简言:工作需要第一次搭建分布式集群,第一次搭建完成后的总结记录。
系统环境:Ubuntu18.04
Java JDK:1.8.0_241
Zookeeper:3.5.6
Hadoop:2.10.0
HBase:1.3.6
虚拟机中三台服务器主机信息:
| 主机名 | IP |
| master | 192.168.0.166 |
| slave1 | 192.168.0.167 |
| slave2 | 192.168.0.168 |
准备
由于是从零开始搭建集群,所以需要做好一些前期准备工作——配置用户和用户组、配置主机名、安装配置SSH、配置免密登录SSH、关闭防火墙等。
配置单:
| 配置项 | master | slave1 | slave2 |
| 用户和用户组 | √ | √ | √ |
| 主机名 | √ | √ | √ |
| 安装SSH | √ | √ | √ |
| SSH免密登陆 | √ | √ | √ |
| 关闭防火墙 | √ | √ | √ |
配置用户和用户组
搭建hadoop集群环境要求所有主机的用户和用户组要完全一致。配置过程如下:
1.新建用户,建议用adduser命令。
sudo adduser hadoop
因为使用了sudo命令,所以要输入当前用户的密码才能进行下一步的操作。配置hadoop用户密码需要输入两次密码,然后一直按回车,最后输入Y确定。
2.在创建hadoop用户的同时也创建了hadoop用户组,下面把hadoop用户加入到hadoop用户组。
sudo usermod -a -G hadoop hadoop
3.前面一个hadoop是组名,后面一个hadoop是用户名。完成后输入一下命令查询结果。
cat /etc/group
4.然后再把hadoop用户赋予root权限,让他可以使用sudo命令。
sudo vi /etc/sudoers
修改文件如下:
# User privilege specification
root ALL=(ALL:ALL) ALL
hadoop ALL=(ALL:ALL) ALL # 添加这一行配置
保存退出,hadoop用户就拥有了root权限。
配置主机名
我们一开始就给出了3台主机的主机名(master、slave1、slave2),把虚拟机中三台主机名修改为对应名字。
1.编辑 /etc/hostname ,把里面的内容更改为你所需要的设定的主机名。
sudo vim /etc/hostname
2.更改hosts文件,修改(或增加)127.0.1.1后面的名称改为设定值。
sudo vim /etc/hosts
3.重启服务器,更改生效。
sudo reboot
4.验证。重新登录后,会发现主机名已经更改为设定值了。
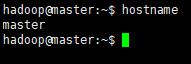
5.修改host文件,配置域名。编辑hosts文件:
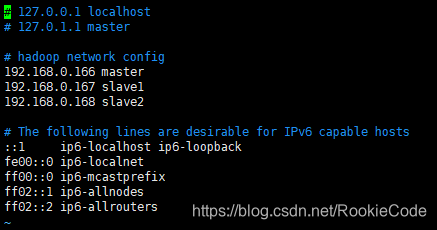
sudo vi /etc/hosts
添加下面内容:
192.168.0.166 master
192.168.0.167 slave1
192.168.0.168 slave2
注意:主机名和hosts文件中设置的名称应当保持一致,否则会产生意外的错误。
安装SSH
在Hadoop运行过程中,主从机之间是通过SSH进行通信的,所以需要对所有主机进行SSH的安装和配置工作。
1.先更新一下apt。
sudo apt-get update
2.接下来,安装SSH。
sudo apt-get install openssh-server
3.安装完成之后,使用下面的命令来查看SSH是否安装成功。
ps -e | grep ssh
安装好SSH之后,就可以使用SSH进行远程操作了。
配置免密登录SSH
主机间免密登录才能实现主机间的顺畅通信,因此该环节非常重要!
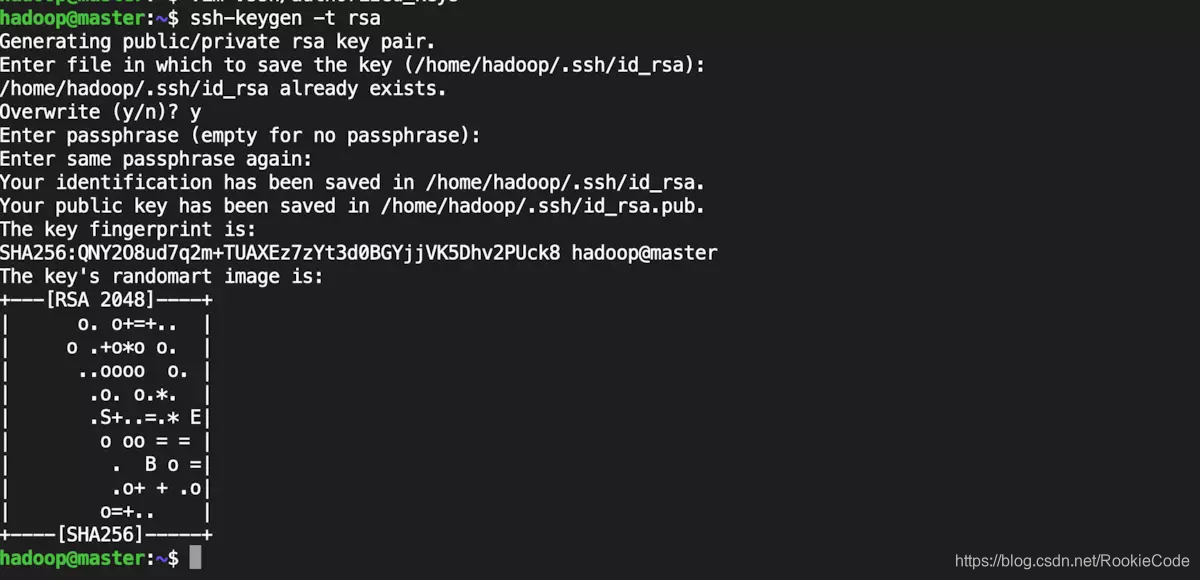
1.在master主机上生成密钥对。
ssh-keygen -t rsa
输入后一直回车选择默认即可。
2.将公钥(~/.ssh/id_rsa.pub中的内容)复制到文件authorized_keys中去。
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
3.分别在从机slave1,slave2上都进行同样的操作,同时将两个从机的公玥都复制奥主机master的~/.ssh/authorized_keys中去。
4.将master上的~/.ssh/authorized_keys通过scp命令复制到从机slave1,slave2中去。
scp -r ~/.ssh/authorized_keys slave1:~/.ssh/
scp -r ~/.ssh/authorized_keys slave2:~/.ssh/
或者,使用ssh-copy-id $IPs #$IPs为所有节点地址包括自身,按照提示输入yes 和root密码。
5.验证一下免密登录是否成功。在master上登录slave1、slave2(其他主机上验证方法也是一样的)。
ssh slave1
如果是第一次登录,则会要求输入密码,但之后登录都不再需要密码。
注意:最好将JDK,Hadoop,Zookeeper,HBase所在目录设置为hadoop用户所有,否者后续启动相关应用时会报错。
设置目录及目录下所有文件所属用户:
chown -R username dir
关闭防火墙
集群需要开放很多端口,因此,为了避免出现端口未开放的问题,我索性关闭了防火墙,如果不关闭防火墙,需要开放集群相关端口。我使用ufw命令关闭防火墙。
1.关闭防火墙
sudo ufw disable
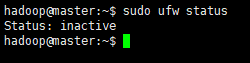
2.查看防火墙状态
sudo ufw status
正式搭建
接下来全部通过SSH远程配置。
配置单:
| 配置项 | master | slave1 | slave2 |
| Java JDK | √ | √ | √ |
| Zookeeper | √ | √ | √ |
| Hadoop | √ | √ | √ |
| HBase | √ | √ | √ |
Java JDK
Hadoop的有些计算是通过jar包进行分布式计算的。因此,安装Hadoop前需要安装JDK。
1.下载Java JDK。
2.将JDK下载到本地后,通过scp命令将安装包发送到每个主机上。
scp jdk-8u241-linux-x64.tar.gz hadoop@192.168.0.166:~/
3.登录master主机
ssh hadoop@192.168.0.166
4.在 /usr/local/ 中建 cluster文件夹。
mkdir /usr/local/cluster
5.进入服务器根目录下,将jdk-8u241-linux-x64.tar.gz解压至 /usr/local/cluster中。
tar -zxvf ~/jdk-8u241-linux-x64.tar.gz -C /usr/local/cluster/
6.进入 /usr/local/cluster 中,为了方便日后版本的更新,这里使用软链接的方法。
cd /usr/local/cluster
ln -s jdk1.8.0_241 java
7.进行环境变量的配置。
sudo vi ~/.bashrc
添加如下内容:
# java
export JAVA_HOME=/usr/local/cluster/java
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
8.使环境变量立刻生效。
source ~/.bashrc
9.验证环境变量是否配置成功。
java -version
如果输出如下图所示,即代表JDK环境变量配置好了。

Zookeeper
1.下载Zookeeper。
2.将Zookeeper下载到本地后,通过scp命令将安装包发送到master主机上。下面以master为例介绍安装配置,其他的主机安装和配置是完全一样的。
scp zookeeper-3.5.6-bin.tar.gz hadoop@192.168.0.166:~/
3.进入服务器根目录下,将zookeeper-3.5.6-bin.tar.gz解压至 /usr/local/cluster中。
tar -zxvf ~/zookeeper-3.5.6-bin.tar.gz -C /usr/local/cluster/
4.进入 /usr/local/cluster 中,为了方便日后版本的更新,这里使用软链接的方法。
cd /usr/local/cluster
ln -s zookeeper-3.4.12 zookeeper
5.设置环境变量,在 ~/.bashrc 添加如下内容。
#zookeeper
export ZOOKEEPER=/usr/local/cluster/zookeeper
export PATH=$PATH:$ZOOKEEPER/bin
6.使环境变量立刻生效。
source ~/.bashrc
7.配置zookeeper
**·**建立数据和日志文件
mkdir /usr/local/cluster/zookeeper/data
mkdir /usr/local/cluster/zookeeper/logs
**·**进入conf目录创建并修改zoo.cfg文件
cp zoo_sample.cfg zoo.cfg
修改后的内容为:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/usr/local/cluster/zookeeper/data
dataLogDir=/usr/local/cluster/zookeeper/logs
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.0=192.168.0.166:2888:3888
server.1=192.168.0.167:2888:3888
server.2=192.168.0.168:2888:3888
这里还需要在数据目录 /usr/local/cluster/zookeeper/data下新建名为myid的文件,各个主机对应的内容是不同的,master的内容是0,slave1的内容是1,slave2的内容是2,分别对应server.x中的x。server.A=B:C:D,其中A是一个数字, 表示这是第几号server。B是该server所在的IP地址。C配置该server和集群中的leader交换消息所使用的端口。D配置选举leader时所使用的端口。
8.使用scp命令,将配置好的Zookeeper发送到其他从节点上去。
scp -r /usr/local/cluster/zookeeper/ slave1:/usr/local/cluster/
scp -r /usr/local/cluster/zookeeper/ slave2:/usr/local/cluster/
注意:*如果操作的目录不属于hadoop需要sudo权限。
*节点上的myid要改成对应的值!
9.启动zookeeper。
在各个节点执行以下命令:
/usr/local/cluster/zookeeper/bin/zkServer.sh start
正常启动:

注意:zookeeper启动时报:Zookeeper JAVA_HOME is not set and java could not be found in PATH
解决方法:进入Zookeeper的bin目录下,修改zkEnv.sh文件,添加如下内容:
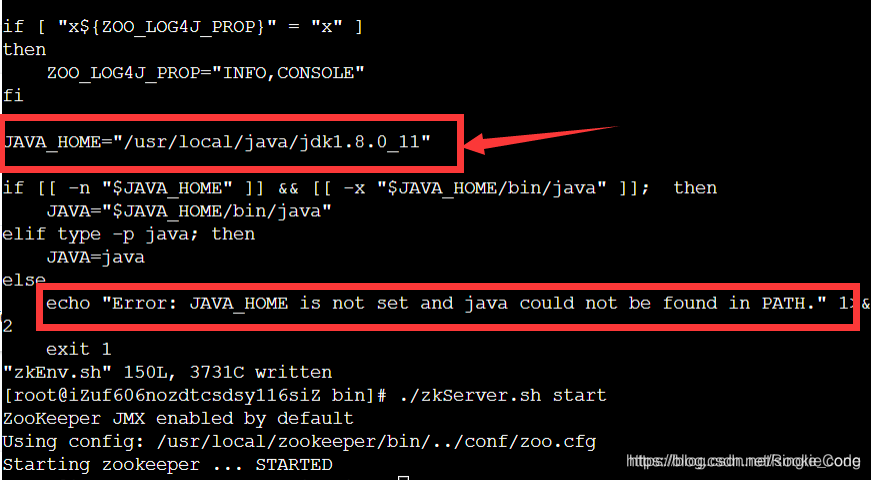
退出保存,启动zookeeper即可。
10.查看各个主机的状态。
/usr/local/cluster/zookeeper/bin/zkServer.sh status

注意:zookeeper的版本有一个坑,从3.5.5开始,带有bin名称的包才是我们想要的下载可以直接使用的里面有编译后的二进制的包,而之前的普通的tar.gz的包里面是只是源码的包无法直接使用,会报:找不到或无法加载主类 org.apache.zookeeper.server.quorum.QuorumPeerMain。
Hadoop
1.下载Hadoop。
2.将Hadoop下载到本地后,通过scp命令将安装包发送到master上。
scp hadoop-2.10.0.tar.gz hadoop@192.168.0.166:~/
3.进入服务器根目录下,将hadoop-2.10.0.tar.gz解压至 /usr/local/cluster中。
tar -zxvf ~/hadoop-2.10.0.tar.gz -C /usr/local/cluster/
4.进入 /usr/local/cluster 中,为了方便日后版本的更新,这里使用软链接的方法。
cd /usr/local/cluster
ln -s hadoop-2.10.0 hadoop
注意:此处有一个坑,后面会讲!
5.设置环境变量,在 ~/.bashrc 添加如下内容。
# hadoop
export HADOOP_HOME=/usr/local/cluster/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
6.使环境变量立刻生效。
source ~/.bashrc
7.验证Hadoop是否安装成功。
hadoop version
如果输出hadoop版本信息即安装成功。
8.配置hadoop。
**·**进入hadoop的配置目录。
cd /usr/local/cluster/hadoop/etc/hadoop/
**·**新建几个文件夹,配置文件中需要用到。
mkdir tmp
mkdir hdfs
mkdir hdfs/name
mkdir hdfs/data
**·**需要修改的配置文件为:core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml、slaves、hadoop-env.sh、yarn-env.sh。将如下configuration的内容复制到对应的配置文件中即可。
**·**hadoop-env.sh 和 yarn-env.sh增加下面一行命令,即配置java环境。
export JAVA_HOME=/usr/local/cluster/java
**·**core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/cluster/hadoop/tmp</value>
</property>
</configuration>
**·**hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/cluster/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/cluster/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.http.address</name>
<value>master:50070</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
**·**yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
**·**mapred-site.xml
通过cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml创建etc/hadoop/mapred-site.xml,内容改为如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
**·**slaves
slave1
slave2
**·**配置文件修改完以后,将master下hadoop文件夹复制到slave1和slave2中。
scp -r /usr/local/cluster/hadoop/ slave1:/usr/local/cluster/
scp -r /usr/local/cluster/hadoop/ slave2:/usr/local/cluster/
9.运行Hadoop。注意:启动hadoop的命令都只在master上执行。
**·**启动namenode,如果是第一次启动namenode,需要对namenode进行格式化。命令如下:
/usr/local/cluster/hadoop/bin/hdfs namenode -format
**·**启动hdfs:
/usr/local/cluster/hadoop/sbin/start-dfs.sh
注意:如果启动hdfs时报异常,找不到 **/hadoop-2.10.0/目录,这就是之前说的坑,复制过去的时软链接目录hadoop,启动时slave1,slave2启动的hadoop-2.10.0目录下的文件,所以这里需要复制原目录,不要复制软链接目录。如果正常就忽略!
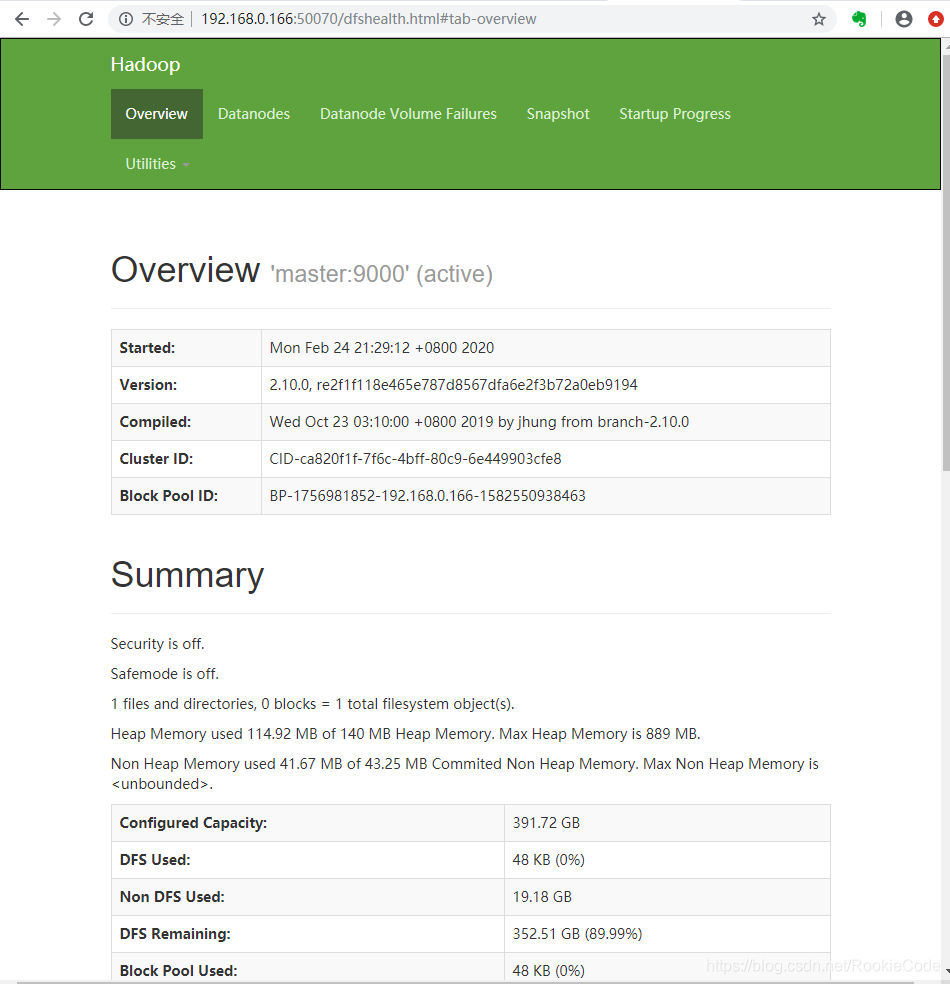
**·**验证hdfs是否启动成功。
访问:http://192.168.0.166:50070/dfshealth.html#tab-overview,如图:
**·**启动yarn
/usr/local/cluster/hadoop/sbin/start-yarn.sh
成功启动后会打印成功信息。
HBase
1.下载HBase。
2.将HBase下载到本地后,通过scp命令将安装包发送到master主机上。
scp hbase-1.3.6-bin.tar.gz hadoop@192.168.0.166:~/
3.进入服务器根目录下,将hbase-1.3.6-bin.tar.gz解压至 /usr/local/cluster中。
tar -zxvf ~/hbase-1.3.6-bin.tar.gz -C /usr/local/cluster/
4.进入 /usr/local/cluster 中,为了方便日后版本的更新,这里使用软链接的方法。
cd /usr/local/cluster
ln -s hbase-1.3.6 hbase
5.设置环境变量,在 ~/.bashrc 添加如下内容。
# hbase
export HBASE_HOME=/usr/local/cluster/hbase
export PATH=$PATH:$HBASE_HOME/bin
6.使环境变量立刻生效。
source ~/.bashrc
7.验证Hbase是否安装成功。
hbase version
如果输出hadoop版本信息即安装成功。
8.配置HBase
主要修改conf目录下的三个文件:hbase-env.sh、hbase-site.xml、regionservers。
**·**hbase-env.sh
export JAVA_HOME=/usr/local/cluster/java
export HBASE_CLASSPATH=/usr/local/cluster/hbase/lib
export HBASE_PID_DIR=/usr/local/cluster/hbase/data
export HBASE_LOG_DIR=/usr/local/cluster/hbase/logs
export HBASE_MANAGES_ZK=false
注意:要在hbase文件下,新建data和logs两个文件夹
mkdir /usr/local/cluster/hbase/data
mkdir /usr/local/cluster/hbase/logs
**·**hbase-site.xml
<configuration>
<property>
<name>hbase.tmp.dir</name>
<value>/usr/local/cluster/hbase/data</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,slave1,slave2</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/cluster/zookeeper/data</value>
<description>property from zoo.cfg,the directory where the snapshot is stored</description>
</property>
</configuration>
**·**regionservers
master
slave1
slave2
9.启动hbase
/usr/local/cluster/hbase/bin/start-hbase.sh
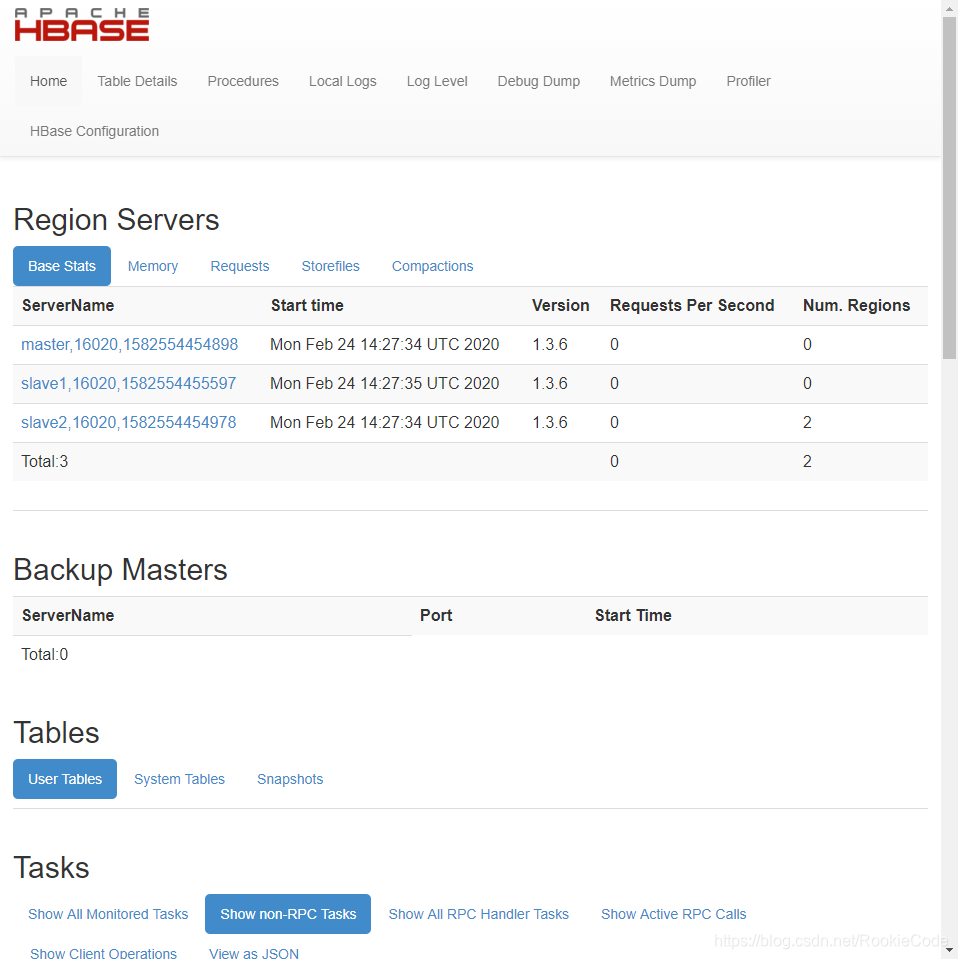
10.验证hbase是否启动成功。
访问:http://192.168.0.166:16010/master-status,如图。
注释:Hbase启动警告:Java HotSpot™ 64-Bit Server VM warning: ignoring option PermSize=128m; …
网上提供的解决方法:注释$HBASE_HOME/conf/hbase-env.sh 文件中的两行配置
# Configure PermSize. Only needed in JDK7. You can safely remove it for JDK8+
export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m"
export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m"
结果,我注释了,警告并没有消除,不影响运行,暂时没有处理!
总结
到此配置完成,记录了搭建过程中遇到的问题,仅作记录。
因为国内被墙的原因,很多镜像文件等下载很慢或者根本下载不了,
推荐按一个国内的镜像网站,下载比较快!
https://mirrors.tuna.tsinghua.edu.cn/apache/