版权声明:本文为博主原创文章,转载时请著名出处:http://blog.csdn.net/dg_summer https://blog.csdn.net/DG_summer/article/details/72231993
python爬数据小试牛刀–beautifulSoup使用
1.环境配置
- 编译环境:python 2.7
- 编译器:pycharm
- HTML或XML提取工具:beautifulSoup(安装自行百度)
2.网站分析
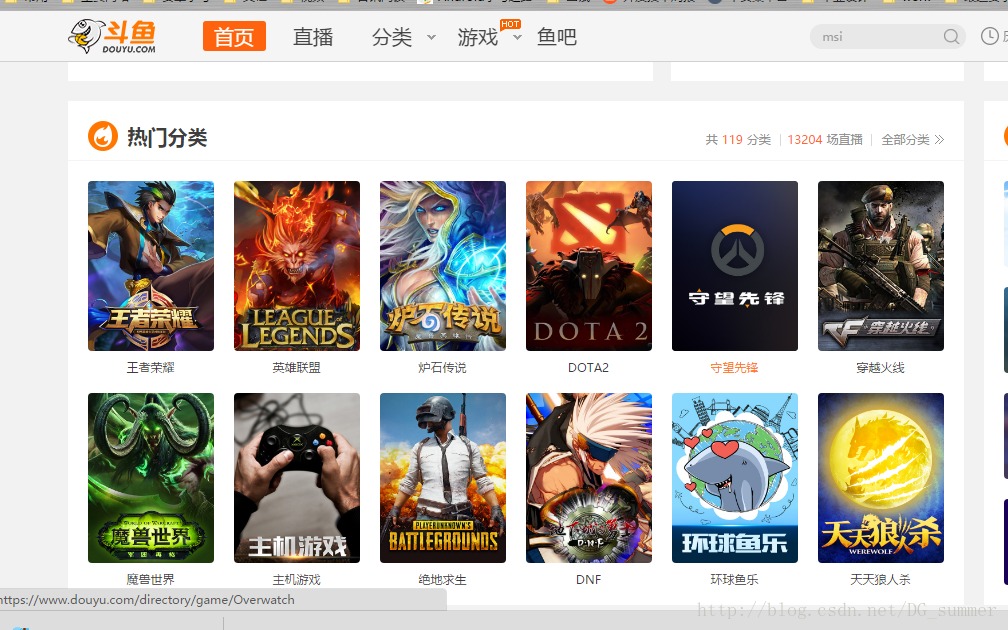
- 网站:斗鱼(http://www.douyu.com)
- 爬取目标:首页的图片
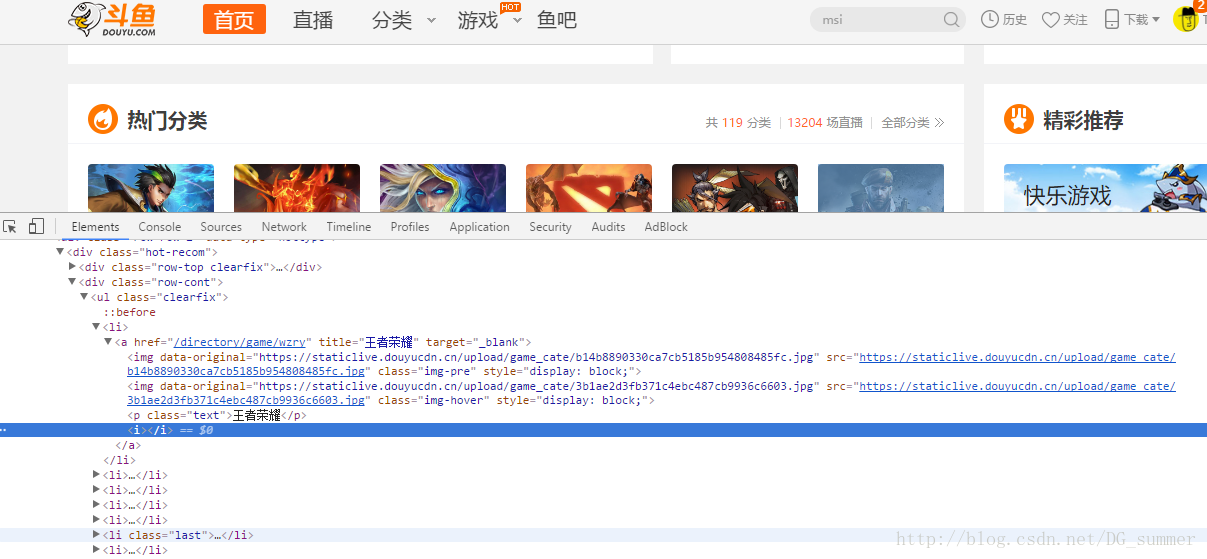
- 步骤一:查看图片信息,鼠标右键图片,选择检查
- 步骤二:分析发现图片连接都在src下面
- 步骤三:代码编写
- 导入库
import urllib
from bs4 import BeautifulSoup - 获取网页
import urllib
from bs4 import BeautifulSoup
f=urllib.urlopen("http://www.douyu.com")
html =f.read()
soup = BeautifulSoup(html, 'html.parser')- 匹配查询
ss=soup.find_all('img')
print ss
lenth=int(len(ss))
print lenth
for i in range(lenth):
url =ss[i].attrs['src']
print url
tad=url.rfind('.')
print tad
if tad>0:
str= url[tad+1:tad+4]
if str=='png':
print "this is png"
urllib.urlretrieve(url, './img2/png%d.png'%i)
elif str=='jpg':
print 'this is jpg'
urllib.urlretrieve(url, './img2/img%d.jpg' % i)
elif str=='gif':
print "this is gif"
urllib.urlretrieve(url, './img2/gif%d.gif' % i)
else:print "Error"
3.总结
获取图片的过程中,发现图片有jpg,png,和gif,于是通过字符串操作,把格式区分开来。