n_topics的设定需要调参把)
- 还需要定义 α , β \alpha,\beta α,β
- 画图
5.2 生成文章的process
目标:生成document,写一个文档。
基于参数,会生成文档。
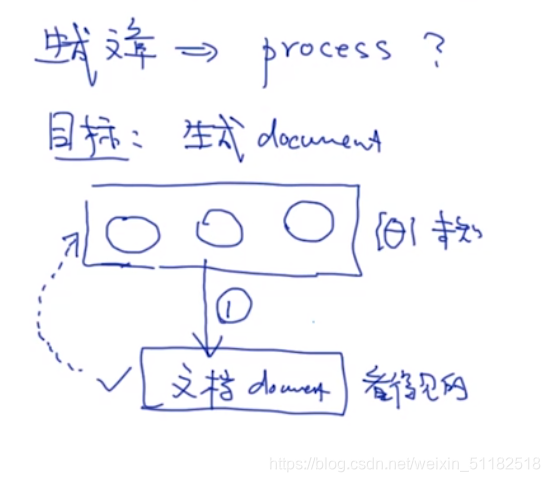
- 第一步:选择主题
case 1:只包含一个主题
case 2:包含多个主题

- 第二步:生成文章
生成list of words,lda不考虑单词的先后顺序
for j=1,2, …,99,100个单词
i)选择一个主题,选择一个合适的单词,比如科技
ii)在科技类别上选择合适的单词,对于科技类概率较大的词分布
针对每一个文档,先采样主题,在根据主体里的词分布,采样单词。
LDA 可以理解为是对文本的聚类,朴素贝叶斯是认定每个文本是属于一个主题,lda是考虑每个文本的主题是考虑了多种主题的概率分布,即每个文本都可能是任意一个主题,只不过成为任意一个主题的概率是不同的。
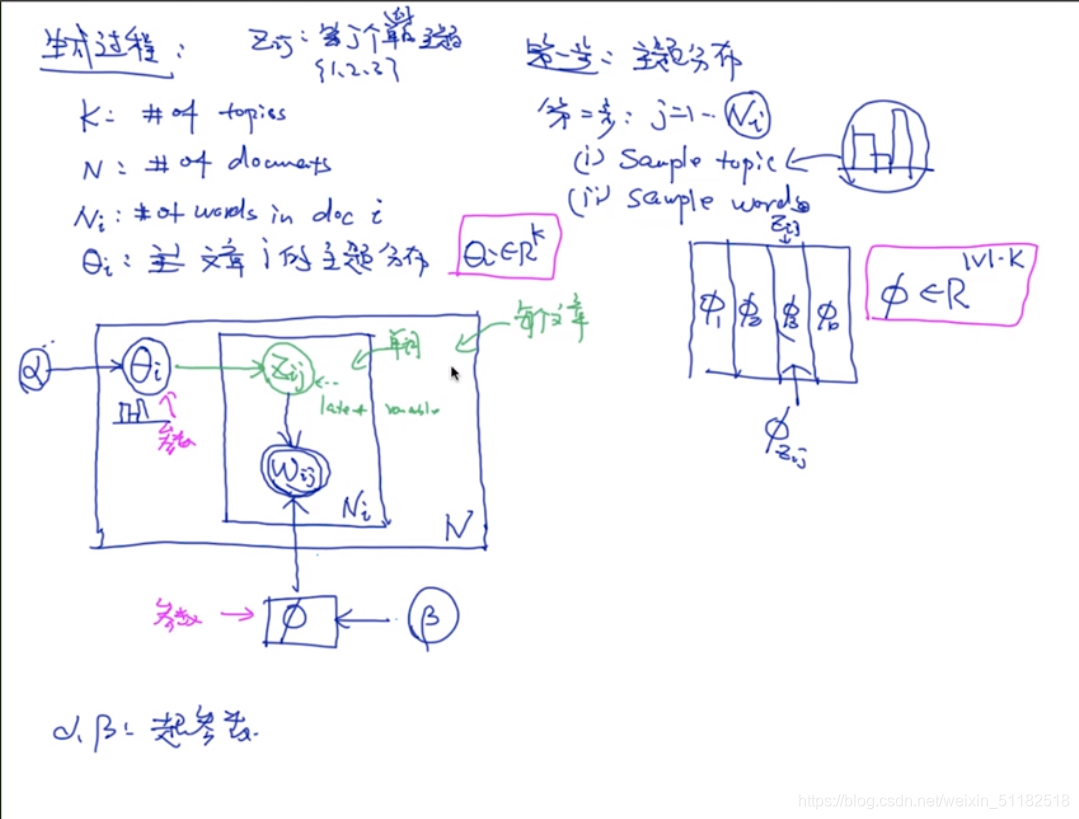
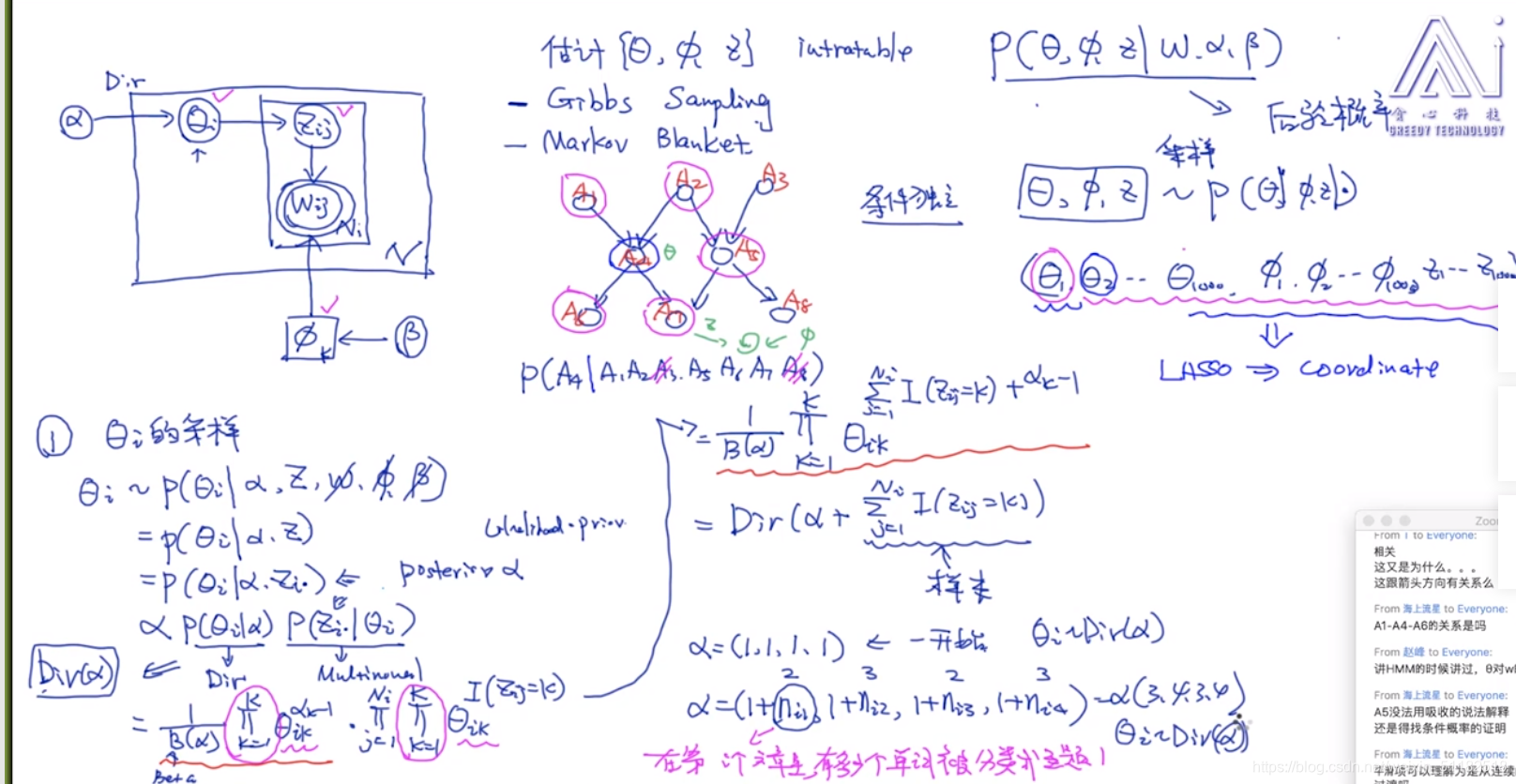
5.3 LDA的模型示意图
定义变量:
k:number of topic
N:number of document
N i N_i Ni: 第i个文章的长度:number of word
θ i \theta_i θi: 文章i的主题分布
生成的过程
1、主题分布
2、把 N i N_i Ni生成出来,先循环所有的文章,再循环一个文章中所有的单词
i)sample topic, z i j z_{ij} zij 代表第j个单词的主题,topic分布由 α \alpha α超参数得到。
ii) sample word,根据选择的主题,在词分布中采样
iii) 词分布由 β \beta β超参数得到
5.4 采样的过程
从 α 到 θ i \alpha到\theta_i α到θi的过程
dirichilet分布可以保证采样出来的样本点相加为1,符合概率分布的条件
β 到 ϕ \beta到\phi β到ϕ也是一样的。使用dirichlet分布
z i , j 和 w i , j z_{i,j}和w_{i,j} zi,j和wi,j的采样过程
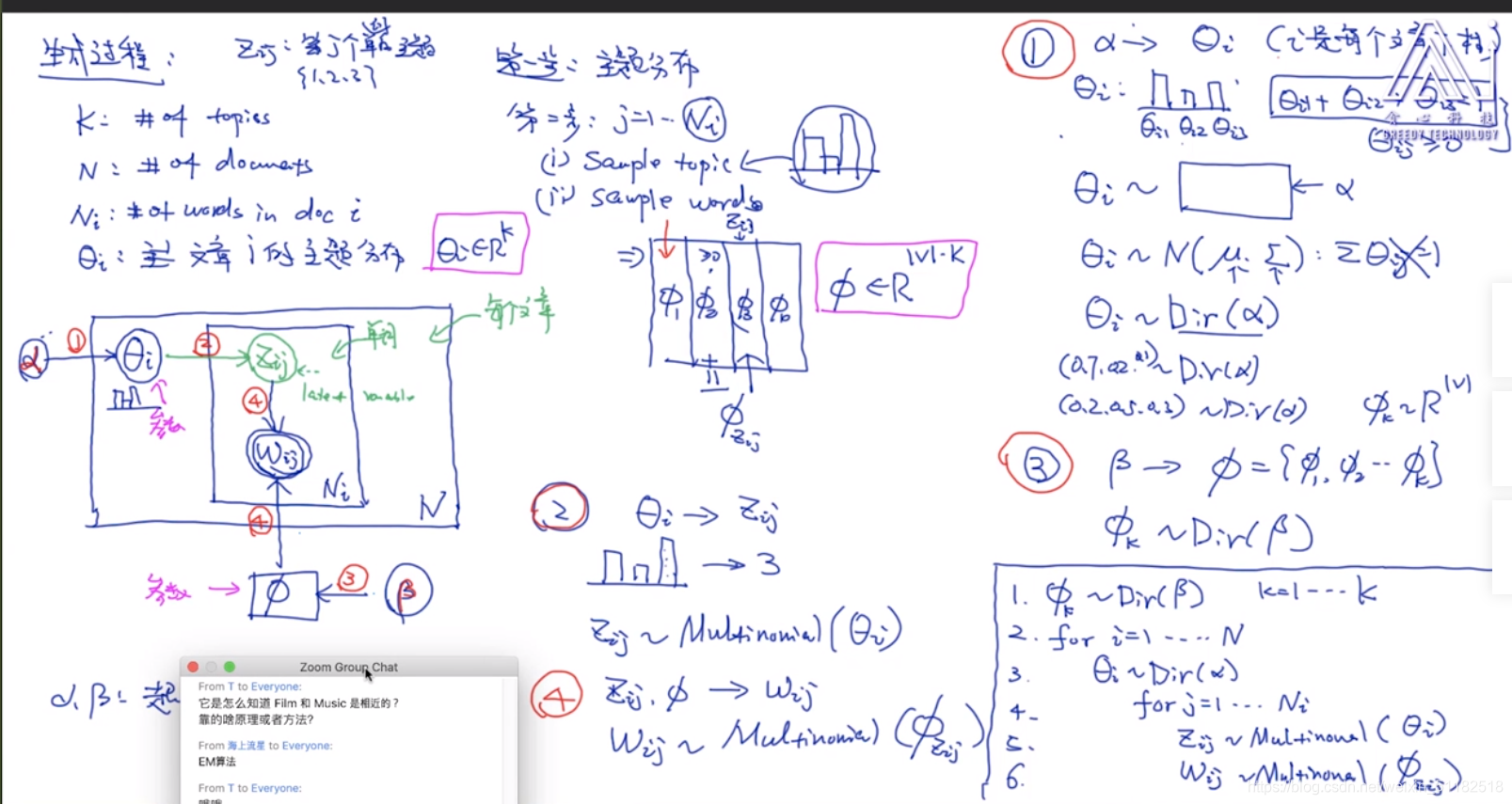
为什么选择dirchilet分布:
- 分布本身的优势,当 α 较 少 时 \alpha较少时 α较少时,会有sparsity,可能100个主题,只有两三个是概率很高的
- 计算的便利:conjugate prior (共轭先验)

Markov LDA
可以对于 z i , j z_{i,j} zi,j的选择也参考上一时刻生成出来的结果。
6、Gibbs sampling(Coordinate descent)
贝叶斯模型不预测参数,而是预测参数的概率分布
分别对每个隐变量/超参数进行采样
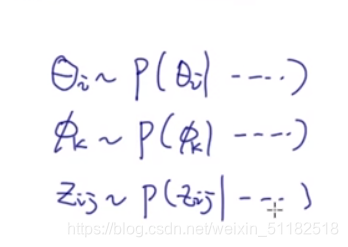
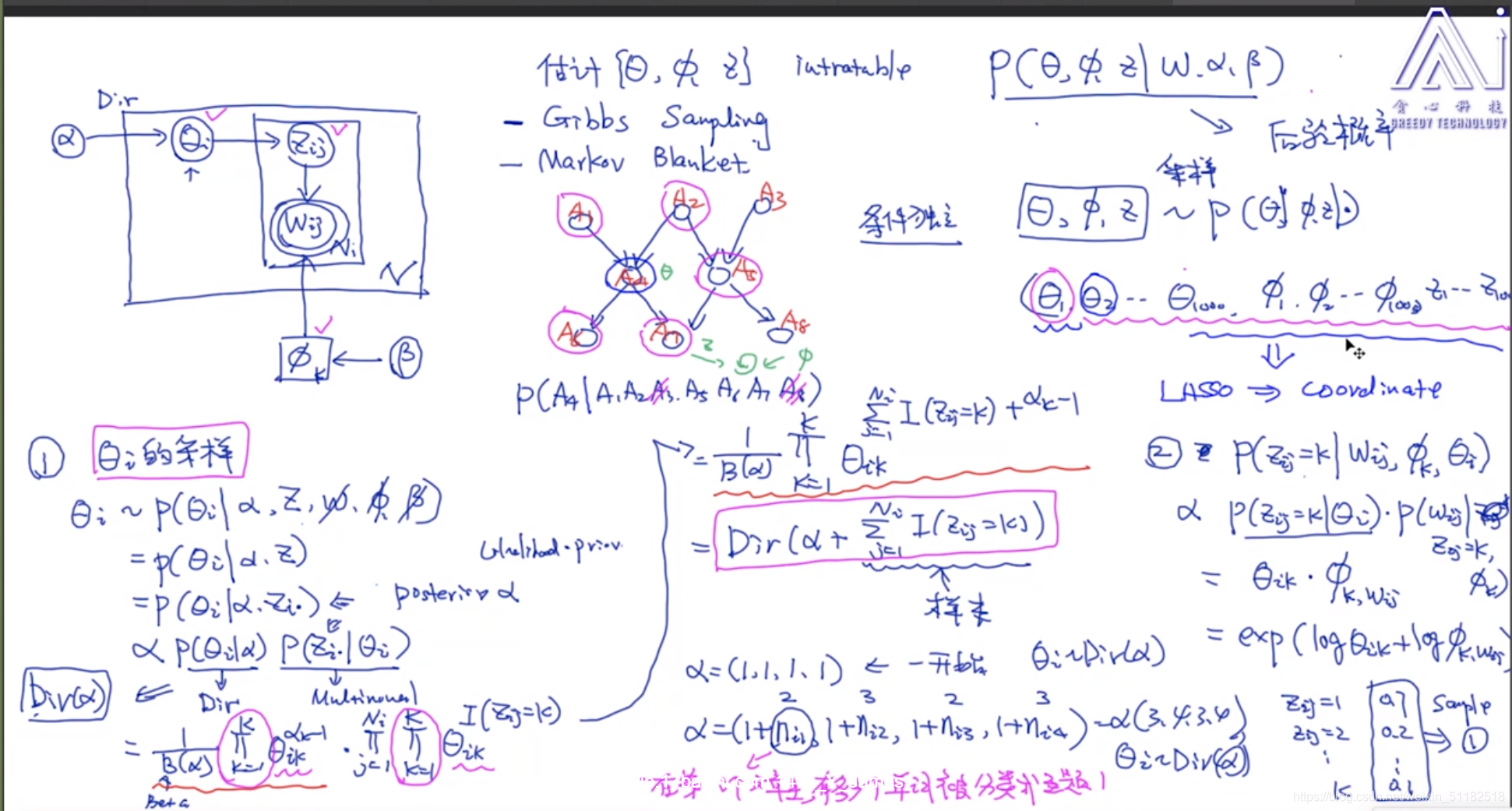
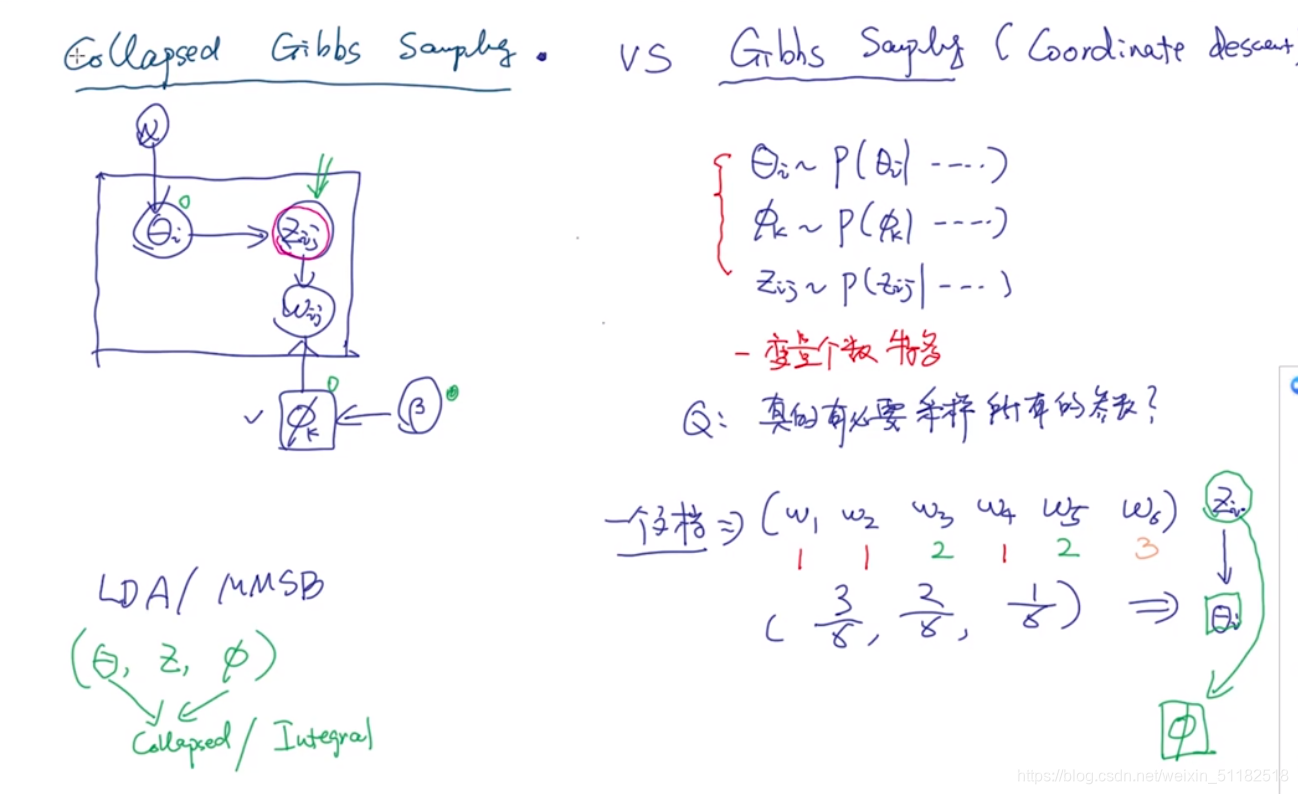
7、Collapsed Gibbs sampling
吉布斯采样的缺点:
- 变量个数多
变型:
只采样 z i , j z_{i,j} zi,j:第i个文档第j个单词对应的topic
根据这个变量去预测 θ 和 ϕ \theta和\phi θ和ϕ
7.1 Collapsed sampling 流程
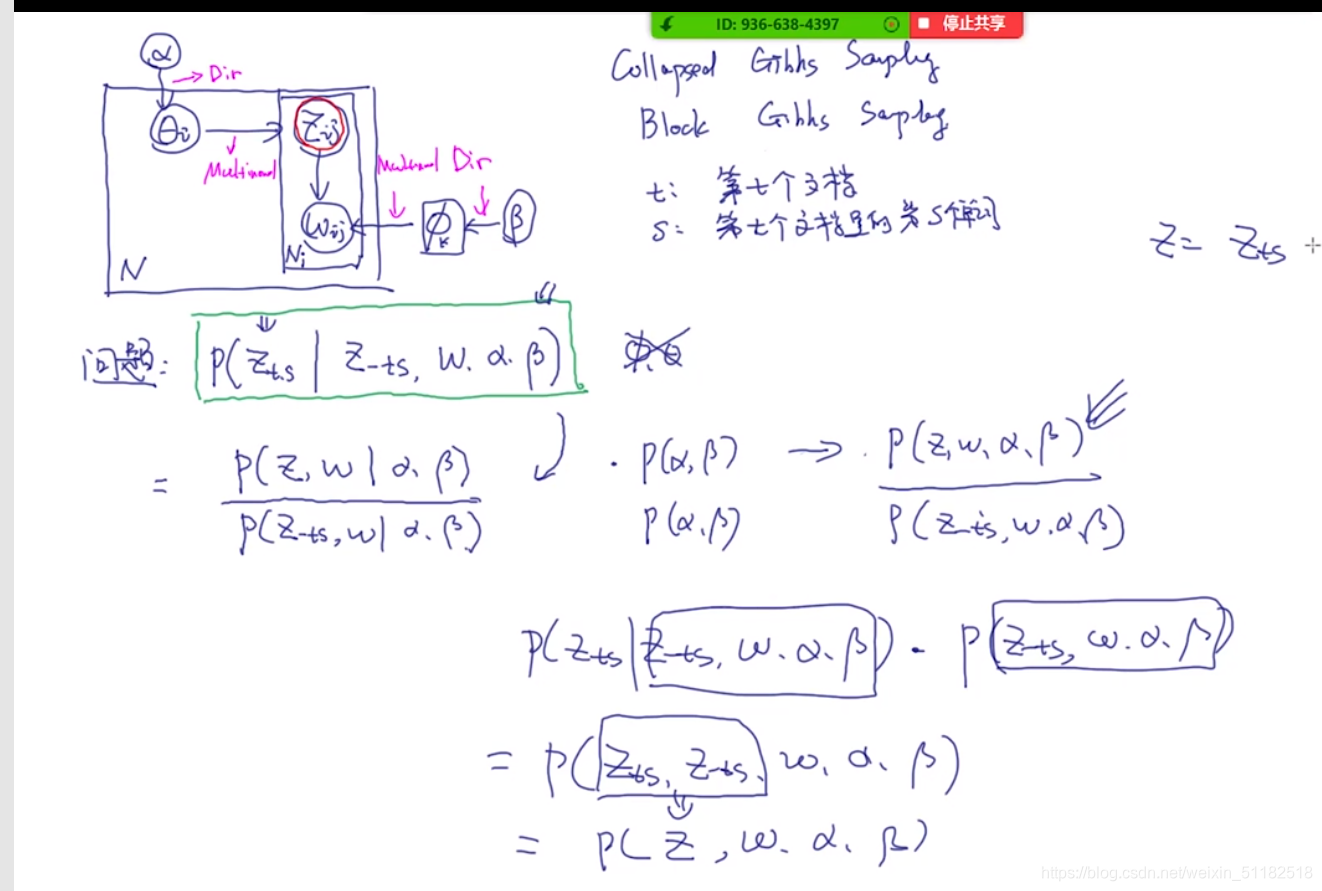
对于\theta和 ϕ \phi ϕ的边缘化操作:使用积分

对于 A: 主题性质:看主题和文档的关系
循环所有的文档,循环每个单词, z i , j z_{i,j} zi,j服从于多项式分布,循环每个主题,只计算 z i , j = k z_{i,j}=k zi,j=k的情况
循环所有的文档,每个文档服从dirichlet分布。
得到:一个新的dirichlet分布,且它的自变量等于alpha+多项式分布的概率值
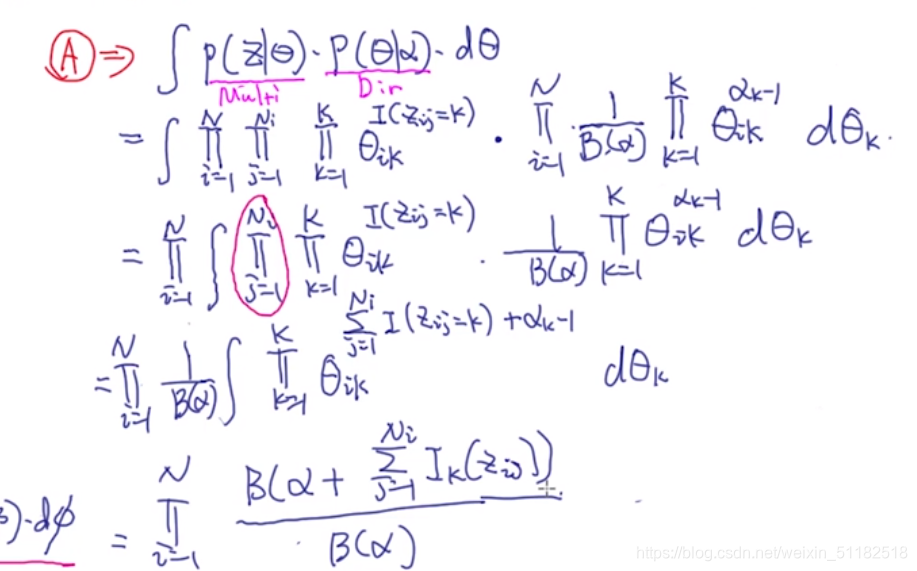

对于A部分的理解:先验分布为dirichlet分布,超参数为 α \alpha α,对每个文档的主题分布有个先验概率,然后通过多项式分布,统计每篇文档的属于第k个主题的词频,加入到dirichlet分布中。多项式分布的共轭先验分布是dirichilet分布。
对于B部分:词性质,看主题和词的关系
循环所有主题,循环每篇在z中选择了k主题的文档。
把所有属于k主题的文档拿出来只要这些文档中属于k主题的词
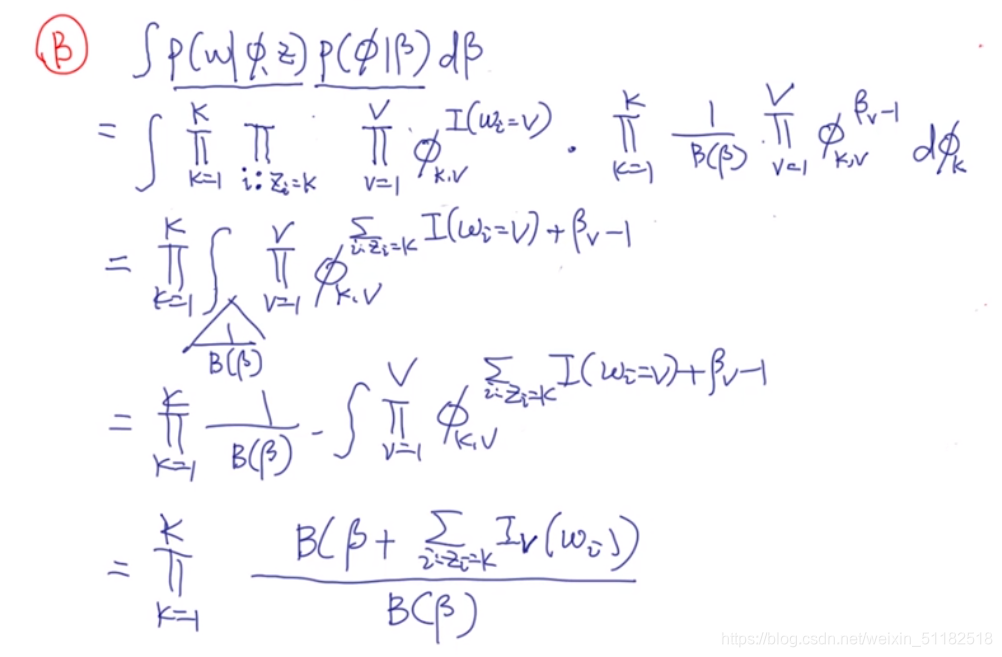
分子项:对A和B的拼接后的结果 p ( z , w ∣ α , β ) p(z,w|\alpha,\beta) p(z,w∣α,β)
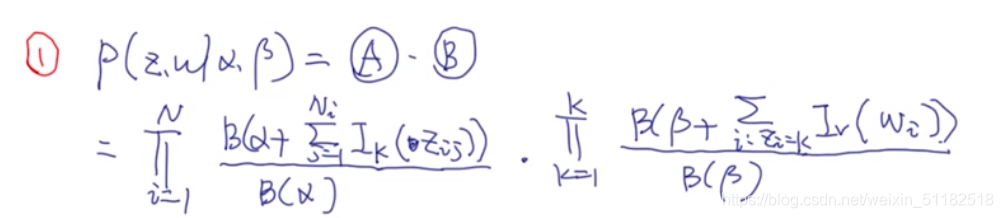
分母项,没有考虑第t个文档,第s个单词的情况

分子项/分母项
对于分子和分母项只有第t个文档是有不同的
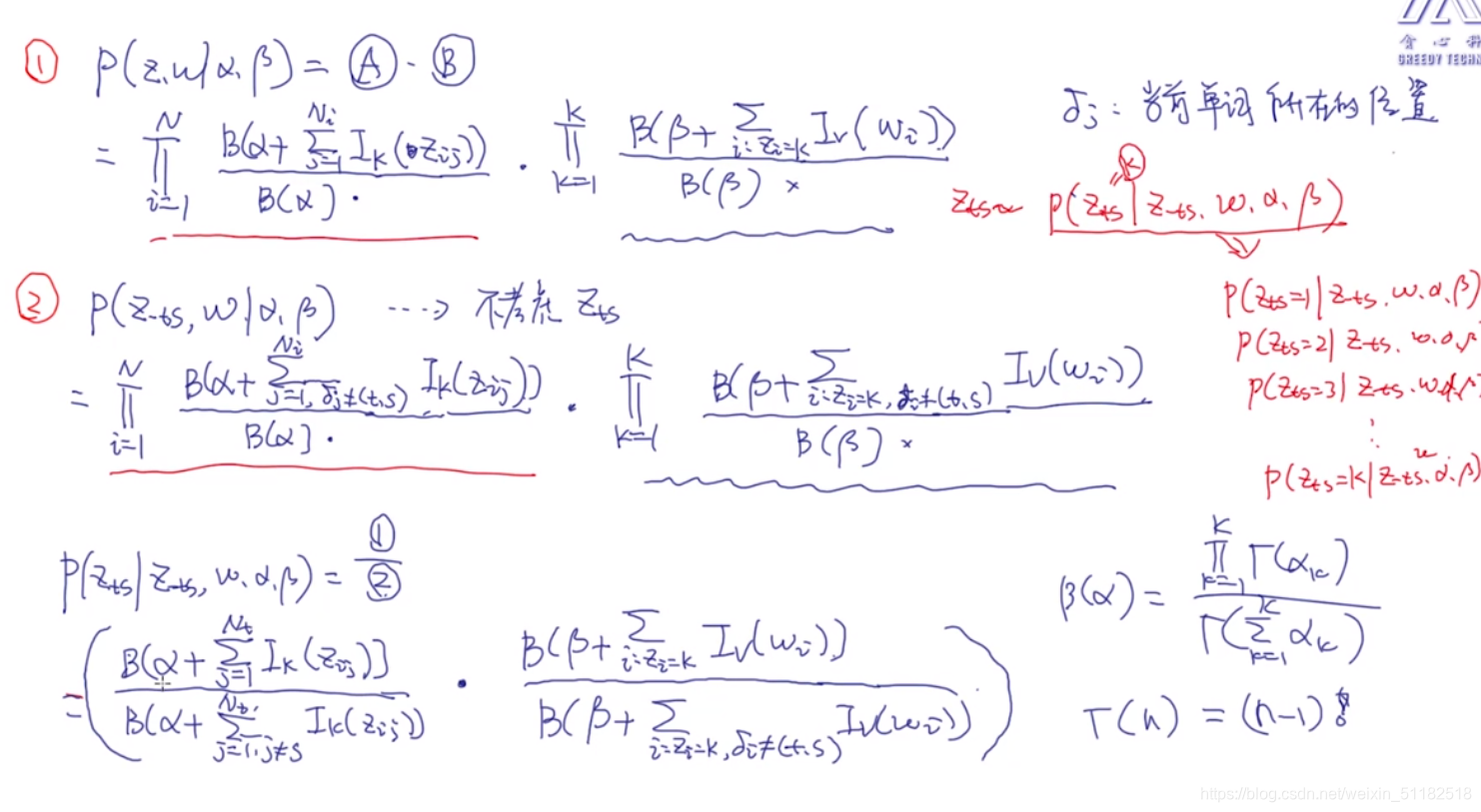
进一步的简化
对于主题性质:
- 分子部分:对于第t个文档,对于第k个主题,统计在该文档中属于第k个主题的所有词数
- 分母部分:对于第t个文档,对于第k个主题的第s个单词,统计除了第s个单词以外的属于第k个主题的词属。
对于词性质:
- 分子部分:对于第k个主题,统计所有文档为第k个主题的文档中:文档内词也为k主题的数量
- 分母部分,对于第k个主题,统计所有文档为第k个主题的文档中,除了第s个单词以外所有属于k主题的词数量。
对于主题性质
根据上面对于分子分母可以化简:
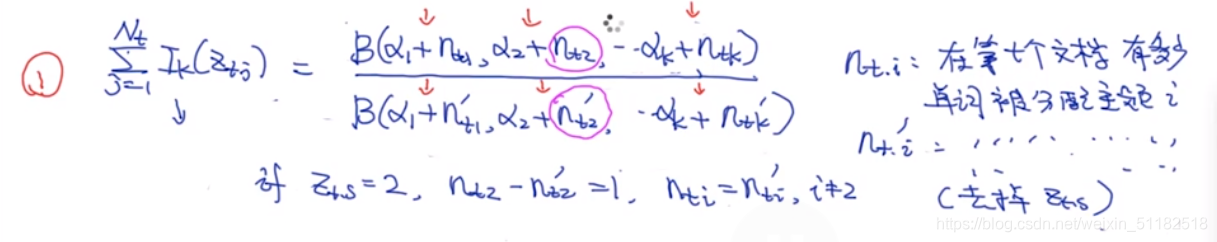
图中分子分母唯一不同的是,选定的第s个单词属于哪个主题,那么哪个主题在dirichlet中的那个维度的值就会-1
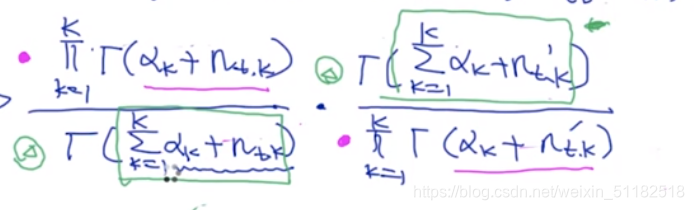
根据公式化简:
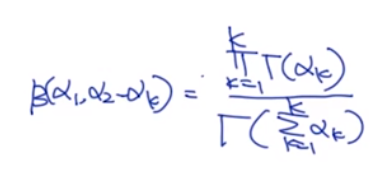
-
对于绿色的部分,它们之间的差值是1(减少了第s个单词在某一个k主题中的计算)
-
对于红色的部分,它们之间的商是保留有改变的那个主题的那个项
化简后:
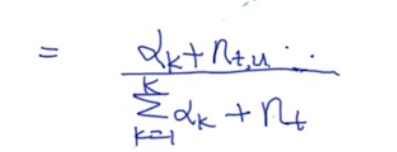


对于词性质:
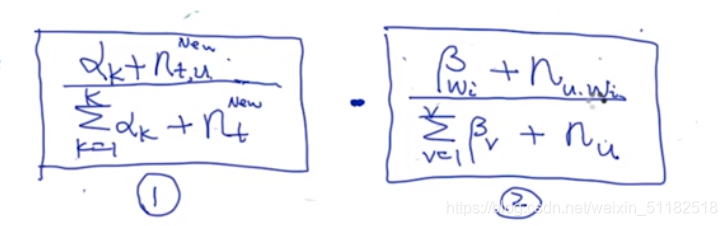
总体概括:
- n t , u n_{t,u} nt,u: 对于第t个文档,出去当前选定的词以为,所有属于u主题的词
- n t n_t nt:当前文档中除了选定词外,所有的词
- n u , w i n_{u,w_i} nu,wi:对于当前选定词,除去选定词以外,其他相同的词属于u主题的词。
- n u n_u nu:出去选定词外,所有文档中属于u主题的单词
对于某个单词的主题的定义,公式中所有项都没有考虑该单词。
举例说明
