文章目录
简介
决策树模型,自己总结了很久,也认为比较全面了。现在分享一下自己总结的东西。
这里面我只捡精炼的说,基本上都是干货,然后能用人话说的,我也不会疯狂排列数学公式。
初识决策树
- 决策树其实是用于分类的方法,尤其是二分类就是是非题,不过当然不限于二分,然后CART可以应用于分类和回归。其中对于回归的处理让我很是佩服。
- 树形结构模型,可以理解为if-else集合。
- 三个步骤
-
- 特征选择
-
- 生成决策树
-
- 剪枝
- 节点和有向边组成。
- 结点包括内节点(一个特征和属性) 叶子节点(一个类)
先看一下模型图
 每个有向边都是一条规则,节点出度规则是完备的。
每个有向边都是一条规则,节点出度规则是完备的。
图片来自https://baijiahao.baidu.com/s?id=1644346986352490804&wfr=spider&for=pc
- 算法基本流程
- 根据训练集生成决策树。
- 根据测试集剪枝。
特征选择
特征选择我们有一个潜意识里的认识,就是希望选取对于分类有帮助的特征。
那么这里采用信息增益的指标来判断。
什么是信息增益?
信息增益
- 什么是熵
用来度量随机变量的不确定性的,熵越大,不确定性越高。
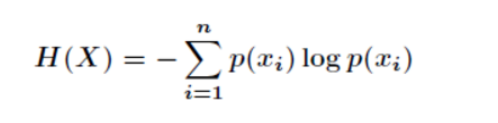


所以我们得到了信息增益的算法:

根据上述方法我们可以得到一个属性的排序。
信息增益比
根据上面的公式其实是更有益于选择那些属性值多的属性,这是需要改进的,所以我们增加一个分母。
得到信息增益比的定义:

ID3
知道了我们如何选择特征了,接下来就是生成决策树的算法了,一共有两种,先介绍一下ID3。
简单来说就是根据信息增益从大到小进行排序来选择结点。
算法简述:
- 从根节点开始,选择信息增益最大的属性来划分children结点。
- 然后选择每个孩子结点来作为根节点,再根据信息增益选择下一个属性来划分。
- 当信息增益小于阈值,或者没有剩余属性的时候停止。
C4.5
这里其实思想完全和ID3一样,唯一不同的就是使用的是信息增益比。
决策树剪枝
当我们把所有的属性或者过多的属性来生成决策树的时候,很可能过拟合,也就是说对于训练集有很好的表现,但是在真正的预测阶段不尽如人意。
所以我们进行剪枝操作:
- 极小化决策树整体损失函数。
首先来看一下损失函数的定义:

抱歉这里我写的有点乱,解释一下。
Nt表示的是叶子节点t有多少个样本点。
Ht(T)表示叶子节点t上的熵,然后求解方法和上面说到的熵的求解是一样的。
然后第二项是一个正则项,也就是把对模型的复杂度的要求加入进来。用|T|,叶子节点的个数来表示模型复杂度。
那么第一项就是整个模型的误差了,肯定是越小越好的。
然后α控制模型的复杂度,具体的在上述图片的下面。
- 剪枝的过程描述:
- 计算每个节点的经验熵
- 递归:从每个叶子结点回缩,也就是向上递归,如果去掉子树的随时函数小于不去掉之前的随时函数,就要剪枝。
CART 分类与回归树
简述:
假设:
-
CART是二叉树,左是右否
-
剪枝的时候使用测试集交叉验证,然后随时函数作为标准。
-
生成:回归树使用平方误差最小化,分裂树使用基尼指数。
回归树的生成
遵循最小二乘生成法
这里很难理解。
首先我们想要对于连续的数据使用树的结构来分解,最终就是得到的每个叶子节点一定是一个空间。然后在这个空间里面对应着预测值y。那么其中的关键就是如何将输入空间进行划分。
这里使用的是自启发的方法,来找到最优的分割点。(也叫决策点)


上面是统计学习一书中的解释,可能会有些晦涩,简单来说,大家可以联想最小二乘法,如果你对于最小二乘法的思想不理解的话,真的不可能看懂这个方法的精髓。
给大家推荐一个最小二乘法的blog,我认为写的非常好。
传送门
然后最终得到的x(j) = s,就是最优的决策点。然后用这个点来划分空间。
一个决策点就划分了两个空间,然后在对这两个空间使用同样的方法。将连续的数据使用离散的模型表示出来了。
由此决策树的生成就完成了。
分类树的生成
分类树的生成使用的是基尼系数。其实基尼系数和信息增益所表达的是一样的。
定义:基尼指数(基尼不纯度):表示在样本集合中一个随机选中的样本被分错的概率。
Gini指数越小表示集合中被选中的样本被分错的概率越小,也就是说集合的纯度越高,反之,集合越不纯。
基尼指数(基尼不纯度)= 样本被选中的概率 * 样本被分错的概率
所以这里树的生成和ID3同样是一样的。不在多赘述。
CART剪枝
CART的剪枝有些复杂,目的是生成一个子树序列,然后通过交叉验证来选择最优子树。

优缺点
决策树
优点
-
决策树易于理解和解释,可以可视化分析,容易提取出规则;
-
可以同时处理标称型和数值型数据;
-
比较适合处理有缺失属性的样本;
-
能够处理不相关的特征;
-
测试数据集时,运行速度比较快;
-
在相对短的时间内能够对大型数据源做出可行且效果良好的结果。
缺点
-
容易发生过拟合(随机森林可以很大程度上减少过拟合);
-
容易忽略数据集中属性的相互关联;
-
对于那些各类别样本数量不一致的数据,在决策树中,进行属性划分时,不同的判定准则会带来不同的属性选择倾向;信息增益准则对可取数目较多的属性有所偏好(典型代表ID3算法),而增益率准则(CART)则对可取数目较少的属性有所偏好,但CART进行属性划分时候不再简单地直接利用增益率尽心划分,而是采用一种启发式规则)(只要是使用了信息增益,都有这个缺点,如RF)。
-
ID3算法计算信息增益时结果偏向数值比较多的特征。
改进措施
-
对决策树进行剪枝。可以采用交叉验证法和加入正则化的方法;
-
使用基于决策树的combination算法,如bagging算法,randomforest算法,可以解决过拟合的问题。
ID3、C4.5算法
优点
产生的分类规则易于理解,准确率较高。
缺点
-
在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效;
-
C4.5只适合于能够驻留于内存的数据集,当训练集大得无法在内存容纳时程序无法运行。
CART分类与回归树
优点
-
非常灵活,可以允许有部分错分成本,还可指定先验概率分布,可使用自动的成本复杂性剪枝来得到归纳性更强的树;
-
在面对诸如存在缺失值、变量数多等问题时CART 显得非常稳健。
适用场景
企业管理实践,企业投资决策,由于决策树很好的分析能力,在决策过程应用较多。
代码
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
from sklearn.tree import DecisionTreeClassifier
def iris_type(s):
it = {b'Iris-setosa': 0, b'Iris-versicolor': 1, b'Iris-virginica': 2}
return it[s]
iris_feature = u'花萼长度', u'花萼宽度', u'花瓣长度', u'花瓣宽度'
if __name__ == "__main__":
mpl.rcParams['font.sans-serif'] = [u'SimHei']
mpl.rcParams['axes.unicode_minus'] = False
path = '../dataSet/iris.data' # 数据文件路径
data = np.loadtxt(path, dtype=float, delimiter=',', converters={4: iris_type})
x_prime, y = np.split(data, (4,), axis=1)
feature_pairs = [[0, 1], [0, 2], [0, 3], [1, 2], [1, 3], [2, 3]]
plt.figure(figsize=(10, 9), facecolor='#FFFFFF')
for i, pair in enumerate(feature_pairs):
# 准备数据
x = x_prime[:, pair]
# 决策树学习
clf = DecisionTreeClassifier(criterion='entropy', min_samples_leaf=3)
dt_clf = clf.fit(x, y)
# 画图
N, M = 500, 500
x1_min, x1_max = x[:, 0].min(), x[:, 0].max()
x2_min, x2_max = x[:, 1].min(), x[:, 1].max()
t1 = np.linspace(x1_min, x1_max, N)
t2 = np.linspace(x2_min, x2_max, M)
x1, x2 = np.meshgrid(t1, t2)
x_test = np.stack((x1.flat, x2.flat), axis=1)
y_hat = dt_clf.predict(x)
y = y.reshape(-1)
c = np.count_nonzero(y_hat == y) # 统计预测正确的个数
print('特征: ', iris_feature[pair[0]], ' + ', iris_feature[pair[1]])
print('\t预测正确数目:', c)
print('\t准确率: %.2f%%' % (100 * float(c) / float(len(y))))
# 显示
cm_light = mpl.colors.ListedColormap(['#A0FFA0', '#FFA0A0', '#A0A0FF'])
cm_dark = mpl.colors.ListedColormap(['g', 'r', 'b'])
y_hat = dt_clf.predict(x_test) # 预测值
y_hat = y_hat.reshape(x1.shape)
plt.subplot(2, 3, i+1)
plt.pcolormesh(x1, x2, y_hat, cmap=cm_light)
plt.scatter(x[:, 0], x[:, 1], c=y, edgecolors='k', cmap=cm_dark)
plt.xlabel(iris_feature[pair[0]], fontsize=14)
plt.ylabel(iris_feature[pair[1]], fontsize=14)
plt.xlim(x1_min, x1_max)
plt.ylim(x2_min, x2_max)
plt.grid()
plt.suptitle(u'决策树对鸢尾花数据的两特征组合的分类结果', fontsize=18)
plt.tight_layout(2)
plt.subplots_adjust(top=0.92)
plt.show()
代码来自https://www.cnblogs.com/baby-lily/p/10646226.html
大家共勉~
欢迎指正