1、HDFS 2.0 基本概念
相比于 Hadoop 1.0,Hadoop 2.0 中的 HDFS 增加了两个重大特性,HA 和 Federaion。HA 即为 High Availability,用于解决 NameNode 单点故障问题,该特性通过热备的方式为主 NameNode 提供一个备用者,一旦主 NameNode 出现故障,可以迅速切换至备 NameNode, 从而实现不间断对外提供服务。Federation 即为“联邦”,该特性允许一个 HDFS 集群中存在 多个 NameNode 同时对外提供服务,这些 NameNode 分管一部分目录(水平切分),彼此之 间相互隔离,但共享底层的 DataNode 存储资源。
本文档重点介绍 HDFS HA 的安装部署方法。
2、HDFS HA 配置部署
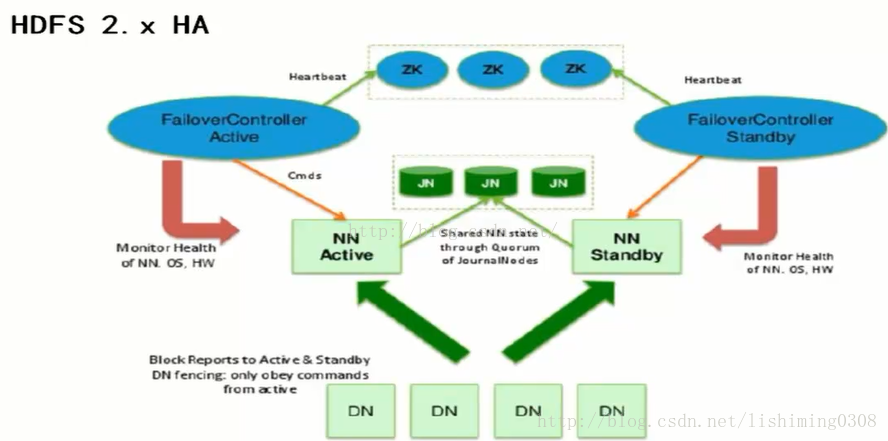
在一个典型的 HDFS HA 场景中,通常由两个 NameNode 组成,一个处于 active 状态, 另一个处于 standby 状态。Active NameNode 对外提供服务,比如处理来自客户端的 RPC 请 求,而 Standby NameNode 则不对外提供服务,仅同步 active namenode 的状态,以便能够在 它失败时快速进行切换。
为了能够实时同步 Active 和 Standby 两个 NameNode 的元数据信息(实际上 editlog), 需提供一个共享存储系统,可以是 NFS、QJM(Quorum Journal Manager)或者 Bookeeper, Active Namenode 将数据写入共享存储系统,而 Standby 监听该系统,一旦发现有新数据写 入,则读取这些数据,并加载到自己内存中,以保证自己内存状态与 Active NameNode 保持 基本一致,如此这般,在紧急情况下 standby 便可快速切为 active namenode。
注意,在 Hadoop 2.0 中,不再需要 secondary namenode 或者 backup namenode,它们的 工作由 Standby namenode 承担。
本文将重点介绍基于 QJM 的 HA 解决方案。在该方案中,主备 NameNode 之间通过一 组 JournalNode 同步元数据信息,一条数据只要成功写入多数 JournalNode 即认为写入成功。 通常配置奇数个(2N+1)个 JournalNode,这样,只要 N+1 个写入成功就认为数据写入成功, 此时最多容忍 N-1 个 JournalNode 挂掉,比如 3 个 JournalNode 时,最多允许 1 个 JournalNode 挂掉,5 个 JournalNode 时,最多允许 2 个 JournalNode 挂掉。基于 QJM 的 HDFS 架构如下 所示:
3. 环境说明
三台虚拟机,每台虚拟机安装ubantu16.04。每台机器的名称,IP地址,进程内容如下
| 主机名称 | 操作系统 | IP地址 | 用户名 | 密码 | 进程 |
|---|---|---|---|---|---|
| master | ubuntu16.04LTS | 192.168.80.130 | hadoop | admin@123 | NameNode,ResourceManager,JournalNode,QuorumPeerMain,DFSZKFailoverController,JobHistoryServer |
| host2 | ubuntu16.04LTS | 192.168.80.131 | hadoop | admin@123 | NameNode,DataNode,ResourceManager,NodeManager,JournalNode,QuorumPeerMain,DFSZKFailoverController |
| host3 | ubuntu16.04LTS | 192.168.80.132 | hadoop | admin@123 | NodeManager,DataNode,QuorumPeerMain,JournalNode |
进程介绍:
NameNode:NameNode(管理者)
ResourceManager:YARN中的资源管理器(Resource Manager)负责整个系统的资源管理和调度,并内 部维护了各个应用程序的ApplictionMaster信息,NodeManager信息,资源使用信息等
DataNode:DataNode(工作者)
NodeManager:NodeManager(NM)是YARN中每个节点上的代理,它管理Hadoop集群中单个计算节点,包括与ResourceManger保持通信,监督Container的生命周期管理,监控每个Container的资源使用(内存、CPU等)情况,追踪节点健康状况,管理日志和不同应用程序用到的附属服务(auxiliary service)。
JournalNode:JournalNode是用于存储hdfs中,NameNode的操作日志(也就是edits)的,一般由单数个(3个以上)节点组成,保证对于edits的高可靠存储
QuorumPeerMain:Zookeeper服务
DFSZKFailoverController:zookeeper客户端,用于自动切换ActiveNameNode
JobHistoryServer:实现web查看作业的历史运行情况
4. 安装包准备
需要上网下载收集hadoop-2.7.0.tar.gz、jdk-1.7.tar.gz、zookeeper-3.4.6.tar.gz、jsch-0.1.54.jar
注意:jsch-0.1.54.jar用于替换hadoop-2.7.0.tar.gz中自带的jsch-0.1.42.jar,以解决在自动备援中出现的连接错误,而无法实现自动备援。
5. 关闭防火墙
//切换到超级用户
su root
//关闭防火墙
ufw disable
6. 安装vim编辑器和ssh
//安装vim编辑器
sudo apt-get install vim
//安装ssh
sudo apt-get insatll ssh//查看ssh是否安装成功
service ssh status//生成秘钥,在所有机器上执行下命令生成公钥。将所有公钥放在一个文件中。
ssh-keygen -t rsa//进入ssh目录
cd ~/.ssh //(把公钥复制一份,并改名为authorized_keys,这步执行完,应该ssh localhost可以无密码登录本机了,可能第一次要密码)
cp id_rsa.pub authorized_keys//修改authorized_keys权限
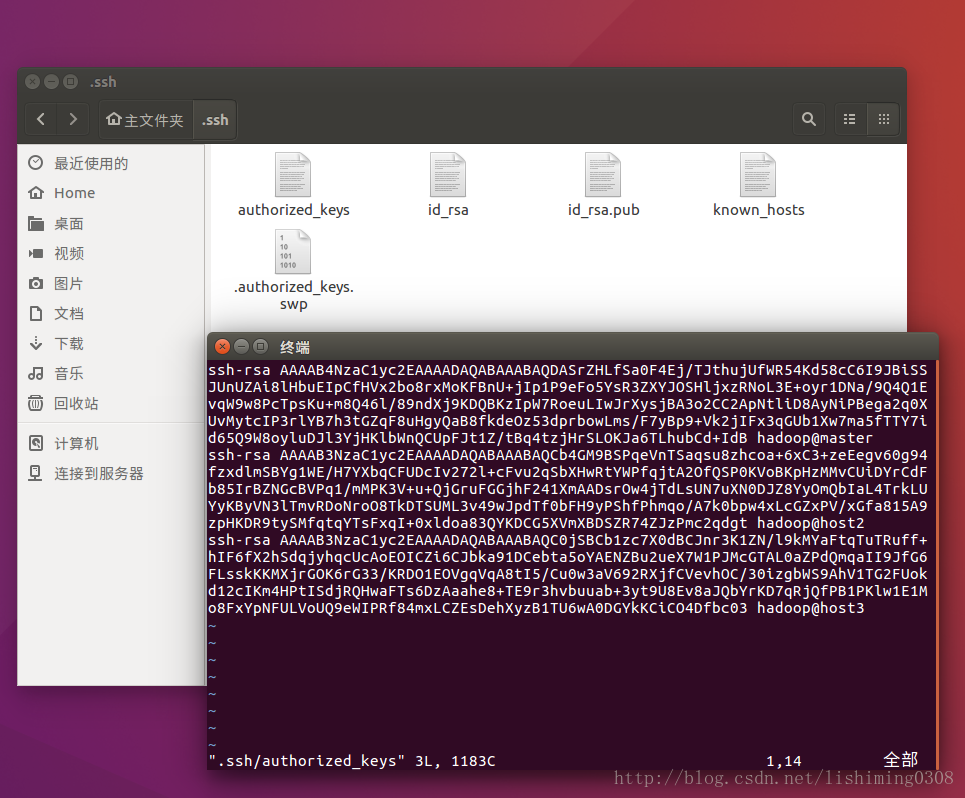
chmod 644 authorized_keys注意:这三台机器生成的rsa.pub中的内容合并到authorized_keys中,然后将authorized_keys更新到每台机器的主目录下的.ssh目录中。以实现各台主机的不需要用户名密码登录。最后整合的authorized_keys如下图
在master主机上使用命令
//首次使用会提示输入用户名和密码,之后在使用就不用输入用户名和密码了
ssh host2
7. 修改主机名和主机和IP映射列表
//修改主机名
sudo vim /etc/hostname
//修改主机名称和IP地址列表
sudo vim /etc/hosts
8.安装JDK
//将jdk解压到/usr/lib文件夹中
//进入当前目录
cd /usr/lib //使用tar命令解压jdk压缩包
sudo tar -zxvf ~/下载/jdk-1.7.tar.gz 
设置环境变量
sudo gedit ~/.bashrc
在最下面添加:
export JAVA_HOME=/usr/lib/jdk1.7.0_51
export PATH=$JAVA_HOME/bin:$PATH
使配置文件生效
source ~/.bashrc让
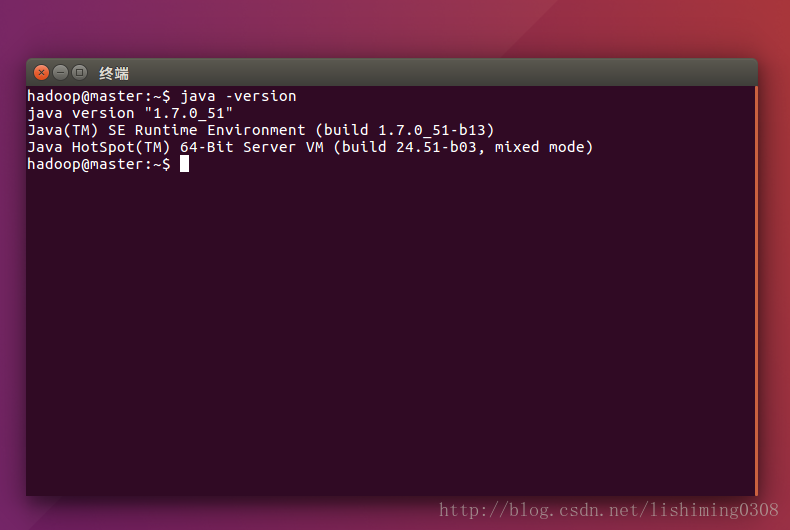
//查看jdk是否安装成功
java -version
9.安装zookeeper
//进入/usr/local目录
cd /usr/local
sudo tar -zxvf ~/下载/zookeeper-3.4.6.tar.gz
sudo chown -R hadoop /usr/local/zookeeper-3.4.6///设置环境变量
sudo gedit ~/.bashrc
export ZOOKEEPER_HOME=/usr/local/zookeeper-3.4.6
export PATH=$ZOOKEEPER_HOME/bin:$ZOOKEEPER_HOME/conf:$PATH
source ~/.bashrc//新建zoo.cfg并修改
cp conf/zoo_sample.cfg conf/zoo.cfg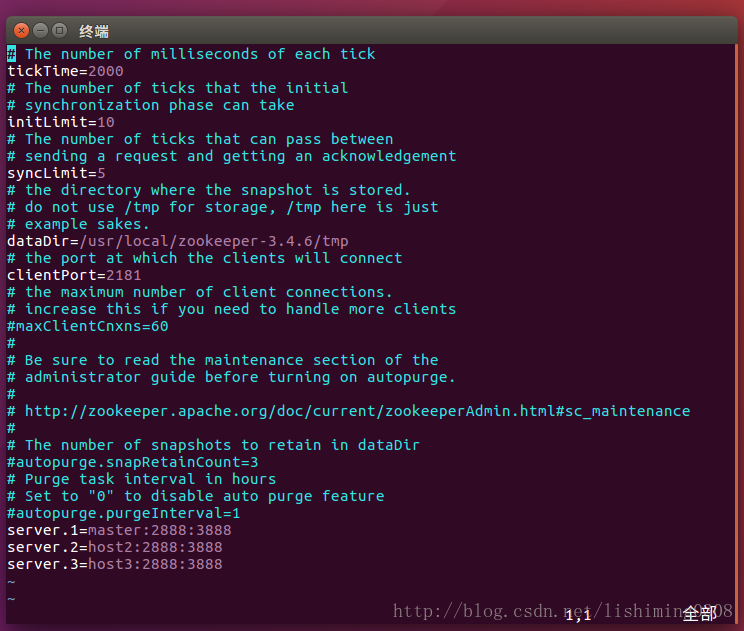
参数说明:
①tickTime:心跳时间,毫秒为单位。
②initLimit:这个配置项是用来配置 Zookeeper 接受客户端(这里所说的客户端不是用户连接 Zookeeper服务器的客户端,而是 Zookeeper 服务器集群中连接到 Leader 的 Follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。当已经超过 10 个心跳的时间(也就是 tickTime)长度后 Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是 10*2000=20 秒。
③syncLimit:这个配置项标识 Leader 与 Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个 tickTime 的时间长度,总的时间长度就是 5*2000=10 秒。
④dataDir:存储内存中数据库快照的位置。
⑤clientPort:监听客户端连接的端口
⑥server.A=B:C:D:其中 A 是一个数字,表示这个是第几号服务器;B 是这个服务器的 ip 地址;C 表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;D 表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。如果是伪集群的配置方式,由于 B 都是一样,所以不同的 Zookeeper 实例通信端口号不能一样,所以要给它们分配不同的端口号。
5)dataDir目录下创建myid文件,将内容设置为上⑥中的A值,用来标识不同的服务器
cd /usr/local/zookeeper-3.4.6/
mkdir tmp
cd tmp
touch myid
vim myid
10.安装Hadoop
//将hadoop解压到/usr/local文件夹中
// 进入当前目录
cd /usr/local//使用tar命令解压jdk压缩包
sudo tar -zxvf ~/下载/hadoop-2.7.0.tar.gz 注意:将jsch-0.1.42.jar替换为jsch-0.1.54.jar解决namenode节点无法切换问题,产生原因是openssh-server7与jsch-0.1.42.jar不兼容。
//修改文件权限
sudo chown -R hadoop /usr/local/hadoop-2.7.0 //修改环境变量,将hadoop加进去
sudo gedit ~/.bashrc
export HADOOP_HOME=/usr/local/hadoop-2.7.0
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
source ~/.bashrc修改/usr/local/hadoop-2.7.0/etc/hadoop下配置文件hadoop-env.sh、hdfs-site.xml、core-site.xml、slaves、 mapred-site.xml、yarn-site.xml
文件 slaves,将作为 DataNode 的主机名写入该文件,每行一个。
文件 core-site.xml 改为下面的配置
<configuration>
<!-- 指定hdfs的nameservice为ns -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-ha</value>
</property>
<!--指定hadoop数据临时存放目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop-2.7.0/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!--指定zookeeper地址-->
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,host2:2181,host3:2181</value>
</property> - 文件 hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop-2.7.0/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop-2.7.0/tmp/dfs/data</value>
</property>
<!--指定hdfs的nameservice为hadoop-ha,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>hadoop-ha</value>
</property>
<!-- hadoop-ha下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.hadoop-ha</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.hadoop-ha.nn1</name>
<value>master:8020</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.hadoop-ha.nn2</name>
<value>host2:8020</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.hadoop-ha.nn1</name>
<value>master:50070</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.hadoop-ha.nn2</name>
<value>host2:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;host2:8485;host3:8485/hadoop-ha</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/hadoop-2.7.0/journaldata</value>
</property>
<property>
<name>dfs.journalnode.rpc-address</name>
<value>0.0.0.0:8485</value>
</property>
<property>
<name>dfs.journalnode.http-address</name>
<value>0.0.0.0:8480</value>
</property>
<!-- 开启NameNode故障时自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.hadoop-ha</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<name>ha.failover-controller.cli-check.rpc-timeout.ms</name>
<value>60000</value>
</property>
<property>
<name>ipc.client.connect.timeout</name>
<value>60000</value>
</property>
<property>
<name>dfs.image.transfer.bandwidthPerSec</name>
<value>4194304</value>
</property>
</configuration>- 文件 mapred-site.xml
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/history/done</value>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/history/done_intermediate</value>
</property>
</configuration>- 文件 yarn-site.xml
<configuration>
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>host2</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>master:2181,host2:2181,host3:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>11.拷贝到其他节点
配置好后,将 master 上的
/usr/local/Hadoop-2.7.0
/usr/local/zookeeper-3.4.6
/usr/lib/jdk1.7.0_51
~/.bashrc
将这四个文件和目录拷贝到其他节点上
12.初次配置后启动顺序
12.1 启动zookeeper集群
分别在master、host2、host3上执行如下命令启动zookeeper集群;
[hadoop@master]$zkServer.sh start
验证集群zookeeper集群是否启动,分别在master、host2、host3上执行如下命令验证zookeeper集群是否启动,集群启动成功,有两个follower节点跟一个leader节点
[hadoop@master]$zkServer.sh status
JMX enabled by default
Using config: /usr/local/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: follower
12.2 启动journalnode集群
在master上执行如下命令完成JournalNode集群的启动
[hadoop@master]$hadoop-daemons.sh start journalnode
执行jps命令,可以查看到JournalNode的java进程pid
12.3 格式化zkfc,让在zookeeper中生成ha节点
在master上执行如下命令,完成格式化
hdfs zkfc –formatZK
(注意,这条命令最好手动输入,直接copy执行有可能会有问题,当时部署时我是蛋疼了许久)
格式成功后,查看zookeeper中可以看到
[zk: localhost:2181(CONNECTED) 1] ls /hadoop-ha
[ns]
12.4 格式化hdfs
hadoop namenode –format
(注意,这条命令最好手动输入,直接copy执行有可能会有问题)
12.5 启动NameNode
首先在master上启动active节点,在master上执行如下命令
[hadoop@master]$hadoop-daemon.sh start namenode
//在host2上同步namenode的数据,同时启动standby的namenod,命令如下 把namenode的数据同步到host2上
[hadoop@host2]
12.6 启动启动datanode
在mast1上执行如下命令
[hadoop@master]$hadoop-daemons.sh start datanode
12.7 启动yarn
在作为资源管理器上的机器上启动,我这里是master,执行如下命令完成yarn的启动
[hadoop@master]$ start-yarn.sh
12.8 启动ZKFC
在master上执行如下命令,完成ZKFC的启动
[hadoop@master]
13.正常启动顺序
//在各个节点上启动zookeeper
zkServer.sh start在master启动hadoop集群
start-dfs.sh在master启动yarn框架
start-yarn.sh//在备份节点host2上启动yarn
yarn-daemon.sh start resourcemanager在master上启动
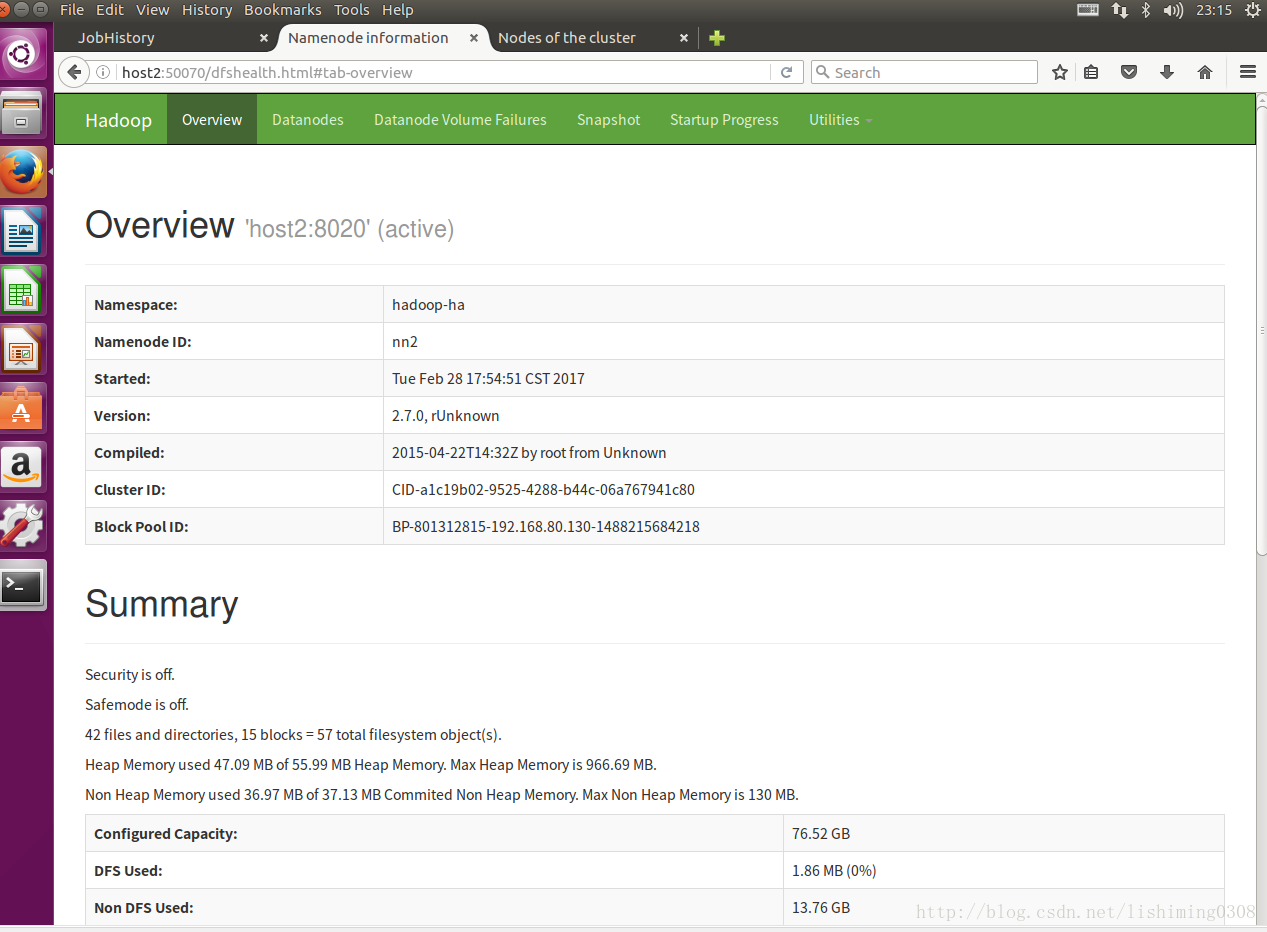
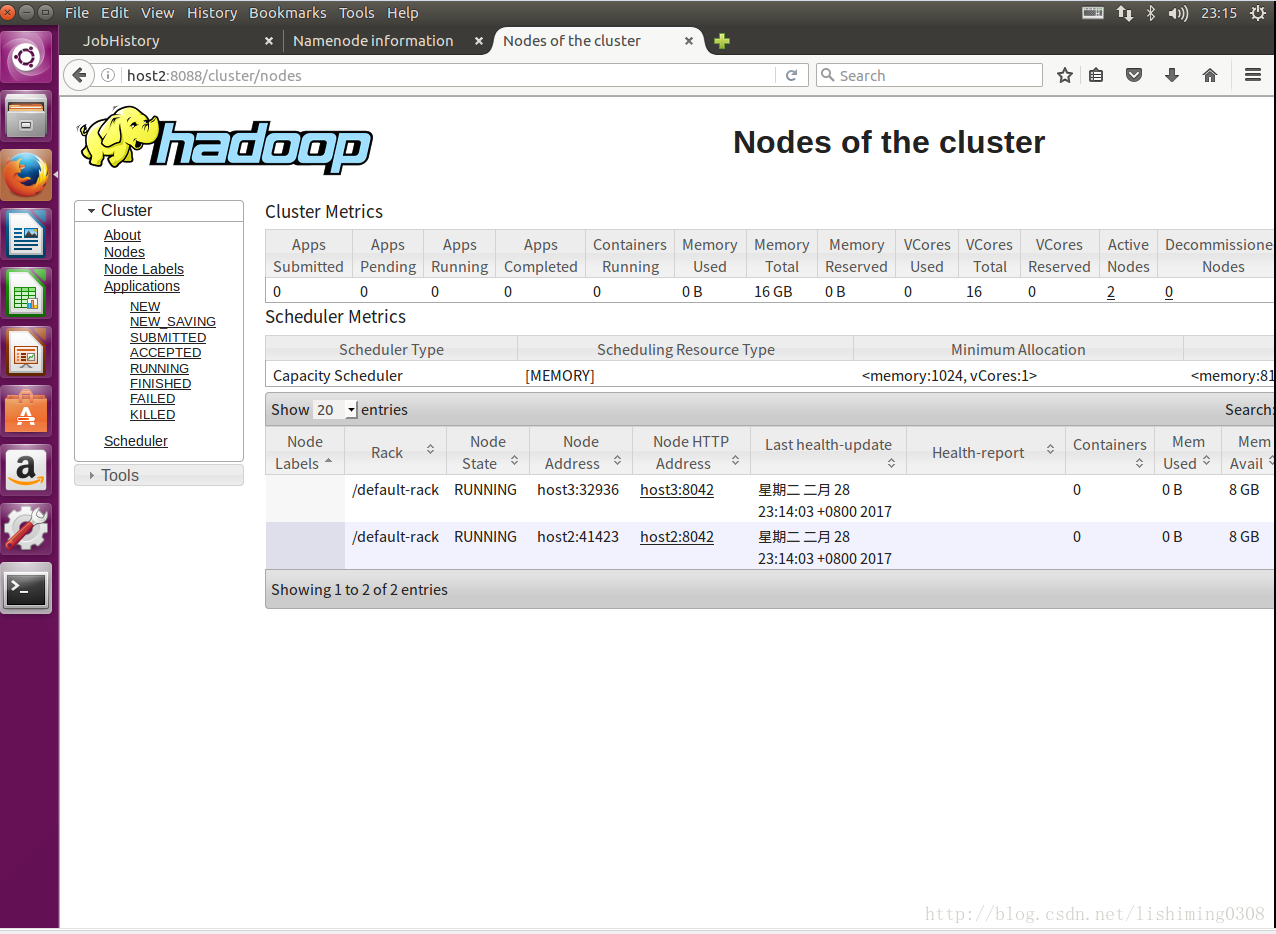
mr-jobhistory-daemon.sh start historyserver14.Web访问截图