Python爬虫小试牛刀
1.分析pixiv.net的页面结构及xhr内容: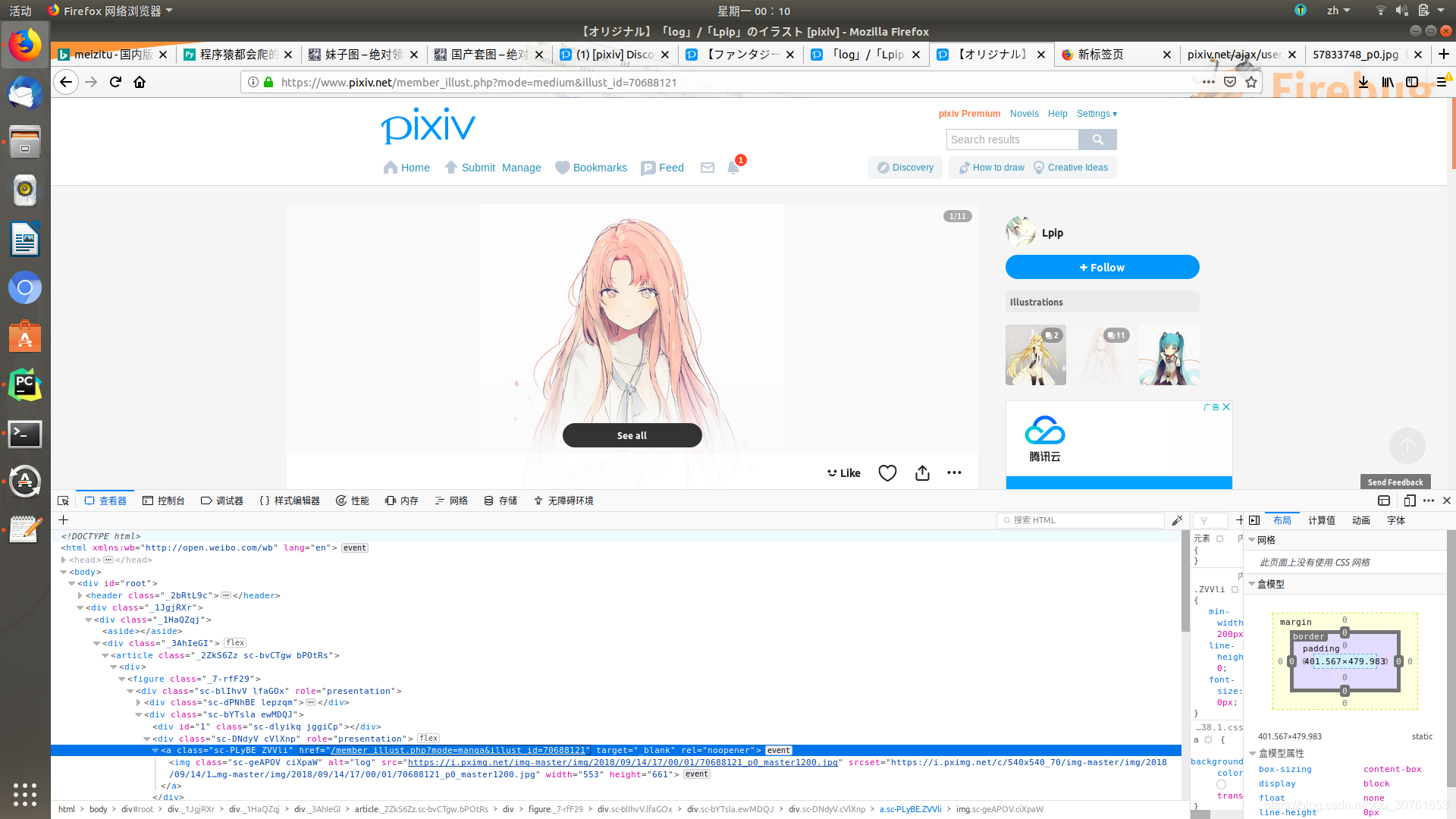
我们可以看到页面的图片不是原图,而是被压缩过的,并且发现html结构中的class name几乎都是随机无意义的字符串,很明显是为了反爬虫.继续分析
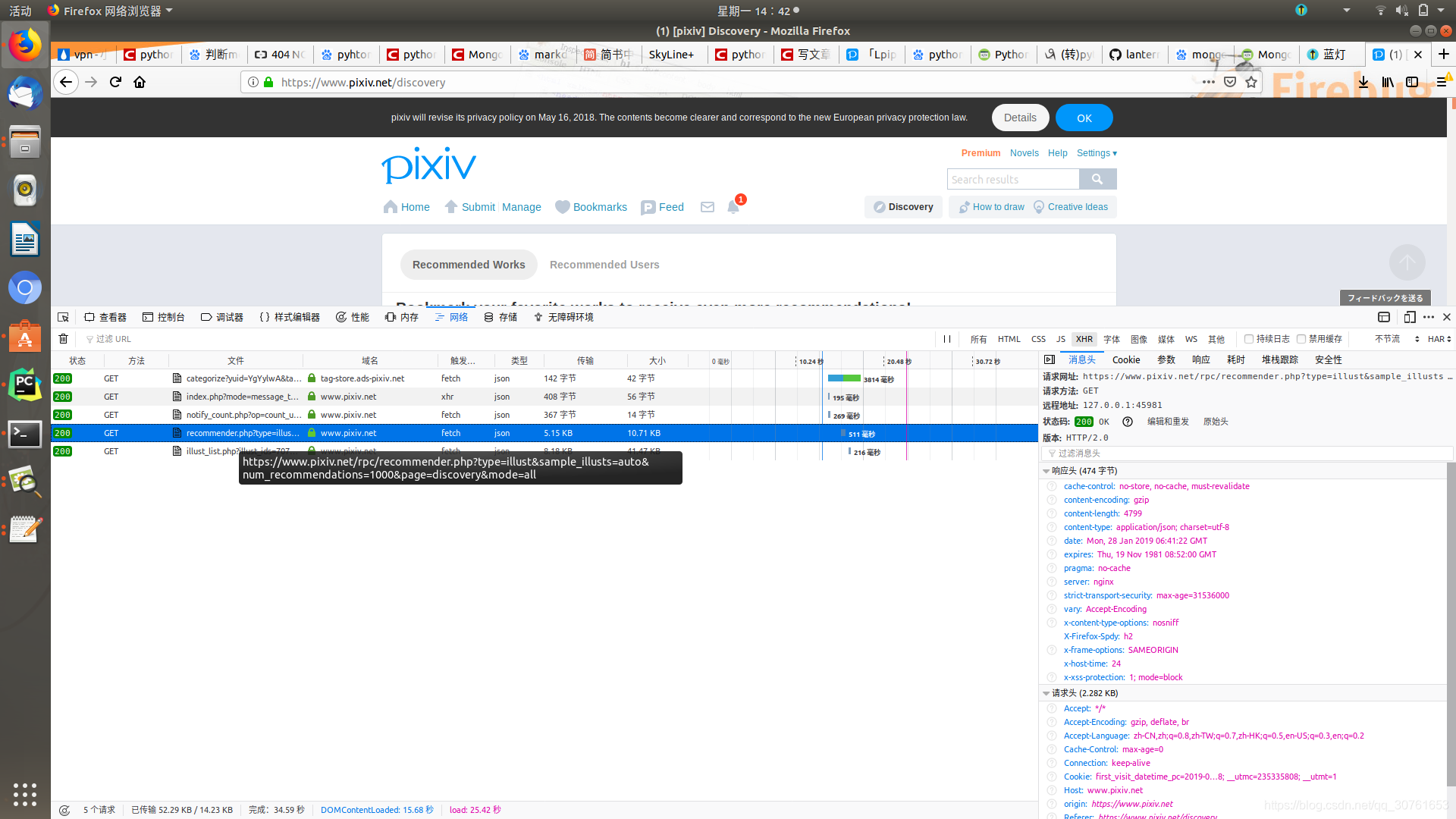 在里面出现了推荐的1000条作品id,可以直接用requests.get下载这个文件,json .loads找出id,十分省事.
在里面出现了推荐的1000条作品id,可以直接用requests.get下载这个文件,json .loads找出id,十分省事.
接下来打开作品详情页.
 我们搜索作品的id,竟然在html的script中发现的神奇的东西,很明显这一段script就是用来生成随机class name的东西.
我们搜索作品的id,竟然在html的script中发现的神奇的东西,很明显这一段script就是用来生成随机class name的东西.
{"illustId":"61048675","illustTitle":"\u53e4\u306e\u9b54\u5c0e\u6a5f\u68b0","id":"61048675","title":"\u53e4\u306e\u9b54\u5c0e\u6a5f\u68b0","illustType":0,"xRestrict":0,"restrict":0,"sl":2,"url":"https:\/\/i.pximg.net\/c\/250x250_80_a2\/img-master\/img\/2017\/01\/22\/01\/02\/01\/61048675_p0_square1200.jpg","description":"","tags":["\u30d5\u30a1\u30f3\u30bf\u30b8\u30fc","\u98a8\u666f","\u826f\u4f5c\u306f\u3075\u3068\u3057\u305f\u3068\u3053\u308d\u306b","\u30aa\u30ea\u30b8\u30ca\u30eb5000users\u5165\u308a"],"userId":"455626","width":3000,"height":1500,"pageCount":3,"isBookmarkable":true,"bookmarkData":null},"57833748"
把它复制出来. 搜索发现未压缩的图片url在"original":"https:\/\/i.pximg.net\/img-original\/img\/2016\/07\/10\/12\/16\/57\/57833748_p0.jpg"
用正则表达式及split整理出图片信息:
title = re.search('"illustTitle":"(.*?)"', jsr).group(1)
img_url_temp = re.search('"original":"(http.*?)"', jsr).group(1)
user_id = re.search('"userId":"(.*?)"', jsr).group(1)
img_url = ''.join(img_url_temp.split('\\'))
3.敲代码:
废话少说,直接上代码
requests时要加上lantern的本地代理地址,不然就会requests.exceptions.SSLError: HTTPSConnectionPool(host='www.pixiv.net', port=443): Max retries exceeded with url: /member_illust.php?mode=medium&illust_id=64930973 (Caused by SSLError(SSLError("bad handshake: SysCallError(104, 'ECONNRESET')",),)) 你会收到gfw送来的问候
#coding:utf-8
import requests
import json
import re
import pymongo
import random
import time
import logging
import os
class GetPixiv(object):
def __init__(self):
self.header = {'accept': '*/*',
'Cookie': '',#注意这里要放上从浏览器复制的cookies
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'referer': 'https://www.pixiv.net/discovery',
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) snap Chromium/71.0.3578.98 Chrome/71.0.3578.98 Safari/537.36', }
self.host = 'https://www.pixiv.net/member_illust.php?mode=medium&illust_id='
self.url = 'https://www.pixiv.net/rpc/recommender.php?type=illust&sample_illusts=auto&num_recommendations=1000&page=discovery&mode=all'
self.proxy = {'https': '127.0.0.1:45981'}
client = pymongo.MongoClient(host='127.0.0.1')
self.post = client['spider']['pixiv_illust_id']
self.logger = logging.getLogger(__name__)
self.logger.setLevel(level=logging.INFO)
handler = logging.FileHandler("pic_log.txt")
handler.setLevel(logging.INFO)
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
handler.setFormatter(formatter)
console = logging.StreamHandler()
console.setLevel(logging.INFO)
self.logger.addHandler(handler)
self.logger.addHandler(console)
if not os.path.exists('./img'):
os.mkdir('./img')
os.chdir('./img')
print('init finished.')
def down_pic(self):
jss = self.random_proxy_down_content(self.url)
print('download id list done.')
jrr = json.loads(jss)
ill_list = jrr['recommendations']
for ill in ill_list:
if self.post.find({'pic_id':ill}).count():#判断重复id
print(f'id {ill} already exists.')
continue
self.down_detail(ill)
def down_detail(self, ill):
try:
jsr = self.random_proxy_down_content(url=self.host + str(ill)).decode('utf-8')
print('download page source done.')
title = re.search('"illustTitle":"(.*?)"', jsr).group(1).encode()
img_url_temp = re.search('"original":"(http.*?)"', jsr).group(1)
user_id = re.search('"userId":"(.*?)"', jsr).group(1)
img_url = ''.join(img_url_temp.split('\\'))
illust_info = {}
illust_info['pic_id'] = ill
illust_info['user_id'] = user_id
illust_info['title'] = title
illust_info['url'] = img_url
self.post.insert(illust_info)
self.save_image(img_url, title,filepath='./')
print(f'process pic url:{img_url} done!')
except:
self.logger.error('Fail.', exc_info=True)
def save_image(self, img_url, title, filepath):
try:
afterfix = img_url.split('/')[-1]
filename = title + f'{afterfix}'
if not os.path.exists(filepath):
os.mkdir(filepath)
with open(f'{filepath}/{filename}', 'wb') as f:
img_content = self.random_proxy_down_content(img_url)
f.write(img_content)
print(f'save image done,current path is {os.getcwd()}')
except Exception as e:
self.logger.error('save image error.',exc_info=True)
def random_proxy_down_content(self, url):
time.sleep(random.randint(1, 4))
# random_header = self.header
# random_header['user-agent'] = random.choice(self.USER_AGENT_LIST)
content = requests.get(url, headers=self.header, proxies=self.proxy).content
print('request done.')
return content
def fetch_all_pic(self, user_id):
json_url = f'https://www.pixiv.net/ajax/user/{user_id}/profile/all'
json_content = self.random_proxy_down_content(json_url).decode()
json_pic = json.loads(json_content)
pic_list = json_pic['body']['illusts']
print('fetch pic list done.')
for pic in pic_list:
self.down_detail(pic)
#start download pic of pixiv
handler = GetPixiv()
handler.down_pic()
print('All done!')
本人比较懒,没有写详细的注释,不过都是基础的知识。。。
没有什么好办法来通过代理访问被墙网站,折衷的做法就是设置合理的延时,不然被反爬虫是迟早的
现在的一个问题是用’wb’模式打开image文件时写入的文件名是unicode格式的如\u8840\u5c0f\u677f
待解决。