上一次作业基本已经讲了构建一个多层神经网络的基本知识,包括其结构,公式推导,训练方法。这一次主要关注卷积神经网络(CNN, Convolution Neural Network),要先读完课程笔记 CS231n Convolutional Neural Networks for Visual Recognition,基本就懂了。特别是那个解释卷积的动态图,非常形象。
CNN 主要多了卷积层(convolution layer)和池化层(pooling layer)的操作,还有防止过拟合的 Batch Normalization 层和 Dropout 层。后面又介绍了很多这两年经典的 CNN 架构,如 LeNet, AlexNet, GoogLeNet, VGG 以及现在最好的 残差网络(residual network)等。
Fully-connected Neural Network
前面的作业已经实现了多层的神经网络,或者叫多层感知机,这里为了后面搭建 CNN 的方便性,又重新模块化实现了一遍。即把线性变化(Affine Layers),激活层(Activation Layers),loss 层都抽象出来,像箱子一样,可以把模块一个个堆积起来。每层都有 forward 和 backward 函数,负责前向传播和后向传播求导。
可以这样抽象出每层的原理就是链式求导法则,前面已经讲过了。每层只要关注 输出的梯度,就可以算出来 输入的梯度,这样一层层传递下去。很多现代的神经网络框架,如 tensorflow,pytorch 等都是这样子设计的,实际上这样节点的计算连接,最后组成了一个有向无环图,即计算图(Computation Graph)。在 TensorBoard 中还可以可视化这个计算图。
完成 FullyConnectedNets.ipynb 的要求,其中需要写完 cs231n/layers.py 中的 affine_forward, affine_backward, relu_forward, relu_backward 函数,最后几行的损失函数 svm_loss, softmax_loss 因为和之前的代码一样,所以已经帮我们实现好了。
完成 fc_net.py 中的 TwoLayerNet 类和 FullyConnectedNet 类,实现 optim.py 中的 sgd+momentum, rmsprop 和 adam,原理和公式可以参考 neural-networks-3,或者我前面的博客总结。
其实把每层都模块化以后,代码写起来还是很清晰的,麻烦点在于理清楚每层之间的关系,不过这些都是编程的逻辑和技巧,仔细一点就好了。
Batch Normalization
Batch Normalization 的出现真是逆天,加上一个简单的归一化操作(即减去均值,除以标准差),就能取得各种好的效果。具体来说,在卷积操作或者全连接层之后,但是在激活层之前加上 BN 层,会有下面的几个效果和好处,
- 减少坏初始化的影响
- 加快模型的收敛速度
- 可以用大些的学习率
- 能有效地防止过拟合
具体是怎么做的呢?是在一个 mini-batch 的数据中,算一个均值和标准差,然后做归一化,如下面公式所示,

里面的参数
反向传播时,也是按照链式法则求导即可,推导也很简单,见下图,
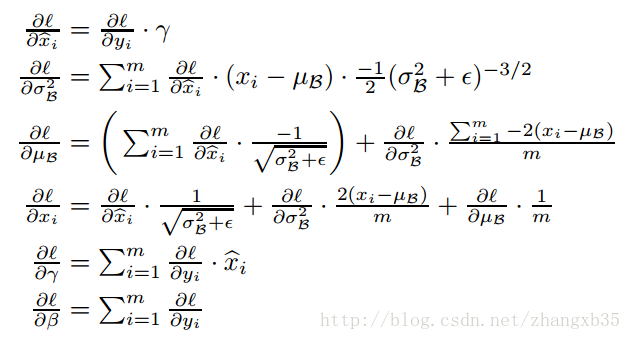
具体在作业里,按照 BatchNormalization.ipynb 的步骤,要实现 cs231n/layers.py 里的 batchnorm_forward,batchnorm_backward,和 batchnorm_backward_alt 三个函数。这里实现的是一维的 BatchNorm,后面可以发现,其实卷积上的 SpatialBatchNorm 也可以通过一维的接口实现。这里输入的数据
那么问题来了,为什么 BatchNorm 能够 work?背后的原理是什么呢?原论文里分析了很多,其中题目就提到可以减小了 internal covariance shift 的现象,而知乎上有人分析是减小了梯度消失(梯度弥散)问题。参考 知乎: 深度学习中 Batch Normalization为什么效果好? 和 Quora: Why does batch normalization help?
Dropout
Dropout 这种技术是 Hinton 老先生的那一派提出的黑魔法,一般会把这一层加在激活层之后。激活值会按照
在实现 Dropout 的时候,有一种技巧,如教程 neural-network-2 提到的,原始的实现方法,由于在训练时丢掉了部分的激活值,造成整体分布的期望值的下降,因此在预测时也要乘上一个概率
这部分作业比较简单,按照 Dropout.ipynb 的步骤实现 cs231n/layers.py 里的 dropout_forward, dropout_backward 函数,添加 dropout 层到分类器 fc_net.py 中。
ConvNet on CIFAR-10
卷积这部分是重点,主要需要实现 conv,max-pooling 和 spatial batch normalization,然而我 numpy 功力不够,经常需要参考大神的代码,有机会还要回来琢磨琢磨这些代码。按照 ConvolutionalNetworks.ipynb 的步骤,需要实现 cs231n/layers.py 里的 conv_forward_naive, conv_backward_naive, max_pool_forward_naive, max_pool_backward_naive, spatial_batchnorm_forward, spatial_batchnorm_backward 函数。
算卷积操作的前向传播时,基本思路是先沿着输入数据
for i in range(output_height):
for j in range(output_width):
x_padded_mask = x_padded[:, :, i*stride:i*stride+HH,j*stride:j*stride+WW]
for k in range(F):
out[:, k, i, j] = np.sum(x_padded_mask * w[k, :, :, :], axis=(1,2,3))out 是 feature map,第一个维度是 batch,第二个维度 k 是输出通道数,后两个维度 i,j 是 feature map 的高和宽。卷积核共 F 个,每个都是一个长方体,即输入的通道数 C * 卷积核的高 HH * 卷积核的宽 WW。
后面反向传播的逻辑和这里正好反过来了,见代码 L470-L474
for k in range(F): #compute dw
dw[k ,: ,: ,:] += np.sum(x_pad_masked * (dout[:, k, i, j])[:, None, None, None], axis=0)
for n in range(N): #compute dx_pad
dx_pad[n, :, i*stride:i*stride+HH, j*stride:j*stride+WW] += np.sum((w[:, :, :, :] * (dout[n, :, i, j])[:,None ,None, None]), axis=0)每个 feature map 的像素点都所有的卷积核和输入都有作用。对权重的梯度,要遍历所有通道数,在 batch 的维度上求和。对输入的梯度,要遍历所有的 batch,在通道数的维度上求和。
max-pooling 的代码就相对简单一点了,即在 pooling_mask 上取一个最大值,反向传播时,只是最大值的那个点有梯度回传回去。这里只是实现了最常见的 max-pooling,还有别的如 avg-pooling,stochastic pooling,还有 Kaiming He 大神的 Spatial Pyramid Pooling 。采用池化(pooling)的操作有很多的好处,
- 引入不变性(invariance)
- 包括 translation(平移),rotation(旋转),scale(尺度)
- 只要在 pooling window 里出现了激活,那么在哪里出现其实无所谓。对应原图片中,物体只要出现了,在图片的位置已经无所谓了。
- 当然,反过来说,pooling 之后也失去了局部的的位置信息。
- 减少了参数,防止过拟合,减少计算量
- 获得定长输出,两种方法
- 可以做 global pooling, 把 feature map 变成 (batch_size,channel,1,1) 的大小
- 利用 SPP,把输入划分成定量的格子后做 pooling,这个在 R-CNN 中也有应用
spatial_batchnorm 是在一维的 batch norm 的基础上实现的,代码也很少。不过代码却值得深究。具体的做法是,把每个 channel 当做是一个维度,在其他的三个维度上统计均值和方差。原话解释如下,
If the feature map was produced using convolutions, then we expect the statistics of each feature channel to be relatively consistent both between different imagesand different locations within the same image. Therefore spatial batch normalization computes a mean and variance for each of the C feature channels by computing statistics over both the minibatch dimension N and the spatial dimensions H and W.
最后要完成 ConvolutionalNetworks.ipynb 和 cnn.py 的代码。