作业总结
终于来到了最后一次作业,这次主要是讲 RNN 或 LSTM 这个时序模型,感觉如果公式已经熟悉了的话(没有的话多看几遍,也可以参考我上篇博文的公式总结,囧),作业应该比上次的简单。代码量也少一些。在写代码之前要下载一些必要的模型文件,数据集等,可能比上两次麻烦点,具体看 Assignment #3 的说明就好了。
我的作业代码见:cs231n/assignment3.
Image Caption
这次的作业内容是从 Image Caption 这个问题入手,即给定一张图片,生成对图片的文字描述。下图就是 Google NIC 模型的示意图,流程已经很清晰了。大概的做法是这样的,用一个预训练的 CNN 把图片提取特征,然后那这个特征初始化 RNN(LSTM) 的 hidden state,用 RNN(LSTM) 生成一句话。这里的 CNN 主要就是一个 encoder,负责把图片压缩成一个语义向量,而 RNN(LSTM) 则是一个 decoder,也是一个语言模型(language model),负责从这个语义向量解码出自然语言。
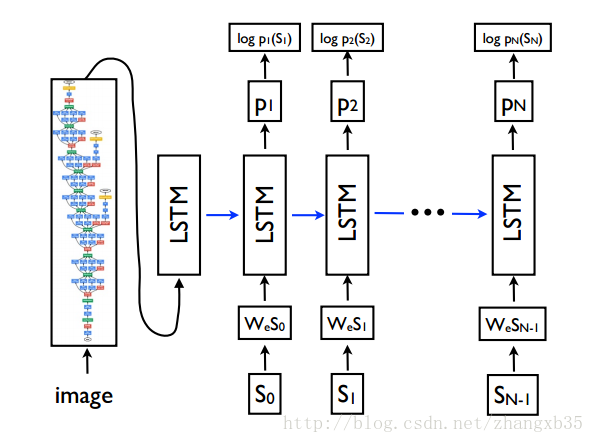
这门课的作者 Karpathy 在这个课题上曾做了很多工作,可以参考项目主页 Deep Visual-Semantic Alignments for Generating Image Descriptions
RNN
前面 RNN_Captioning.ipynb 主要是完成 RNN & LSTM 以及 word embedding 的 forward 和 backward 操作,见 cs231n/rnn_layers.py 文件。
这里再贴一下 RNN 的示意图:

RNN 的 step_forward 公式很简单,
RNN 的 forward 是要用 for 循环按照序列时序展开的,每个时刻 t 接收对应的输入
RNN 的 backward 就稍微麻烦一点,反向传播的方向要和上面的箭头全都反过来,即从最后一个时刻传回到
另外还要实现 word embedding 层,就是给定词表(词表大小为V)中的下标,映射到 D 维向量。词向量是 NLP 中比较基础的概念,可以参考【有谁可以解释下word embedding?】和【word2vec和word embedding有什么区别?】这两个知乎问答。除了 np.add.at 函数需要多了解一下,代码实现很简单。
接着要完成 classifiers/rnn.py 中的 loss 和 sample 函数,实现 Image Caption 的流程。注意 sample 是给定图片向量,自己生成一个对应的 caption,这个和 loss 中的 forward 过程不太一样。
下面多啰嗦几句,补充一下 RNN 是怎么生成一句话的。一般 RNN 的训练(train)和预测(Inference or test)是不一样的,因为训练时有 label,每时刻的输入都是 ground-truth 的单词;而预测只能把自己上时刻的输出(就是预测概率最大的那个单词)当做输入,顶多只是取前几个 sampling 一下。对比如下:
- Train
- 把 ground-truth word 当做 RNN 的输入,也有把这种做法叫做 teacher forcing 的
- 比较常见的做法
- Inference
- 把 RNN 上时刻的输出,当做下时刻的输入。
- 比如训练的时候也这样做,就会比较难训练
一种直觉(intuitive)的想法是,为什么不把两者结合起来呢?这种就是 Scheduled Sampling,见论文《Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks》。具体的做法是在刚开始训练时,模型用 ground-truth 来做输入,随着迭代次数增加,模型参数逐渐收敛,可以渐渐增加用 Inference 那样的做法,把上时刻的输出当做输入。具体用哪个是通过投硬币来决定的。而这个概率逐渐衰减的(论文里给了三种衰减的方法),即开始时偏向 teacher forcing的做法,后期逐渐偏向 inference 的做法。
还有一种用生成对抗网络(GAN)实现的 Professor Forcing,则是通过 GAN 的辅助,可以让 RNN 用 scheduled sampling 的方法生成的结果,尽量和 teacher focing 方法生成的结果靠拢。GAN 中有生成器(G)和判别器(D)两个网络,判别器要判别是用了哪一种方法生成结果,生成器尽量去愚弄判别器,两者在对抗的过程中同时提升性能。
LSTM
这里用的 LSTM 公式可以描述如下:
反向传播的时候,我开始时想推导公式,发现太麻烦,还是通过链式法则,一个变量一个变量后推回去,这样比较清晰。见 lstm_step_backward 的实现。LSTM 的作业和 RNN 差不多,在上面添砖铺瓦而已,具体参考 LSTM_Captioning.ipynb。
Image Gradient & Image Generation
这部分想探究一下 CNN 内部的原理,参考论文 Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps.
一般我们反向传播 CNN 的时候,是可以得到图片的梯度(Image
Gradient)的,但是因为网络要学习的参数是权重 W,因此都不会用到这个梯度。这篇论文可视化了一下图片的梯度,称作是 saliency map,发现其实是网络对不同处像素值关注的权重。得到的结果甚至可以辅助做 segmentation 问题。
下面考虑 Image Generation,给定一个类别标签,CNN 希望对应能输入什么样的图片呢?可以考虑把图片当做变量,固定模型中的权重,来优化下面的目标函数,
参考 ImageGradients.ipynb 和 ImageGeneration.ipynb 的实现。
貌似今年的课程又开始更新了,还加了无监督学习,强化学习的东东,不过作业三还没有出完,我有空再来更新吧~