一、安装ntp服务器
在master上:
安装ntp服务器
root@zqq-0217:/home/zqq-0217# apt install ntp
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following additional packages will be installed:
libopts25
Suggested packages:
ntp-doc
The following NEW packages will be installed:
libopts25 ntp
0 upgraded, 2 newly installed, 0 to remove and 0 not upgraded.
Need to get 576 kB of archives.
After this operation, 1,792 kB of additional disk space will be used.
Do you want to continue? [Y/n] y
Get:1 https://mirrors.tuna.tsinghua.edu.cn/ubuntu xenial/main amd64 libopts25 amd64 1:5.18.7-3 [57.8 kB]
Get:2 https://mirrors.tuna.tsinghua.edu.cn/ubuntu xenial-updates/main amd64 ntp amd64 1:4.2.8p4+dfsg-3ubuntu5.9 [519 kB]
Fetched 576 kB in 2s (210 kB/s)
Selecting previously unselected package libopts25:amd64.
(Reading database ... 92234 files and directories currently installed.)
Preparing to unpack .../libopts25_1%3a5.18.7-3_amd64.deb ...
Unpacking libopts25:amd64 (1:5.18.7-3) ...
Selecting previously unselected package ntp.
Preparing to unpack .../ntp_1%3a4.2.8p4+dfsg-3ubuntu5.9_amd64.deb ...
Unpacking ntp (1:4.2.8p4+dfsg-3ubuntu5.9) ...
Processing triggers for libc-bin (2.23-0ubuntu11) ...
Processing triggers for man-db (2.7.5-1) ...
Processing triggers for ureadahead (0.100.0-19.1) ...
Processing triggers for systemd (229-4ubuntu21.22) ...
Setting up libopts25:amd64 (1:5.18.7-3) ...
Setting up ntp (1:4.2.8p4+dfsg-3ubuntu5.9) ...
Processing triggers for libc-bin (2.23-0ubuntu11) ...
Processing triggers for ureadahead (0.100.0-19.1) ...
Processing triggers for systemd (229-4ubuntu21.22) ...
修改配置:
vi /etc/ntp.conf
找到下面这段,将访问网络限制取消注释,并修改可以访问的网段(最后一句)
# Clients from this (example!) subnet have unlimited access, but only if
# cryptographically authenticated.
restrict 0.0.0.0 mask 255.255.255.0 notrust
重新启动服务,查看服务状态
root@zqq-0217:/home/zqq-0217# service ntp restart
root@zqq-0217:/home/zqq-0217# service ntp status
● ntp.service - LSB: Start NTP daemon
Loaded: loaded (/etc/init.d/ntp; bad; vendor preset: enabled)
Active: active (running) since Thu 2019-11-07 15:57:00 CST; 8s ago
Docs: man:systemd-sysv-generator(8)
Process: 49556 ExecStop=/etc/init.d/ntp stop (code=exited, status=0/SUCCESS)
Process: 49569 ExecStart=/etc/init.d/ntp start (code=exited, status=0/SUCCESS)
Tasks: 2
Memory: 660.0K
CPU: 29ms
CGroup: /system.slice/ntp.service
└─49584 /usr/sbin/ntpd -p /var/run/ntpd.pid -g -u 111:117
Nov 07 15:57:04 zqq-0217 ntpd[49584]: Soliciting pool server 120.25.115.20
Nov 07 15:57:04 zqq-0217 ntpd[49584]: Soliciting pool server 162.159.200.1
Nov 07 15:57:05 zqq-0217 ntpd[49584]: Soliciting pool server 139.199.215.251
Nov 07 15:57:05 zqq-0217 ntpd[49584]: Soliciting pool server 2a03:8600::ff
Nov 07 15:57:05 zqq-0217 ntpd[49584]: Soliciting pool server 185.255.55.20
Nov 07 15:57:06 zqq-0217 ntpd[49584]: Soliciting pool server 62.210.205.24
Nov 07 15:57:06 zqq-0217 ntpd[49584]: Soliciting pool server 203.107.6.88
Nov 07 15:57:07 zqq-0217 ntpd[49584]: Soliciting pool server 193.182.111.142
Nov 07 15:57:07 zqq-0217 ntpd[49584]: Soliciting pool server 91.189.94.4
Nov 07 15:57:08 zqq-0217 ntpd[49584]: Soliciting pool server 91.189.91.157
开放防火墙端口,ntp使用udp 123端口
root@zqq-0217:/home/zqq-0217# ufw allow 123/udp
Rules updated
Rules updated (v6)
在slave1、slave2、slave3上面配置ntp客户端
以slave1为例:
-
安装ntpdate,测试ntp工具
root@hj-0219:/home/ubuntu-hj# apt install ntpdate Reading package lists... Done Building dependency tree Reading state information... Done The following NEW packages will be installed: ntpdate 0 upgraded, 1 newly installed, 0 to remove and 131 not upgraded. Need to get 48.6 kB of archives. After this operation, 173 kB of additional disk space will be used. Get:1 https://mirrors.tuna.tsinghua.edu.cn/ubuntu xenial-updates/main amd64 ntpdate amd64 1:4.2.8p4+dfsg-3ubuntu5.9 [48.6 kB] Fetched 48.6 kB in 1s (35.7 kB/s) Selecting previously unselected package ntpdate. (Reading database ... 60388 files and directories currently installed.) Preparing to unpack .../ntpdate_1%3a4.2.8p4+dfsg-3ubuntu5.9_amd64.deb ... Unpacking ntpdate (1:4.2.8p4+dfsg-3ubuntu5.9) ... Processing triggers for man-db (2.7.5-1) ... Setting up ntpdate (1:4.2.8p4+dfsg-3ubuntu5.9) ... -
测试ntp服务器是否可用,(如有提示“ntpdate[XXX]: the ntp socket is in use, exiting”, 可加参数 -u )
root@hj-0219:/home/ubuntu-hj# ntpdate 192.168.160.128 7 Nov 16:24:45 ntpdate[3054]: adjust time server 192.168.160.128 offset 0.034552 sec -
停止ubuntu自带的时间同步服务
root@hj-0219:/etc# timedatectl set-ntp off -
安装ntp
-
修改/etc/ntp.conf文件,添加以下内容: (ip为master的ip)
server 192.168.160.128 prefer iburst -
重启ntp服务,查看同步状态
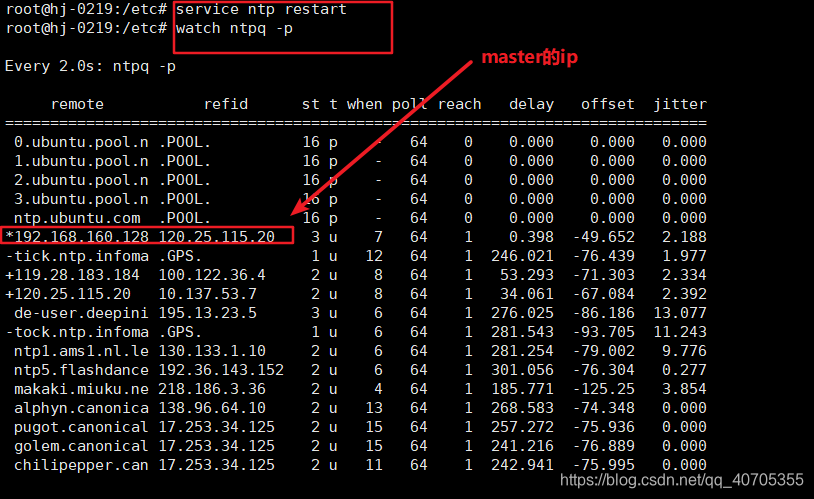
7. 可以看到已经完成同步了,在slave2和slave3上完成同样的操作
二、集群搭建
在master的/etc/hosts配置:集群的ip和主机号
192.168.160.128 zqq-0217
192.168.160.130 hj-0219
192.168.160.131 lx-0216
192.168.160.132 ly-0215
# The following lines are desirable for IPv6 capable hosts
::1 localhost ip6-localhost ip6-loopback
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
保存之后,将主节点的hosts分别拷贝到其他三个子节点
命令行分别输入:
scp /etc/hosts root@192.168.160.130:/etc/
scp /etc/hosts root@192.168.160.131:/etc/
scp /etc/hosts root@192.168.160.132:/etc/
会遇见以下错误:
root@zqq-0217:/home/zqq-0217# scp /etc/hosts [email protected]:/etc/
[email protected]'s password:
Permission denied, please try again.
[email protected]'s password:
Permission denied, please try again.
[email protected]'s password:
Permission denied (publickey,password).
lost connection
解决方法:
修改/etc/ssh/sshd_config文件,修改PermitRootLogin的值为yes
# Authentication:
LoginGraceTime 120
# PermitRootLogin prohibit-password
PermitRootLogin yes
StrictModes yes
就可以在相互之间复制文件了
三、配置SSM无密码访问
1.生成公钥密钥对
在每一个节点上分别执行:ssh-keygen -t rsa
一直回车直到结束
执行结束后会在/root/.ssh/目录下生成两个文件id_rsa和id_rsa.pub
id_rsa是私钥,id_rsa.pub是公钥
将公钥拷贝一份重命名为 authorized_keys
在master上执行命令:
cp id_rsa.pub authorized_keys
2.将子节点的公钥拷贝到主节点并添加到authorized_keys
将三个子节点的公钥拷贝到主节点上
scp root@hj-0219:/root/.ssh/id_rsa.pub /root/.ssh/id_rsa_slave1.pub
scp root@lx-0216:/root/.ssh/id_rsa.pub /root/.ssh/id_rsa_slave2.pub
scp root@ly-0215:/root/.ssh/id_rsa.pub /root/.ssh/id_rsa_slave3.pub
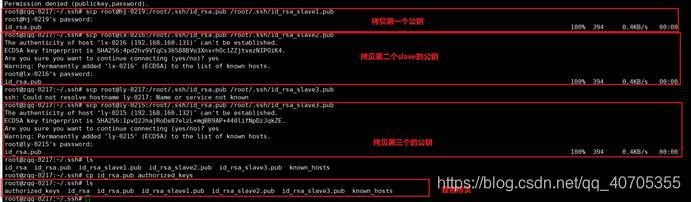
将拷贝过来的三个公钥合并到authorized_keys文件中去:
cat id_rsa_slave1.pub >> authorized_keys
cat id_rsa_slave2.pub >> authorized_keys
cat id_rsa_slave3.pub >> authorized_keys

master上用scp命令将authorized_keys文件拷贝到子节点的相应位置:
scp authorized_keys root@hj-0219:/root/.ssh/
scp authorized_keys root@lx-0215:/root/.ssh/
scp authorized_keys root@lx-0216:/root/.ssh/

在slave节点上查看有无该文件(我这里在slave1上查看了一下)

3.测试配置是否成功
在master上面能够通过ssh远程登录就可以了:(以master连接slave1为例)
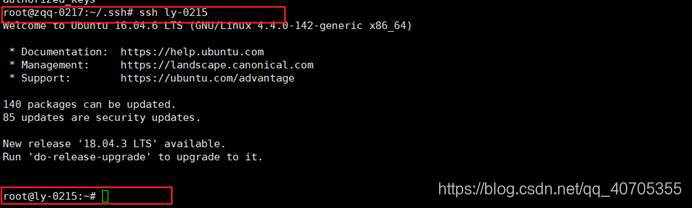
成功远程无密码登录就证明ssh免密访问做好了。
四、安装jdk
在master上解压jdk:
tar -zxvf jdk-8u191-linux-x64.tar.gz
配置环境变量:
vi /etc/profile
# jdk
export JAVA_HOME=/opt/data/jdk1.8.0_191
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
保存后使之生效:
source /etc/profile
测试:java -version
root@zqq-0217:/opt/data# java -version
java version "1.8.0_191"
Java(TM) SE Runtime Environment (build 1.8.0_191-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.191-b12, mixed mode)

四、安装与配置hadoop
1.安装jdk
解压jdk然后配置到/etc/profile中
# jdk
export JAVA_HOME=/opt/data/jdk1.8.0_191
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
2.安装Hadoop
在master上解压hadoop:
tar -zxvf hadoop-2.9.2.tar.gz
配置环境变量:
vi /etc/profile
# hadoop
export HADOOP_HOME=/opt/data/hadoop-2.9.2
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_YARN_HOME=$HADOOP_HOME
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
保存后使之生效:source /etc/profile
3.配置hadoop
需要配置的文件的位置为/opt/data/hadoop-2.9.2/etc/hadoop,需要修改的有以下几个文件:
hadoop-env.sh
yarn-env.sh
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
slaves
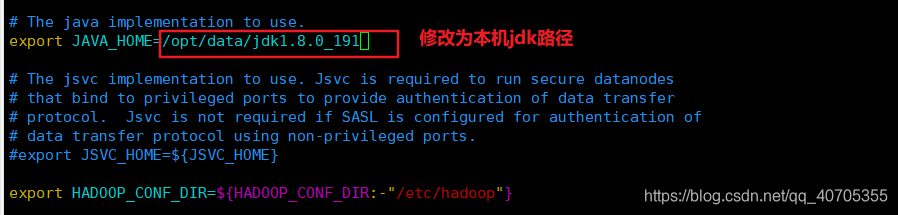
其中hadoop-env.sh和yarn-env.sh里面都要添加jdk的环境变量
1)、修改hadoop-env.sh
2)、修改yarn-env.sh

3)、修改core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://zqq0217:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property
</configuration>
4)、修改hdfs-site.xml
<configuration>
<property>
<name>dfs.http.address</name>
<value>zqq0217:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hj0219:50090</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/data/hadoop-2.9.2/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/data/hadoop-2.9.2/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.web.ugi</name>
<value>supergroup</value>
</property>
<!-- 配置隔离机制为ssh -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(/bin/true)</value>
</property>
</configuration>
5)、修改mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
6)、修改yarn-site.xml
<configuration>
<!-- 开启YARN HA -->
<!--rm失联后重新链接的时间-->
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>2000</value>
</property>
<!--开启resourcemanagerHA,默认为false-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--配置resourcemanager-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!--开启故障自动切换-->
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>zqq0217</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hj0219</value>
</property>
<!--开启自动恢复功能-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--配置与zookeeper的连接地址-->
<property>
<name>yarn.resourcemanager.zk-state-store.address</name>
<value>hj0219:2181,lx0216:2181,ly0215:2181</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hj0219:2181,lx0216:2181,ly0215:2181</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>appcluster-yarn</value>
</property>
<!--schelduler失联等待连接时间-->
<property>
<name>yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms</name>
<value>5000</value>
</property>
<!--配置rm1-->
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>zqq0217:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>zqq0217:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>zqq0217:8088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>zqq0217:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>zqq0217:8033</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm1</name>
<value>zqq0217:23142</value>
</property>
<!--配置rm2-->
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>hj0219:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>hj0219:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hj0219:8088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>hj0219:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>hj0219:8033</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm2</name>
<value>hj0219:23142</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
修改好之后将master的hadoop文件夹拷贝到每一个slave节点上
使用命令:
scp -r /opt/data/hadoop-2.9.2 root@hj0219:/opt/data/
scp -r /opt/data/hadoop-2.9.2 root@lx0216:/opt/data/
scp -r /opt/data/hadoop-2.9.2 root@ly0215:/opt/data/
修改slave节点的slaves文件为:
vi /opt/data/hadoop-2.9.2/etc/hadoop/slaves
# 修改文件内容为:
localhost
将master的/etc/profile文件发送到slave节点上
scp /etc/profile root@hj0219:/etc/
scp /etc/profile root@lx0216:/etc/
scp /etc/profile root@ly0215:/etc/
在每一个slave上执行:
source /etc/profile
在master上面执行:
start-all.sh
启动集群
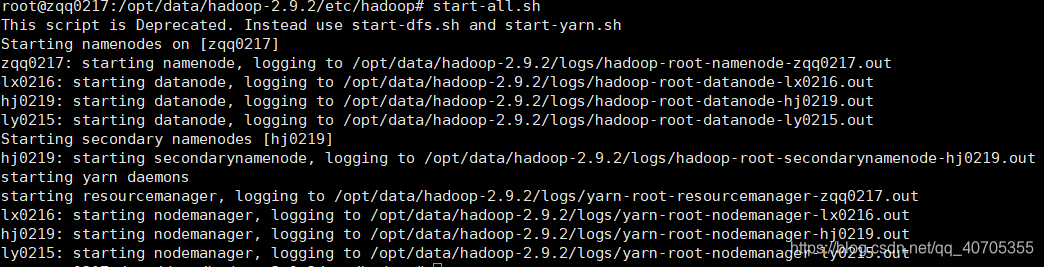
Master上jps

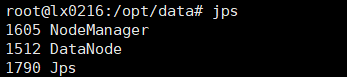
Slaves1上jps:
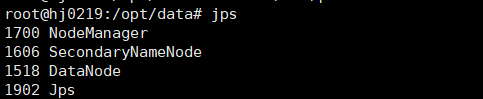
Slaves2和slaves3上jps:
五、安装Zookeeper
1.在master上解压zookeeper
tar -zxvf zookeeper-3.4.14.tar.gz
2.在conf目录下拷贝一份zoo_sample.cfg并且重命名为zoo.cfg
cp zoo_sample.cfg zoo.cfg
3.修改zoo.cfg(下面的内容是需要修改的)
dataDir=/opt/data/zookeeper-3.4.14/tmp #修改自己的目录,tmp文件夹需要自己新建
修改为自己的节点
server.1=hj0219:2888:3888
server.2=lx0216:2888:3888
server.3=ly0215:2888:3888
4.在tmp目录下新建myid的文件,并编辑写入1,保存退出
touch myid
vi myid
5.将zookeeper写入/etc/profile
#zookeeper
export ZOOKEEPER_HOME=/opt/data/zookeeper-3.4.14
export PATH=$ZOOKEEPER_HOME/bin:$PATH
6.将zookeeper拷贝到所有子节点
scp -r /opt/data/zookeeper-3.4.14 root@hj0219:/opt/data/
scp -r /opt/data/zookeeper-3.4.14 root@lx0216:/opt/data/
scp -r /opt/data/zookeeper-3.4.14 root@ly0215:/opt/data/
7.在slave节点内修改myid文件,slave1修改myid文件内容为1, slave2修改myid文件内容为2 , slave3修改myid文件内容为3.
8.在每一个子节点启动zookeeper,
root@lx0216:/opt/data# zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/data/zookeeper-3.4.14/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
9.查看zookeeper状态
# slave1
root@hj0219:/opt/data/zookeeper-3.4.14/tmp# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/data/zookeeper-3.4.14/bin/../conf/zoo.cfg
Mode: leader
# slave2
root@lx0216:/opt/data# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/data/zookeeper-3.4.14/bin/../conf/zoo.cfg
Mode: follower
# slave3
root@ly0215:/opt/data# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/data/zookeeper-3.4.14/bin/../conf/zoo.cfg
Mode: follower
10.jps可以看到每一个slave多了一个SecondaryNameNode进程,满足9和10就说明zookeeper配置启动好了
六、安装hbase
1.解压
2.修改hbase-env.sh
export JAVA_HOME= #你自己的jdk目录
export HBASE_MANAGES_ZK=false #取消注释,改为false
3.修改hbase-site.xml
<configuration>
<property >
<!--hbase存放数据目录-->
<name>hbase.rootdir</name>
<value>hdfs://mycluster/hbase</value>
</property>
<property>
<!--是否开启分布式存储-->
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<!--zookeeper集群-->
<name>hbase.zookeeper.quorum</name>
<value>hj0219,lc0216,ly0215</value>
</property>
</configuration>
4.修改regionservers
# 自己的子节点
hj0219
lx0216
ly0215
5.添加到/etc/profile
#hbase
export HBASE_HOME=/opt/data/hbase-1.2.6
export PATH=$HBASE_HOME/bin:$PATH
6.将hbase和profile文件拷贝到slave上
7.刷新profile
8.启动hbase(启动之前在source一次profile文件)
