终于来到了卷积网络
首先完成最基本的前向传播:
def conv_forward_naive(x, w, b, conv_param):
"""
A naive implementation of the forward pass for a convolutional layer.
The input consists of N data points, each with C channels, height H and
width W. We convolve each input with F different filters, where each filter
spans all C channels and has height HH and width WW.
Input:
- x: Input data of shape (N, C, H, W)
- w: Filter weights of shape (F, C, HH, WW)
- b: Biases, of shape (F,)
- conv_param: A dictionary with the following keys:
- 'stride': The number of pixels between adjacent receptive fields in the
horizontal and vertical directions.
- 'pad': The number of pixels that will be used to zero-pad the input.
During padding, 'pad' zeros should be placed symmetrically (i.e equally on both sides)
along the height and width axes of the input. Be careful not to modfiy the original
input x directly.
Returns a tuple of:
- out: Output data, of shape (N, F, H', W') where H' and W' are given by
H' = 1 + (H + 2 * pad - HH) / stride
W' = 1 + (W + 2 * pad - WW) / stride
- cache: (x, w, b, conv_param)
"""
out = None
###########################################################################
# TODO: Implement the convolutional forward pass. #
# Hint: you can use the function np.pad for padding. #
###########################################################################
N,C,H,W = x.shape #N个样本,C个通道,H的高度,W的宽度
F,C,HH,WW = w.shape #F个filter,C个通道,HH的filter高度,WW的filter宽度
stride = conv_param['stride']
pad = conv_param['pad']
#计算卷积结果矩阵的大小并分配全零值占位
new_H = 1 + int((H + 2 * pad - HH) / stride)
new_W= 1 + int((W + 2 * pad - WW) / stride)
out = np.zeros([N,F,new_H,new_W])
#卷积开始
for n in range(N):
for f in range(F):
#临时分配(new_H, new_W)大小的全偏移项卷积矩阵,(即提前加上偏移项b[f])
conv_newH_newW = np.ones([new_H,new_W]) * b[f]
for c in range(C):
#填充原始矩阵,填充大小为pad,填充值为0
padded_x = np.lib.pad(x[n,c],pad_width = pad,mode = 'constant',constant_values = 0)
for i in range(new_H):
for j in range(new_W):
conv_newH_newW[i,j] += np.sum(padded_x[i*stride:i*stride+HH,j*stride:j*stride+WW] * w[f,c,:,:])
out[n,f] = conv_newH_newW
###########################################################################
# END OF YOUR CODE #
###########################################################################
cache = (x, w, b, conv_param)
return out, cacheTesting conv_forward_naive
difference: 2.2121476417505994e-08
一个有趣的测试,通过我们实现的卷积层处理图片,得到其边缘信息。

完成基本的后向传播:
def conv_backward_naive(dout, cache):
"""
A naive implementation of the backward pass for a convolutional layer.
Inputs:
- dout: Upstream derivatives.
- cache: A tuple of (x, w, b, conv_param) as in conv_forward_naive
Returns a tuple of:
- dx: Gradient with respect to x
- dw: Gradient with respect to w
- db: Gradient with respect to b
"""
dx, dw, db = None, None, None
###########################################################################
# TODO: Implement the convolutional backward pass. #
###########################################################################
#数据准备
x,w,b,conv_param = cache
pad = conv_param['pad']
stride = conv_param['stride']
F,C,HH,WW = w.shape
N,C,H,W = x.shape
N,F,new_H,new_W = dout.shape
# 下面,我们模拟卷积,首先填充x。
padded_x = np.lib.pad(x,((0,0),(0,0),(pad,pad),(pad,pad)),mode = 'constant',constant_values = 0)
padded_dx = np.zeros_like(padded_x)# 填充了的dx,后面去填充即可得到dx
dw = np.zeros_like(w)
db = np.zeros_like(b)
for n in range(N): #第n个图像
for f in range(F): #第f个filter
for j in range(new_W):
for i in range(new_H):
db[f] += dout[n,f,i,j] #dg对db求导为1*dout
dw[f] += padded_x[n,:,i*stride:HH+i*stride,j*stride:WW+j*stride] * dout[n,f,i,j]
padded_dx[n,:,i*stride:i*stride+HH,j*stride:j*stride+WW] += w[f] * dout[n,f,i,j]
#去掉填充部分
dx = padded_dx[:,:,pad:pad+H,pad:pad+W]
###########################################################################
# END OF YOUR CODE #
###########################################################################
return dx, dw, dbTesting conv_backward_naive function
dx error: 4.697936086933718e-09
dw error: 6.468236300100291e-10
db error: 2.122692916910524e-10
完成基本的max_pooling前向传播:
Quiz time:
Q:在max_pooling层的filter中有多少参数?
A:0
def max_pool_forward_naive(x, pool_param):
"""
A naive implementation of the forward pass for a max-pooling layer.
Inputs:
- x: Input data, of shape (N, C, H, W)
- pool_param: dictionary with the following keys:
- 'pool_height': The height of each pooling region
- 'pool_width': The width of each pooling region
- 'stride': The distance between adjacent pooling regions
No padding is necessary here. Output size is given by
Returns a tuple of:
- out: Output data, of shape (N, C, H', W') where H' and W' are given by
H' = 1 + (H - pool_height) / stride
W' = 1 + (W - pool_width) / stride
- cache: (x, pool_param)
"""
out = None
###########################################################################
# TODO: Implement the max-pooling forward pass #
###########################################################################
N,C,H,W = x.shape
pool_height = pool_param['pool_height'] #filter的高度、宽度、步长
pool_width = pool_param['pool_width']
pool_stride = pool_param['stride']
new_H = 1 + int((H - pool_height) / pool_stride) #池化结果矩阵高度和宽度
new_W = 1 + int((W - pool_width) / pool_stride)
out = np.zeros([N,C,new_H,new_W])
for n in range(N):
for c in range(C):
for i in range(new_H):
for j in range(new_W):
out[n,c,i,j] = np.max(x[n,c,i*pool_stride:i*pool_stride + pool_height,j*pool_stride : j*pool_stride + pool_width])
###########################################################################
# END OF YOUR CODE #
###########################################################################
cache = (x, pool_param)
return out, cacheTesting max_pool_forward_naive function:
difference: 4.1666665157267834e-08
完成基本的后向传播:
def max_pool_backward_naive(dout, cache):
"""
A naive implementation of the backward pass for a max-pooling layer.
Inputs:
- dout: Upstream derivatives
- cache: A tuple of (x, pool_param) as in the forward pass.
Returns:
- dx: Gradient with respect to x
"""
dx = None
###########################################################################
# TODO: Implement the max-pooling backward pass #
###########################################################################
x,pool_param = cache
N,C,H,W = x.shape
pool_height = pool_param['pool_height'] #filter的高度、宽度、步长
pool_width = pool_param['pool_width']
pool_stride = pool_param['stride']
new_H = 1 + int((H - pool_height) / pool_stride) #池化结果矩阵高度和宽度
new_W = 1 + int((W- pool_width) / pool_stride)
dx = np.zeros_like(x)
for n in range(N):
for c in range(C):
for i in range(new_H):
for j in range(new_W):
window = x[n,c,i*pool_stride:i*pool_stride + pool_height,j*pool_stride:j*pool_stride + pool_width]
dx[n,c,i*pool_stride:i*pool_stride + pool_height,j*pool_stride:j*pool_stride + pool_width] = (window == np.max(window)) * dout[n,c,i,j]
###########################################################################
# END OF YOUR CODE #
###########################################################################
return dxTesting max_pool_backward_naive function:
dx error: 3.27562514223145e-12
Fast layers:
深渊巨坑!!!
搞了一天才搞定这个fast layer,不过网上很多人也遇到过这个问题。
之前在服务器上(ubuntu 16.04)上测试失败,在python setup.py build_ext --inplace这步有问题,没能解决,猜想是python版本的问题?
最终在本地(windows10 + anaconda + python3.7 + vs2017 + jupyter)解决。
def conv_forward_strides(x, w, b, conv_param):
N, C, H, W = x.shape
F, _, HH, WW = w.shape
stride, pad = conv_param['stride'], conv_param['pad']
# Check dimensions
#assert (W + 2 * pad - WW) % stride == 0, 'width does not work'
#assert (H + 2 * pad - HH) % stride == 0, 'height does not work'
# Pad the input
p = pad
x_padded = np.pad(x, ((0, 0), (0, 0), (p, p), (p, p)), mode='constant')
# Figure out output dimensions
H += 2 * pad
W += 2 * pad
out_h = (H - HH) // stride + 1
out_w = (W - WW) // stride + 1
# Perform an im2col operation by picking clever strides
shape = (C, HH, WW, N, out_h, out_w)
strides = (H * W, W, 1, C * H * W, stride * W, stride)
strides = x.itemsize * np.array(strides)
x_stride = np.lib.stride_tricks.as_strided(x_padded,
shape=shape, strides=strides)
x_cols = np.ascontiguousarray(x_stride)
x_cols.shape = (C * HH * WW, N * out_h * out_w)
# Now all our convolutions are a big matrix multiply
res = w.reshape(F, -1).dot(x_cols) + b.reshape(-1, 1)
# Reshape the output
res.shape = (F, N, out_h, out_w)
out = res.transpose(1, 0, 2, 3)
# Be nice and return a contiguous array
# The old version of conv_forward_fast doesn't do this, so for a fair
# comparison we won't either
out = np.ascontiguousarray(out)
cache = (x, w, b, conv_param, x_cols)
return out, cache
def conv_backward_strides(dout, cache):
x, w, b, conv_param, x_cols = cache
stride, pad = conv_param['stride'], conv_param['pad']
N, C, H, W = x.shape
F, _, HH, WW = w.shape
_, _, out_h, out_w = dout.shape
db = np.sum(dout, axis=(0, 2, 3))
dout_reshaped = dout.transpose(1, 0, 2, 3).reshape(F, -1)
dw = dout_reshaped.dot(x_cols.T).reshape(w.shape)
dx_cols = w.reshape(F, -1).T.dot(dout_reshaped)
dx_cols.shape = (C, HH, WW, N, out_h, out_w)
dx = col2im_6d_cython(dx_cols, N, C, H, W, HH, WW, pad, stride)
return dx, dw, db
conv_forward_fast = conv_forward_strides
conv_backward_fast = conv_backward_strides测试结果:
Testing conv_forward_fast:
Naive: 11.416385s
Fast: 0.019946s
Speedup: 572.375517x
Difference: 2.7285883131760887e-11
Testing conv_backward_fast:
Naive: 7.826572s
Fast: 0.010972s
Speedup: 713.351754x
dx difference: 1.949764775345631e-11
dw difference: 7.783102001148809e-13
不得不说确实快了很多。
测试有池化层的快慢的对比:
def max_pool_forward_fast(x, pool_param):
"""
A fast implementation of the forward pass for a max pooling layer.
This chooses between the reshape method and the im2col method. If the pooling
regions are square and tile the input image, then we can use the reshape
method which is very fast. Otherwise we fall back on the im2col method, which
is not much faster than the naive method.
"""
N, C, H, W = x.shape
pool_height, pool_width = pool_param['pool_height'], pool_param['pool_width']
stride = pool_param['stride']
same_size = pool_height == pool_width == stride
tiles = H % pool_height == 0 and W % pool_width == 0
if same_size and tiles:
out, reshape_cache = max_pool_forward_reshape(x, pool_param)
cache = ('reshape', reshape_cache)
else:
out, im2col_cache = max_pool_forward_im2col(x, pool_param)
cache = ('im2col', im2col_cache)
return out, cache
def max_pool_backward_fast(dout, cache):
"""
A fast implementation of the backward pass for a max pooling layer.
This switches between the reshape method an the im2col method depending on
which method was used to generate the cache.
"""
method, real_cache = cache
if method == 'reshape':
return max_pool_backward_reshape(dout, real_cache)
elif method == 'im2col':
return max_pool_backward_im2col(dout, real_cache)
else:
raise ValueError('Unrecognized method "%s"' % method)
def max_pool_forward_reshape(x, pool_param):
"""
A fast implementation of the forward pass for the max pooling layer that uses
some clever reshaping.
This can only be used for square pooling regions that tile the input.
"""
N, C, H, W = x.shape
pool_height, pool_width = pool_param['pool_height'], pool_param['pool_width']
stride = pool_param['stride']
assert pool_height == pool_width == stride, 'Invalid pool params'
assert H % pool_height == 0
assert W % pool_height == 0
x_reshaped = x.reshape(N, C, H // pool_height, pool_height,
W // pool_width, pool_width)
out = x_reshaped.max(axis=3).max(axis=4)
cache = (x, x_reshaped, out)
return out, cache
def max_pool_backward_reshape(dout, cache):
"""
A fast implementation of the backward pass for the max pooling layer that
uses some clever broadcasting and reshaping.
This can only be used if the forward pass was computed using
max_pool_forward_reshape.
NOTE: If there are multiple argmaxes, this method will assign gradient to
ALL argmax elements of the input rather than picking one. In this case the
gradient will actually be incorrect. However this is unlikely to occur in
practice, so it shouldn't matter much. One possible solution is to split the
upstream gradient equally among all argmax elements; this should result in a
valid subgradient. You can make this happen by uncommenting the line below;
however this results in a significant performance penalty (about 40% slower)
and is unlikely to matter in practice so we don't do it.
"""
x, x_reshaped, out = cache
dx_reshaped = np.zeros_like(x_reshaped)
out_newaxis = out[:, :, :, np.newaxis, :, np.newaxis]
mask = (x_reshaped == out_newaxis)
dout_newaxis = dout[:, :, :, np.newaxis, :, np.newaxis]
dout_broadcast, _ = np.broadcast_arrays(dout_newaxis, dx_reshaped)
dx_reshaped[mask] = dout_broadcast[mask]
dx_reshaped /= np.sum(mask, axis=(3, 5), keepdims=True)
dx = dx_reshaped.reshape(x.shape)
return dx
def max_pool_forward_im2col(x, pool_param):
"""
An implementation of the forward pass for max pooling based on im2col.
This isn't much faster than the naive version, so it should be avoided if
possible.
"""
N, C, H, W = x.shape
pool_height, pool_width = pool_param['pool_height'], pool_param['pool_width']
stride = pool_param['stride']
assert (H - pool_height) % stride == 0, 'Invalid height'
assert (W - pool_width) % stride == 0, 'Invalid width'
out_height = (H - pool_height) // stride + 1
out_width = (W - pool_width) // stride + 1
x_split = x.reshape(N * C, 1, H, W)
x_cols = im2col(x_split, pool_height, pool_width, padding=0, stride=stride)
x_cols_argmax = np.argmax(x_cols, axis=0)
x_cols_max = x_cols[x_cols_argmax, np.arange(x_cols.shape[1])]
out = x_cols_max.reshape(out_height, out_width, N, C).transpose(2, 3, 0, 1)
cache = (x, x_cols, x_cols_argmax, pool_param)
return out, cache
def max_pool_backward_im2col(dout, cache):
"""
An implementation of the backward pass for max pooling based on im2col.
This isn't much faster than the naive version, so it should be avoided if
possible.
"""
x, x_cols, x_cols_argmax, pool_param = cache
N, C, H, W = x.shape
pool_height, pool_width = pool_param['pool_height'], pool_param['pool_width']
stride = pool_param['stride']
dout_reshaped = dout.transpose(2, 3, 0, 1).flatten()
dx_cols = np.zeros_like(x_cols)
dx_cols[x_cols_argmax, np.arange(dx_cols.shape[1])] = dout_reshaped
dx = col2im_indices(dx_cols, (N * C, 1, H, W), pool_height, pool_width,
padding=0, stride=stride)
dx = dx.reshape(x.shape)
return dxTesting pool_forward_fast:
Naive: 0.296182s
fast: 0.004988s
speedup: 59.382266x
difference: 0.0
Testing pool_backward_fast:
Naive: 0.813053s
fast: 0.010970s
speedup: 74.115296x
dx difference: 0.0
也是快了很多
卷积层的“三明治”
def conv_relu_pool_forward(x, w, b, conv_param, pool_param):
"""
Convenience layer that performs a convolution, a ReLU, and a pool.
Inputs:
- x: Input to the convolutional layer
- w, b, conv_param: Weights and parameters for the convolutional layer
- pool_param: Parameters for the pooling layer
Returns a tuple of:
- out: Output from the pooling layer
- cache: Object to give to the backward pass
"""
a, conv_cache = conv_forward_fast(x, w, b, conv_param) # 卷积层
s, relu_cache = relu_forward(a) # 激活函数
out, pool_cache = max_pool_forward_fast(s, pool_param) # 池化层
cache = (conv_cache, relu_cache, pool_cache)
return out, cache
def conv_relu_pool_backward(dout, cache):
"""
Backward pass for the conv-relu-pool convenience layer
"""
conv_cache, relu_cache, pool_cache = cache
ds = max_pool_backward_fast(dout, pool_cache) # 池化层
da = relu_backward(ds, relu_cache) # 激活函数
dx, dw, db = conv_backward_fast(da, conv_cache) # 卷积层
return dx, dw, dbTesting conv_relu_pool
dx error: 6.514336569263308e-09
dw error: 1.490843753539445e-08
db error: 2.037390356217257e-09
def conv_relu_forward(x, w, b, conv_param):
"""
A convenience layer that performs a convolution followed by a ReLU.
Inputs:
- x: Input to the convolutional layer
- w, b, conv_param: Weights and parameters for the convolutional layer
Returns a tuple of:
- out: Output from the ReLU
- cache: Object to give to the backward pass
"""
a, conv_cache = conv_forward_fast(x, w, b, conv_param) #卷积层
out, relu_cache = relu_forward(a) #激活函数
cache = (conv_cache, relu_cache) #保存结果给后向传播
return out, cache
def conv_relu_backward(dout, cache):
"""
Backward pass for the conv-relu convenience layer.
"""
conv_cache, relu_cache = cache
da = relu_backward(dout, relu_cache)
dx, dw, db = conv_backward_fast(da, conv_cache)
return dx, dw, dbTesting conv_relu:
dx error: 3.5600610115232832e-09
dw error: 2.2497700915729298e-10
db error: 1.3087619975802167e-10
完成一个3层的卷积网络,结果为:conv - relu - 2x2 max pool - affine - relu - affine - softmax
class ThreeLayerConvNet(object):
"""
A three-layer convolutional network with the following architecture:
conv - relu - 2x2 max pool - affine - relu - affine - softmax
The network operates on minibatches of data that have shape (N, C, H, W)
consisting of N images, each with height H and width W and with C input
channels.
"""
def __init__(self, input_dim=(3, 32, 32), num_filters=32, filter_size=7,
hidden_dim=100, num_classes=10, weight_scale=1e-3, reg=0.0,
dtype=np.float32):
"""
Initialize a new network.
Inputs:
- input_dim: Tuple (C, H, W) giving size of input data
- num_filters: Number of filters to use in the convolutional layer
- filter_size: Width/height of filters to use in the convolutional layer
- hidden_dim: Number of units to use in the fully-connected hidden layer
- num_classes: Number of scores to produce from the final affine layer.
- weight_scale: Scalar giving standard deviation for random initialization
of weights.
- reg: Scalar giving L2 regularization strength
- dtype: numpy datatype to use for computation.
"""
self.params = {}
self.reg = reg
self.dtype = dtype
############################################################################
# TODO: Initialize weights and biases for the three-layer convolutional #
# network. Weights should be initialized from a Gaussian centered at 0.0 #
# with standard deviation equal to weight_scale; biases should be #
# initialized to zero. All weights and biases should be stored in the #
# dictionary self.params. Store weights and biases for the convolutional #
# layer using the keys 'W1' and 'b1'; use keys 'W2' and 'b2' for the #
# weights and biases of the hidden affine layer, and keys 'W3' and 'b3' #
# for the weights and biases of the output affine layer. #
# #
# IMPORTANT: For this assignment, you can assume that the padding #
# and stride of the first convolutional layer are chosen so that #
# **the width and height of the input are preserved**. Take a look at #
# the start of the loss() function to see how that happens. #
############################################################################
C,H,W = input_dim #输入数据的size C-channels,H-height,W-width
self.params['W1'] = np.random.randn(num_filters,C,filter_size,filter_size) * weight_scale
#高斯分布(N,C,L,L) N个filter,每个filter都是L*L,C个channel
self.params['b1'] = np.zeros(num_filters,) #(32,1)
self.params['W2'] = np.random.randn(num_filters * H * W // 4,hidden_dim) * weight_scale
#高斯分布 这一层是全连接层,输入的维数是N*H*W/4,除以4是因为通过了max_pooling层,因为通过padding保留了原来大小,输出是hidden_dim的维数
self.params['b2'] = np.zeros(hidden_dim,) #(100,1)
self.params['W3'] = np.random.randn(hidden_dim,num_classes) * weight_scale
#高斯分布(100,10) 全连接层,输入维数hidden_dim,输出是num_classes
self.params['b3'] = np.zeros(num_classes,) #(10,1)
############################################################################
# END OF YOUR CODE #
############################################################################
for k, v in self.params.items():
self.params[k] = v.astype(dtype)
def loss(self, X, y=None):
"""
Evaluate loss and gradient for the three-layer convolutional network.
Input / output: Same API as TwoLayerNet in fc_net.py.
"""
W1, b1 = self.params['W1'], self.params['b1']
W2, b2 = self.params['W2'], self.params['b2']
W3, b3 = self.params['W3'], self.params['b3']
# pass conv_param to the forward pass for the convolutional layer
# Padding and stride chosen to preserve the input spatial size
filter_size = W1.shape[2]
conv_param = {'stride': 1, 'pad': (filter_size - 1) // 2}
# pass pool_param to the forward pass for the max-pooling layer
pool_param = {'pool_height': 2, 'pool_width': 2, 'stride': 2}
scores = None
############################################################################
# TODO: Implement the forward pass for the three-layer convolutional net, #
# computing the class scores for X and storing them in the scores #
# variable. #
# #
# Remember you can use the functions defined in cs231n/fast_layers.py and #
# cs231n/layer_utils.py in your implementation (already imported). #
############################################################################
out1,cache1 = conv_relu_pool_forward(X,W1,b1,conv_param,pool_param) #first layer
# cache1 = (conv_cache, relu_cache, pool_cache)
out = out1.reshape(out1.shape[0],-1) #拉成一个长向量
out,cache2 = affine_relu_forward(out,W2,b2) #second layer
#cache2 = (fc_cache, relu_cache)
scores,cache3 = affine_forward(out,W3,b3) # third layer
# cache = (x, w, b)
############################################################################
# END OF YOUR CODE #
############################################################################
if y is None:
return scores
loss, grads = 0, {}
############################################################################
# TODO: Implement the backward pass for the three-layer convolutional net, #
# storing the loss and gradients in the loss and grads variables. Compute #
# data loss using softmax, and make sure that grads[k] holds the gradients #
# for self.params[k]. Don't forget to add L2 regularization! #
# #
# NOTE: To ensure that your implementation matches ours and you pass the #
# automated tests, make sure that your L2 regularization includes a factor #
# of 0.5 to simplify the expression for the gradient. #
############################################################################
loss,dout = softmax_loss(scores,y)
loss += self.reg * 0.5 * (np.sum(W3 ** 2) + np.sum(W2 ** 2) + np.sum(W1 ** 2))
dout,grads['W3'],grads['b3'] = affine_backward(dout,cache3)
grads['W3'] += W3 * self.reg
dout,grads['W2'],grads['b2'] = affine_relu_backward(dout,cache2)
grads['W2'] += W2 * self.reg
dout = dout.reshape(*out1.shape)
dout,grads['W1'],grads['b1'] = conv_relu_pool_backward(dout,cache1)
grads['W1'] += W1 * self.reg
############################################################################
# END OF YOUR CODE #
############################################################################
return loss, grads
初始的loss检查:
Initial loss (no regularization): 2.3025839797804086
Initial loss (with regularization): 2.5084965847084253
有正则项的loss要大一点点
梯度检查:
W1 max relative error: 1.380104e-04
W2 max relative error: 1.822723e-02
W3 max relative error: 3.064049e-04
b1 max relative error: 3.477652e-05
b2 max relative error: 2.516375e-03
b3 max relative error: 7.945660e-10
看看这个网络能否在一个小数据集上过拟合
(Iteration 1 / 30) loss: 2.414060
(Epoch 0 / 15) train acc: 0.200000; val_acc: 0.137000
(Iteration 2 / 30) loss: 3.102925
(Epoch 1 / 15) train acc: 0.140000; val_acc: 0.081000
(Iteration 3 / 30) loss: 2.673266
(Iteration 4 / 30) loss: 2.257389
(Epoch 2 / 15) train acc: 0.140000; val_acc: 0.095000
(Iteration 5 / 30) loss: 1.967534
(Iteration 6 / 30) loss: 1.914532
(Epoch 3 / 15) train acc: 0.400000; val_acc: 0.163000
(Iteration 7 / 30) loss: 1.903067
(Iteration 8 / 30) loss: 2.085949
(Epoch 4 / 15) train acc: 0.420000; val_acc: 0.197000
(Iteration 9 / 30) loss: 1.566363
(Iteration 10 / 30) loss: 1.634450
(Epoch 5 / 15) train acc: 0.530000; val_acc: 0.184000
(Iteration 11 / 30) loss: 1.140067
(Iteration 12 / 30) loss: 1.146590
(Epoch 6 / 15) train acc: 0.630000; val_acc: 0.205000
(Iteration 13 / 30) loss: 1.205710
(Iteration 14 / 30) loss: 1.097082
(Epoch 7 / 15) train acc: 0.660000; val_acc: 0.204000
(Iteration 15 / 30) loss: 0.676990
(Iteration 16 / 30) loss: 0.854177
(Epoch 8 / 15) train acc: 0.760000; val_acc: 0.194000
(Iteration 17 / 30) loss: 0.965628
(Iteration 18 / 30) loss: 0.449211
(Epoch 9 / 15) train acc: 0.820000; val_acc: 0.167000
(Iteration 19 / 30) loss: 0.475107
(Iteration 20 / 30) loss: 0.495566
(Epoch 10 / 15) train acc: 0.860000; val_acc: 0.197000
(Iteration 21 / 30) loss: 0.440097
(Iteration 22 / 30) loss: 0.180259
(Epoch 11 / 15) train acc: 0.910000; val_acc: 0.228000
(Iteration 23 / 30) loss: 0.253805
(Iteration 24 / 30) loss: 0.546616
(Epoch 12 / 15) train acc: 0.950000; val_acc: 0.231000
(Iteration 25 / 30) loss: 0.182069
(Iteration 26 / 30) loss: 0.162158
(Epoch 13 / 15) train acc: 0.970000; val_acc: 0.231000
(Iteration 27 / 30) loss: 0.075110
(Iteration 28 / 30) loss: 0.076801
(Epoch 14 / 15) train acc: 0.950000; val_acc: 0.194000
(Iteration 29 / 30) loss: 0.094693
(Iteration 30 / 30) loss: 0.226416
(Epoch 15 / 15) train acc: 0.990000; val_acc: 0.208000
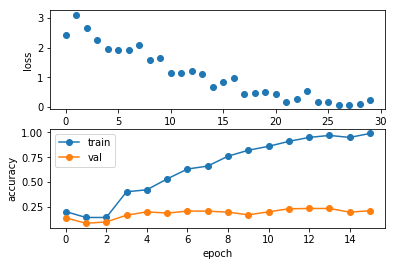
明显已经过拟合了,说明我们的网络还阔以。
在整个数据集上训练一个epoch,发现瞬间吃了11G的内存,cpu吃到40%。
训练的结果,花了16分钟多。
(Iteration 1 / 980) loss: 2.304670
(Epoch 0 / 1) train acc: 0.110000; val_acc: 0.098000
(Iteration 21 / 980) loss: 2.732537
(Iteration 41 / 980) loss: 2.170465
(Iteration 61 / 980) loss: 2.208721
(Iteration 81 / 980) loss: 2.096256
(Iteration 101 / 980) loss: 1.843767
(Iteration 121 / 980) loss: 2.083252
(Iteration 141 / 980) loss: 1.888873
(Iteration 161 / 980) loss: 2.252999
(Iteration 181 / 980) loss: 1.694516
(Iteration 201 / 980) loss: 1.927185
(Iteration 221 / 980) loss: 1.802649
(Iteration 241 / 980) loss: 1.532741
(Iteration 261 / 980) loss: 1.842087
(Iteration 281 / 980) loss: 1.737544
(Iteration 301 / 980) loss: 1.741998
(Iteration 321 / 980) loss: 1.873080
(Iteration 341 / 980) loss: 1.931449
(Iteration 361 / 980) loss: 1.737292
(Iteration 381 / 980) loss: 1.541905
(Iteration 401 / 980) loss: 1.747270
(Iteration 421 / 980) loss: 1.874305
(Iteration 441 / 980) loss: 1.747306
(Iteration 461 / 980) loss: 1.893086
(Iteration 481 / 980) loss: 1.424662
(Iteration 501 / 980) loss: 1.502941
(Iteration 521 / 980) loss: 1.721210
(Iteration 541 / 980) loss: 1.363159
(Iteration 561 / 980) loss: 1.451044
(Iteration 581 / 980) loss: 1.642617
(Iteration 601 / 980) loss: 1.459946
(Iteration 621 / 980) loss: 1.592594
(Iteration 641 / 980) loss: 1.456973
(Iteration 661 / 980) loss: 1.495759
(Iteration 681 / 980) loss: 1.226670
(Iteration 701 / 980) loss: 1.835095
(Iteration 721 / 980) loss: 1.597228
(Iteration 741 / 980) loss: 1.680976
(Iteration 761 / 980) loss: 1.274999
(Iteration 781 / 980) loss: 1.531974
(Iteration 801 / 980) loss: 1.644552
(Iteration 821 / 980) loss: 1.473959
(Iteration 841 / 980) loss: 1.472652
(Iteration 861 / 980) loss: 1.542808
(Iteration 881 / 980) loss: 1.449692
(Iteration 901 / 980) loss: 1.322417
(Iteration 921 / 980) loss: 1.486854
(Iteration 941 / 980) loss: 1.457475
(Iteration 961 / 980) loss: 1.137655
(Epoch 1 / 1) train acc: 0.499000; val_acc: 0.513000
it cost 16.0 minutes and 52.751606464385986 seconds
准确率还是可以的。
偷窥一下卷积核在干什么。

空间的batchnorm:
对于深度网络的训练是一个复杂的过程,只要网络的前面几层发生微小的改变,那么后面几层就会被累积放大下去。一旦网络某一层的输入数据的分布发生改变,那么这一层网络就需要去适应学习这个新的数据分布。所以,在训练过程中,如果训练数据的分布一直发生变化,那么网络的训练速度将会受到影响。基于“批量正则化(BN)层”的理念,我们引入了“空间批量正则化SBN层”。
BN(Batch Normalization,批量正则化)的提出说到底还是为了防止训练过程中的“梯度弥散”。在BN中,通过将activation规范为均值和方差一致的手段使得原本会减小的activation变大,避免趋近于0的数的出现。但是CNN的BN层有些不同,我们需要稍加改动,变成更适合训练的“SBN”。
def spatial_batchnorm_forward(x, gamma, beta, bn_param):
"""
Computes the forward pass for spatial batch normalization.
Inputs:
- x: Input data of shape (N, C, H, W)
- gamma: Scale parameter, of shape (C,)
- beta: Shift parameter, of shape (C,)
- bn_param: Dictionary with the following keys:
- mode: 'train' or 'test'; required
- eps: Constant for numeric stability
- momentum: Constant for running mean / variance. momentum=0 means that
old information is discarded completely at every time step, while
momentum=1 means that new information is never incorporated. The
default of momentum=0.9 should work well in most situations.
- running_mean: Array of shape (D,) giving running mean of features
- running_var Array of shape (D,) giving running variance of features
Returns a tuple of:
- out: Output data, of shape (N, C, H, W)
- cache: Values needed for the backward pass
"""
out, cache = None, None
###########################################################################
# TODO: Implement the forward pass for spatial batch normalization. #
# #
# HINT: You can implement spatial batch normalization by calling the #
# vanilla version of batch normalization you implemented above. #
# Your implementation should be very short; ours is less than five lines. #
###########################################################################
N,C,H,W = x.shape
x_new = x.transpose(0,2,3,1).reshape(N*H*W,C)
out,cache = batchnorm_forward(x_new,gamma,beta,bn_param)
out = out.reshape(N,H,W,C).transpose(0,3,1,2)
###########################################################################
# END OF YOUR CODE #
###########################################################################
return out, cache在训练阶段检查:
Before spatial batch normalization:
Shape: (2, 3, 4, 5)
Means: [9.33463814 8.90909116 9.11056338]
Stds: [3.61447857 3.19347686 3.5168142 ]
After spatial batch normalization:
Shape: (2, 3, 4, 5)
Means: [ 6.18949336e-16 5.99520433e-16 -1.22124533e-16]
Stds: [0.99999962 0.99999951 0.9999996 ]
After spatial batch normalization (nontrivial gamma, beta):
Shape: (2, 3, 4, 5)
Means: [6. 7. 8.]
Stds: [2.99999885 3.99999804 4.99999798]
在测试阶段检查:
After spatial batch normalization (test-time):
means: [-0.08034406 0.07562881 0.05716371 0.04378383]
stds: [0.96718744 1.0299714 1.02887624 1.00585577]
结果具有类似于batchnorm的特点
后向传播
def spatial_batchnorm_backward(dout, cache):
"""
Computes the backward pass for spatial batch normalization.
Inputs:
- dout: Upstream derivatives, of shape (N, C, H, W)
- cache: Values from the forward pass
Returns a tuple of:
- dx: Gradient with respect to inputs, of shape (N, C, H, W)
- dgamma: Gradient with respect to scale parameter, of shape (C,)
- dbeta: Gradient with respect to shift parameter, of shape (C,)
"""
dx, dgamma, dbeta = None, None, None
###########################################################################
# TODO: Implement the backward pass for spatial batch normalization. #
# #
# HINT: You can implement spatial batch normalization by calling the #
# vanilla version of batch normalization you implemented above. #
# Your implementation should be very short; ours is less than five lines. #
###########################################################################
N,C,H,W = dout.shape
dout_new = dout.transpose(0,2,3,1).reshape(N*H*W,C)
dx,dgamma,dbeta = batchnorm_backward(dout_new,cache)
dx = dx.reshape(N,H,W,C).transpose(0,3,1,2)
###########################################################################
# END OF YOUR CODE #
###########################################################################
return dx, dgamma, dbetadx error: 2.786648197756335e-07
dgamma error: 7.0974817113608705e-12
dbeta error: 3.275608725278405e-12
组归一化:
see:
Ba, Jimmy Lei, Jamie Ryan Kiros, and Geoffrey E. Hinton. "Layer Normalization." stat 1050 (2016): 21.
Wu, Yuxin, and Kaiming He. "Group Normalization." arXiv preprint arXiv:1803.08494 (2018).
N. Dalal and B. Triggs. Histograms of oriented gradients for human detection. In Computer Vision and Pattern Recognition (CVPR), 2005.
首先是前向传播:
def spatial_groupnorm_forward(x, gamma, beta, G, gn_param):
"""
Computes the forward pass for spatial group normalization.
In contrast to layer normalization, group normalization splits each entry
in the data into G contiguous pieces, which it then normalizes independently.
Per feature shifting and scaling are then applied to the data, in a manner identical to that of batch normalization and layer normalization.
Inputs:
- x: Input data of shape (N, C, H, W)
- gamma: Scale parameter, of shape (C,)
- beta: Shift parameter, of shape (C,)
- G: Integer mumber of groups to split into, should be a divisor of C
- gn_param: Dictionary with the following keys:
- eps: Constant for numeric stability
Returns a tuple of:
- out: Output data, of shape (N, C, H, W)
- cache: Values needed for the backward pass
"""
out, cache = None, None
eps = gn_param.get('eps',1e-5)
###########################################################################
# TODO: Implement the forward pass for spatial group normalization. #
# This will be extremely similar to the layer norm implementation. #
# In particular, think about how you could transform the matrix so that #
# the bulk of the code is similar to both train-time batch normalization #
# and layer normalization! #
###########################################################################
N,C,H,W = x.shape
x_group = np.reshape(x,(N,G,C//G,H,W)) #分为C//G组
mean = np.mean(x_group,axis = (2,3,4),keepdims = True) #求均值
var = np.var(x_group,axis = (2,3,4),keepdims = True) #求方差
x_groupnorm = (x_group - mean) / np.sqrt(var + eps) #归一化
x_norm = np.reshape(x_groupnorm,(N,C,H,W)) #还原维度
out = x_norm * gamma + beta #还原C
cache = (G,x,x_norm,mean,var,beta,gamma,eps)
###########################################################################
# END OF YOUR CODE #
###########################################################################
return out, cachedx error: 2.786648197756335e-07
dgamma error: 7.0974817113608705e-12
dbeta error: 3.275608725278405e-12
后向传播部分:
def spatial_groupnorm_backward(dout, cache):
"""
Computes the backward pass for spatial group normalization.
Inputs:
- dout: Upstream derivatives, of shape (N, C, H, W)
- cache: Values from the forward pass
Returns a tuple of:
- dx: Gradient with respect to inputs, of shape (N, C, H, W)
- dgamma: Gradient with respect to scale parameter, of shape (C,)
- dbeta: Gradient with respect to shift parameter, of shape (C,)
"""
dx, dgamma, dbeta = None, None, None
###########################################################################
# TODO: Implement the backward pass for spatial group normalization. #
# This will be extremely similar to the layer norm implementation. #
###########################################################################
N,C,H,W = dout.shape
G,x,x_norm,mean,var,beta,gamma,eps = cache
dbeta = np.sum(dout,axis = (0,2,3),keepdims = True)
dgamma = np.sum(dout * x_norm,axis = (0,2,3),keepdims = True)
#计算dx_group
#dx_groupnorm
dx_norm = dout * gamma
dx_groupnorm = dx_norm.reshape((N,G,C//G,H,W))
#dvar
x_group = x.reshape((N,G,C//G,H,W))
dvar = np.sum(dx_groupnorm * -1.0 / 2 * (x_group - mean) / (var + eps) ** (3.0/2),axis = (2,3,4),keepdims = True)
#dmean
n_group = C // G * H * W
dmean1 = np.sum(dx_groupnorm * -1.0 / np.sqrt(var + eps),axis = (2,3,4),keepdims = True)
dmean2_var = dvar * -2.0 / n_group * np.sum(x_group - mean,axis = (2,3,4),keepdims = True)
dmean = dmean1 + dmean2_var
#dx_group
dx_group1 = dx_groupnorm * 1.0 / np.sqrt(var + eps)
dx_group2_mean = dmean * 1.0 / n_group
dx_group3_var = dvar * 2.0 / n_group * (x_group - mean)
dx_group = dx_group1 + dx_group2_mean + dx_group3_var
#还原dx
dx = dx_group.reshape(N,C,H,W)
###########################################################################
# END OF YOUR CODE #
###########################################################################
return dx, dgamma, dbetadx error: 7.413109622045623e-08
dgamma error: 9.468195772749234e-12
dbeta error: 3.354494437653335e-12