1 环境准备
1.1 修改IP
1.2 修改主机名及主机名和IP地址的映射
1.3 关闭防火墙
1.4 ssh免密登录
1.5 安装JDK,配置环境变量
2 集群规划
| 节点名称 | NN | JJN | DN | ZKFC | ZK | RM | NM |
| linux1 | NameNode | JournalNode | DataNode | ZKFC | Zookeeper | NodeManager | |
| linux2 | NameNode | JournalNode | DataNode | ZKFC | ZooKeeper | ResourceManager | NodeManager |
| linux3 | JournalNode | DataNode | ZooKeeper | ResourceManager | NodeManager |
3 安装Zookeeper集群
安装详解参考 : zookeeper集群搭建
4 配置hadoop
4.1修改 core-site.xml
<configuration> <!-- meNode的地址组装成一个集群mycluster --> <property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property> <!-- 指定hadoop运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop/data/ha/tmp</value> </property> <!-- 指定ZKFC故障自动切换转移 --> <property> <name>ha.zookeeper.quorum</name> <value>linux1:2181,linux2:2181,linux3:2181</value> </property> </configuration>
4.2 修改hdfs-site.xml
<connfiguration> <!-- 设置dfs副本数,默认3个 --> <property> <name>dfs.replication</name> <value>2</value> </property> <!-- 完全分布式集群名称 --> <property> <name>dfs.nameservices</name> <value>mycluster</value> </property> <!-- 集群中NameNode节点都有哪些 --> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property> <!-- nn1的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>linux1:8020</value> </property> <!-- nn2的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>linux2:8020</value> </property> <!-- nn1的http通信地址 --> <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>linux1:50070</value> </property> <!-- nn2的http通信地址 --> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>linux2:50070</value> </property> <!-- nn2的http通信地址 --> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>linux2:50070</value> </property> <!-- 指定NameNode元数据在JournalNode上的存放位置 --> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://linux1:8485;linux2:8485;linux3:8485/mycluster</value> </property> <!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 --> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <!-- 使用隔离机制时需要ssh无秘钥登录--> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/hadoop/.ssh/id_rsa</value> </property> <!-- 声明journalnode服务器存储目录--> <property> <name>dfs.journalnode.edits.dir</name> <value>/opt/module/hadoop/data/ha/jn</value> </property> <!-- 关闭权限检查--> <property> <name>dfs.permissions.enable</name> <value>false</value> </property> <!-- 访问代理类:client,mycluster,active配置失败自动切换实现方式--> <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!-- 配置自动故障转移--> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> </configuration>
4.3 修改mapred-site.xml
[hadoop@linux1 hadoop]# mv mapred-site.xml.template mapred-site.xml [hadoop@linux1 hadoop]# vi mapred-site.xml <configuration> <!-- 指定mr框架为yarn方式 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- 指定mr历史服务器主机,端口 --> <property> <name>mapreduce.jobhistory.address</name> <value>linux1:10020</value> </property> <!-- 指定mr历史服务器WebUI主机,端口 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>linux1:19888</value> </property> <!-- 历史服务器的WEB UI上最多显示20000个历史的作业记录信息 --> <property> <name>mapreduce.jobhistory.joblist.cache.size</name> <value>20000</value> </property> <!--配置作业运行日志 --> <property> <name>mapreduce.jobhistory.done-dir</name> <value>${yarn.app.mapreduce.am.staging-dir}/history/done</value> </property> <property> <name>mapreduce.jobhistory.intermediate-done-dir</name> <value>${yarn.app.mapreduce.am.staging-dir}/history/done_intermediate</value> </property> <property> <name>yarn.app.mapreduce.am.staging-dir</name> <value>/tmp/hadoop-yarn/staging</value> </property> </configuration>
4.4 修改 slaves
linux1
linux2
linux3
4.5修改yarn-site.xml
[hadoop@linux2 hadoop]$ vi yarn-site.xml <configuration> <!-- reducer获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!--启用resourcemanager ha--> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <!--声明两台resourcemanager的地址--> <property> <name>yarn.resourcemanager.cluster-id</name> <value>rmCluster</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>linux2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>linux3</value> </property> <!--指定zookeeper集群的地址--> <property> <name>yarn.resourcemanager.zk-address</name> <value>linux1:2181,linux2:2181,linux3:2181</value> </property> <!--启用自动恢复--> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <!--指定resourcemanager的状态信息存储在zookeeper集群--> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> </configuration>
4.5 拷贝hadoop到其他节点
[hadoop@linux1 module]$ scp -r hadoop/ hadoop@linux2:/opt/module/
[hadoop@linux1 module]$ scp -r hadoop/ hadoop@linux3:/opt/module/
4.6 配置Hadoop环境变量
[hadoop@linux1 module]$ vim /etc/profile
export HADOOP_HOME=/opt/module/hadoop
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
生效
[hadoop@linux1 module]$ source /etc/profile
5 启动集群
1)在各个JournalNode节点上,输入以下命令启动journalnode服务:(前提zookeeper集群已启动)
[hadoop@linux1 hadoop]$ hadoop-daemon.sh start journalnode
[hadoop@linux2 hadoop]$ hadoop-daemon.sh start journalnode
[hadoop@linux3 hadoop]$ hadoop-daemon.sh start journalnode
cd /opt/module/hadoop/data
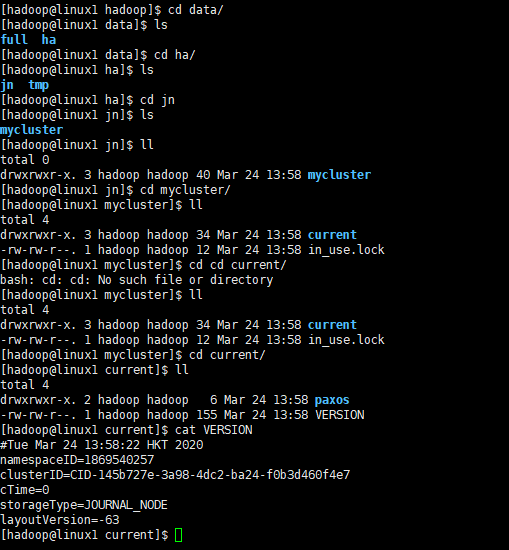
产生clusterID的集群编号
cd /opt/moudle/hadoop/data/ha
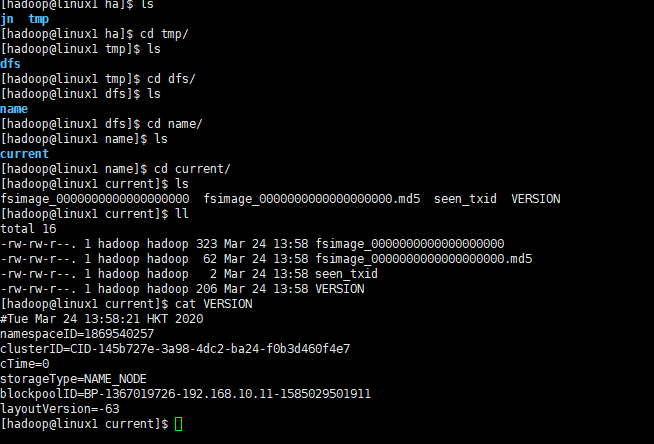
tmp目录也会产生clusterID集群编号
启动nn1上namenode
[hadoop@linux1 current]$ hadoop-daemon.sh start namenode
starting namenode, logging to /opt/module/hadoop/logs/hadoop-hadoop-namenode-linux1.out
[hadoop@linux1 current]$ jps
13040 NameNode
13121 Jps
5442 QuorumPeerMain
12403 JournalNode
3)在[nn2]上,同步nn1的元数据信息:
[hadoop@linux2 hadoop]$ hdfs namenode -bootstrapStandby
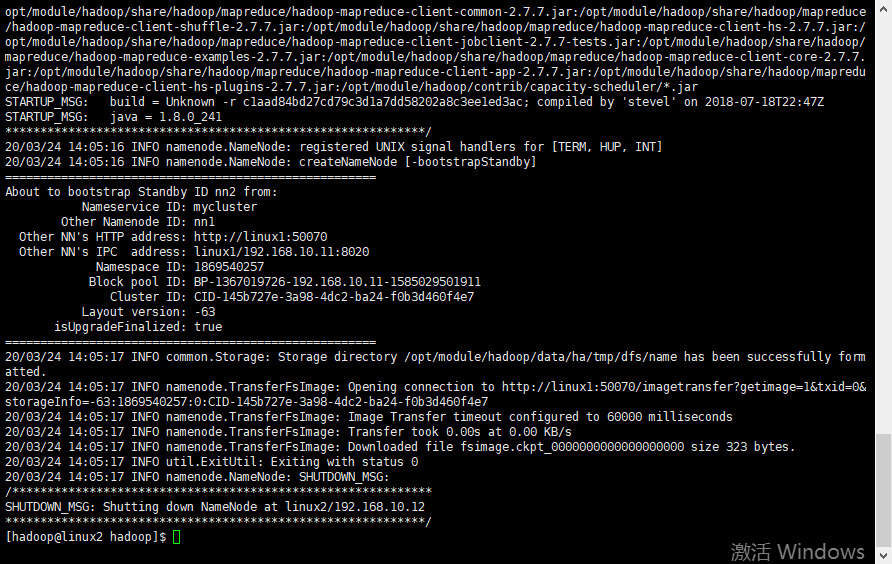
4)启动nn2上的namenode
[hadoop@linux2 hadoop]$ hadoop-daemon.sh start namenode starting namenode, logging to /opt/module/hadoop/logs/hadoop-hadoop-namenode-linux2.out [hadoop@linux2 hadoop]$ jps 2368 JournalNode 2498 NameNode 1783 QuorumPeerMain 2574 Jps [hadoop@linux2 hadoop]$
5)在[nn1]上,启动所有datanode
[hadoop@linux1 current]$ hadoop-daemons.sh start datanode linux1: starting datanode, logging to /opt/module/hadoop/logs/hadoop-hadoop-datanode-linux1.out linux2: starting datanode, logging to /opt/module/hadoop/logs/hadoop-hadoop-datanode-linux2.out linux3: starting datanode, logging to /opt/module/hadoop/logs/hadoop-hadoop-datanode-linux3.out [hadoop@linux1 current]$
访问地址:http://linux2:50070/dfshealth.html#tab-overview
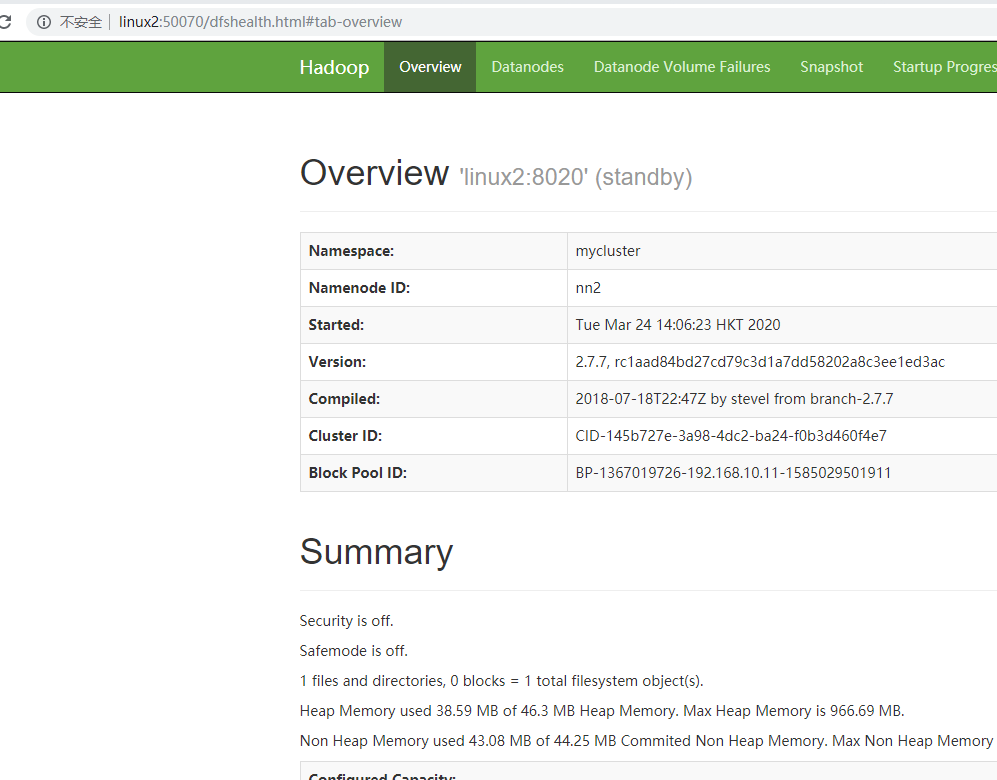
访问地址:http://linux1:50070/dfshealth.html#tab-overview

6)手动切换状态,在各个NameNode节点上启动DFSZK Failover Controller,先在哪台机器启动,哪个机器的NameNode就是Active NameNode
[hadoop@linux1 current]$ hadoop-daemon.sh start zkfc [hadoop@linux2 current]$ hadoop-daemon.sh start zkfc 设置第一个为active [hadoop@linux1 current]$ hdfs haadmin -transitionToActive nn1 --forcemanual
Web页面查看


7启动yarn
(1)在linux2中执行:
[hadoop@linux2 hadoop]$ start-yarn.sh
(2)在linux3中执行:
[hadoop@linux3 hadoop]$ yarn-daemon.sh start resourcemanager
(3)查看服务状态
[hadoop@linux3 hadoop]$ yarn rmadmin -getServiceState rm1 active [hadoop@linux3 hadoop]$ yarn rmadmin -getServiceState rm2 standby [hadoop@linux3 hadoop]$

测试集群
1.查看集群
[hadoop@linux1 opt]$ jps 13040 NameNode 5442 QuorumPeerMain 12403 JournalNode 15139 NodeManager 14908 DFSZKFailoverController 13390 DataNode 15711 Jps [hadoop@linux1 opt]$ [hadoop@linux2 hadoop]$ jps 2368 JournalNode 2498 NameNode 3746 Jps 1783 QuorumPeerMain 3271 NodeManager 2633 DataNode 3417 ResourceManager 3162 DFSZKFailoverController [hadoop@linux2 hadoop]$ [hadoop@linux3 hadoop]$ jps 2147 JournalNode 2515 NodeManager 1733 QuorumPeerMain 2249 DataNode 2719 ResourceManager 2847 Jps [hadoop@linux3 hadoop]$
创建文件夹
[root@linux3 ~]# mkdir -p /opt/wcinput root@linux3 ~]# cd /opt/ [root@linux3 opt]# chown hadoop:hadoop wcinput root@linux3 opt]# su hadoop [hadoop@linux3 opt]$ vi /opt/wcinput/my.txt
hello world
hello scals
hello java
hello php
hello world
php
放到hdfs中
[hadoop@linux3 opt]$ hadoop fs -put /opt/wcinput/my.txt /user/hadoop/input
执行单词统计
[hadoop@linux3 opt]$ hadoop jar /opt/module/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /user/hadoop/input /user/hadoop/output
查看输出
[hadoop@linux3 opt]$ hadoop dfs -ls /usr/hadoop/output
将输出下载到本地
[hadoop@linux3 hadoop]$ hadoop dfs -get /user/hadoop/output/part-r-00000
查看文件
[hadoop@linux3 hadoop]$ vim part-r-00000 hello 5 java 1 php 2 scals 1 world 2
四 Hadoop集群群启脚本
1启动服务
zookeeper hadoop
2脚本
1 编写启动集群脚本 vi start-cluster.sh
#!/bin/bash
echo "****************** 开始启动集群所有节点服务 ****************"
echo "****************** 正在启动zookeeper *********************"
for i in hadoop@linux1 hadoop@linux2 hadoop@linux3
do
ssh $i '/opt/module/apache-zookeeper-3.6.0/bin/zkServer.sh start'
done
echo "******************** 正在启动HDFS *******************"
ssh hadoop@linux1 '/opt/module/hadoop/sbin/start-dfs.sh'
echo "********************* 正在启动YARN ******************"
ssh hadoop@linux2 '/opt/module/hadoop/sbin/start-yarn.sh'
echo "*************** 正在node21上启动JobHistoryServer *********"
ssh hadoop@linux1 '/opt/module/hadoop/sbin/mr-jobhistory-daemon.sh start historyserver'
echo "****************** 集群启动成功 *******************"*
2 编写关闭集群脚本 vi stop-cluster.sh
#!/bin/bash echo "************* 开在关闭集群所有节点服务 *************" echo "************* 正在linux1上关闭JobHistoryServer *************" ssh hadoop@linux1 '/opt/module/hadoop/sbin/mr-jobhistory-daemon.sh stop historyserver' echo "************* 正在关闭YARN *************" ssh hadoop@linux2 '/opt/module/hadoop/sbin/stop-yarn.sh' echo "************* 正在关闭HDFS *************" ssh hadoop@linux1 '/opt/module/hadoop/sbin/stop-dfs.sh' echo "************* 正在关闭zookeeper *************" for i in hadoop@linux1 hadoop@linux2 hadoop@linux3 do ssh $i '/opt/module/apache-zookeeper-3.6.0/bin/zkServer.sh stop' done
[hadoop@linux1 hadoop]$ chmod +x start-cluster.sh