论文:S3FD: Single Shot Scale-invariant Face Detector
论文链接:https://arxiv.org/abs/1708.05237
代码链接:https://github.com/sfzhang15/SFD
人脸检测领域目前主要的难点是小尺寸人脸、模糊人脸、遮挡人脸的检测,这篇ICCV2017关于人脸检测的文章正是为了解决小尺寸人脸难以检测的问题。这篇文章的出发点是:当人脸尺寸比较小时,基于anchor的人脸检测算法效果下降明显,因此提出了不受人脸尺度变化影响的S3FD算法。该算法整体上可以看做是基于SSD算法的改进,主要内容包括:1、改进检测网络和设置更加合理的anchor,改进检测网络主要是增加stride=4的预测层,anchor尺寸的设置参考有效感受野,另外不同预测层的anchor间隔采用等比例设置。2、引入尺度补偿的anchor匹配策略增加正样本anchor的数量,从而提高人脸的召回。3、引入max-out background label降低误检。
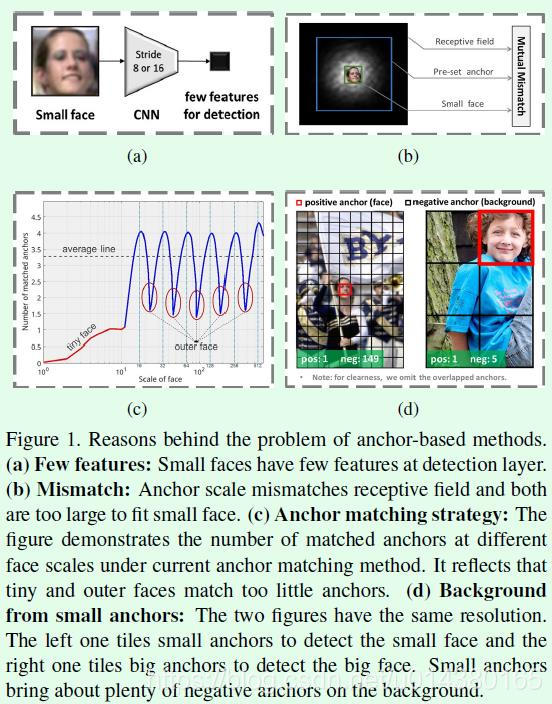
既然都知道小尺寸人脸不好检测,那么原因到底是什么呢?Figure1给出了作者对基于anchor的人脸检测算法在小人脸检测中效果下降明显的原因分析。
(a)中展示的是网络结构本身的设计问题。我们知道在SSD算法中有多个特征层用于检测目标,这些特征层中stride最小的是8,这样原图中8*8大小的区域在该预测层中就仅有1个像素点,这对于小人脸的检测是非常不利的,因为有效的特征太少了。同样,在Faster RCNN算法中,用于检测目标的特征层的stride是16,用于小人脸检测的有效特征区域更小了。
(b)中展示的是anchor尺寸、感受野和人脸尺寸不匹配的问题。从图中可以看出anchor尺寸和感受野大小不是很匹配,同时这两个都远大于小人脸。
(c)中因为一般设置的anchor尺寸都是离散的,比如[16,32,64,128,256,512],但是人脸的尺寸是连续的,因此当人脸尺寸在设定的anchor值之间时能够用于检测的anchor数量就很少,如图中红色圆圈表示,这样就容易导致人脸检测的召回率降低。
(d)为了提高小人脸的检测召回,很多检测算法都会通过设置较多的小尺寸anchor实现,这样容易导致较多的小尺寸负样本anchor,最终导致误检率的上升。例如(d)中两张图的分辨率一样,左边图中人脸区域较小,因此主要通过浅层特征进行检测,此时anchor尺寸设置较小;右图中人脸区域较大,因此主要是通过高层特征进行检测,此时anchor尺寸设置较大。可以看出左图中标签为背景的anchor数量远远多于标签为目标的anchor,而在右图中这种现象相对好一些。
文章整体上就是针对Figure1中提到的几个问题进行分析和提出解决方案,接下来依次来看看吧。
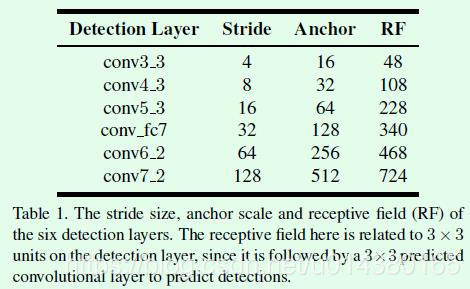
首先针对Figure1(a)(b)的问题,作者对检测网络的设计和anchor设计做了改进,提出了不受人脸尺寸影响的检测网络(scale-equitable face detection framework),主要内容包括:1、预测层的最小stride降低到4(具体而言预测层的stride范围为4到128,一共6个预测层),这样就保证了小人脸在浅层进行检测时能够有足够的特征信息。这部分在文章的附录中也给出了具体的对比实验,从实验结果来看增加这一个预测层对最终的实验结果提升还是非常明显的 。2、anchor的尺寸根据每个预测层的有效感受野和等比例间隔原理进行设置,设置为16到512,这样的话前者保证了每个预测层的anchor尺寸和有效感受野大小匹配,后者保证了不同预测层的anchor在输入图像中的密度基本类似。
检测网络的第一个改进,也就是增加stride=4的预测层比较容易理解,第二个改进,也就是关于anchor尺寸的设置可以看Figure3,Figure3是关于anchor尺寸和数量设置的依据介绍。
(a)中展示了有效感受野(effective receptive field)和理论感受野(theoretical receptive field)的区别,其中整个(a)代表的就是理论感受野,一般都是矩形,而(a)中的白色点状区域就是有效感受野。
(b)中以预测层conv3_3(stride=4)为例介绍理论感受野、有效感受野和anchor尺寸的关系,首先黑色点组成的方形框是理论感受野,对于conv3_3预测层而言是4848,有效感受野是蓝色点组成的圆形框是有效感受野,红色实线组成的方形框是该预测层设置的anchor,尺寸是1616,可以看到anchor尺寸和有效感受野是匹配的。
(c)是关于anchor的等比例间隔设置。假设n是anchor的尺寸,那么将anchor的间隔设置为n/4,从Table1可以看出n/4其实也是stride。举个例子,对于stride=4的conv3_3预测层而言,anchor尺寸设置为1616,那么相当于在输入图像中每隔4个像素点就有一个1616大小的anchor。可以看出这部分和SSD中关于anchor尺寸的设置是类似的,只不过相同stride层的anchor数量要比SSD少,因为这里设置的anchor宽高对比度是1:1,因为人脸的话一般都是正方形的,而在SSD中除了1:1以外,还有1:2,2:1等。

Table1是关于预测层的stride、anchor尺寸和感受野(RF)之间的关系。S3FD的anchor尺寸设置和SSD最主要的差别就在于S3FD中的anchor大小是和stride相关的,而SSD中anchor大小不仅和stride相关,还和输入大小相关。
然后针对Figure1(c)的问题,作者提出了尺度补偿的anchor匹配策略(scale compensation anchor matching strategy)。这部分主要分两步,第一步还是和常规确定anchor的正负标签类似,只不过将IOU阈值从0.5降到0.35,也就是和ground truth的IOU大于0.35的anchor为正样本,这样就先保证每个目标都能有足够的anhcor来检测,这样相当于间接解决了原本处于不同anchor尺寸之间的人脸的可用anchor数量少的问题。第一步之后,仍然会有较多的小人脸没有足够的正样本anchor来检测,因此第二步的目的就是提高小人脸的正样本anchor数量,具体而言是对所有和ground truth的IOU大于0.1的anchor做排序,选择前N个anchor作为正样本,这个N是第一步的anchor数量均值。最后得到的anchor尺寸和人脸尺寸的匹配数量曲线是Figure4(a),与Figure1(c)相比有较大提升。显然降低IOU阈值能够提高人脸的召回率,但同时也会带来一定的误检,之所以依然采用这种方式,个人觉得是召回率的增加远大于误检,而且后面还有相应的减少误检的操作,因此这种做法才保留。
Figure4是关于anchor和人脸匹配数量及max-out background label的示意图。
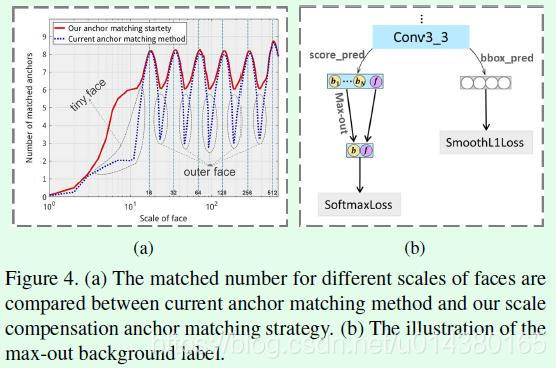
最后针对Figure1(d)的问题,作者提出了针对stride=4的预测层(conv3_3)的max-out background label操作,从而减少误检。具体而言可以参照Figure4(b),左边支路时分类支路,右边支路时回归支路。左边支路中一共预测Nm个背景概率和1个目标概率,选择Nm个背景概率中最高的概率作为最终的背景概率。这部分其实就相当于集成了Nm个分类器,有效削弱了负样本的预测概率,从而降低误检率,这种做法在目前数据不平衡的图像分类任务中也比较常用。
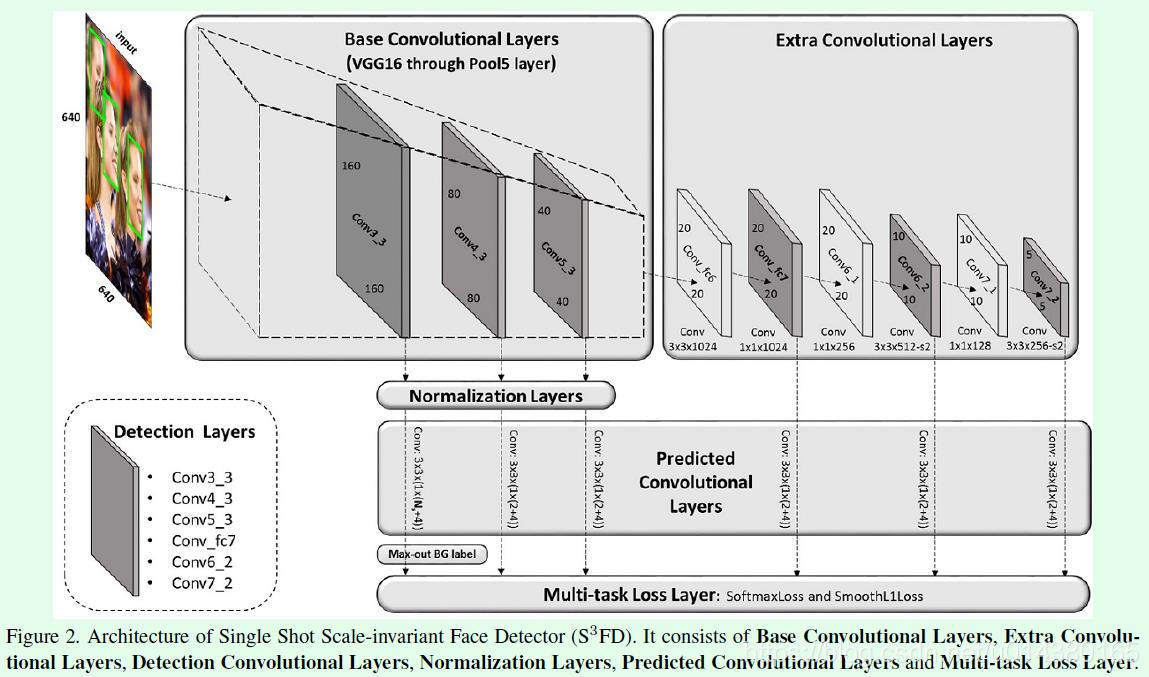
最终S3FD的网络结构如Figure2所示,其中基础网络(base convolutional layers)和添加层(extra convolutional layers)两部分和SSD的设计基本差不多,预测层(predicted convolutional layers)部分和SSD的区别在于一方面预测层整体前移了,也就是stride=4到stride=128共6个预测层,另一方面stride=4的预测层通道数和其他stride的预测层通道数不同,stride=4的预测层通道数是1*(Ns+4),其他stride的预测层通道数是1*(2+4),这里的2其实也可以用Ns表示,只不过不多其他stride的预测层而言Ns设置为2,表示1个前景(人脸)和1个背景(非人脸)共2个类别;而对于stride=4的预测层,Ns=Nm+1,其中1表示前景(人脸),Nm表示max-out background label数量。损失函数部分和常见的目标检测算法类似,分类采用基于softmax的交叉熵损失函数,回归采用smooth L1损失函数。
实验结果:
Table3是关于S3FD提出的优化点效果对比,baseline是Faster RCNN和SSD。S3FD(F)表示只改进检测网络和anchor设置,S3FD(F+S)表示改进检测网络、anchor设置和尺度补偿的anchor匹配策略,S3FD(F+S+M)是最终的算法。
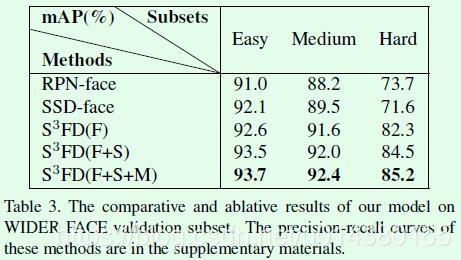
Figure8是S3FD和其他人脸检测算法在WIDER FACE数据集上的对比。
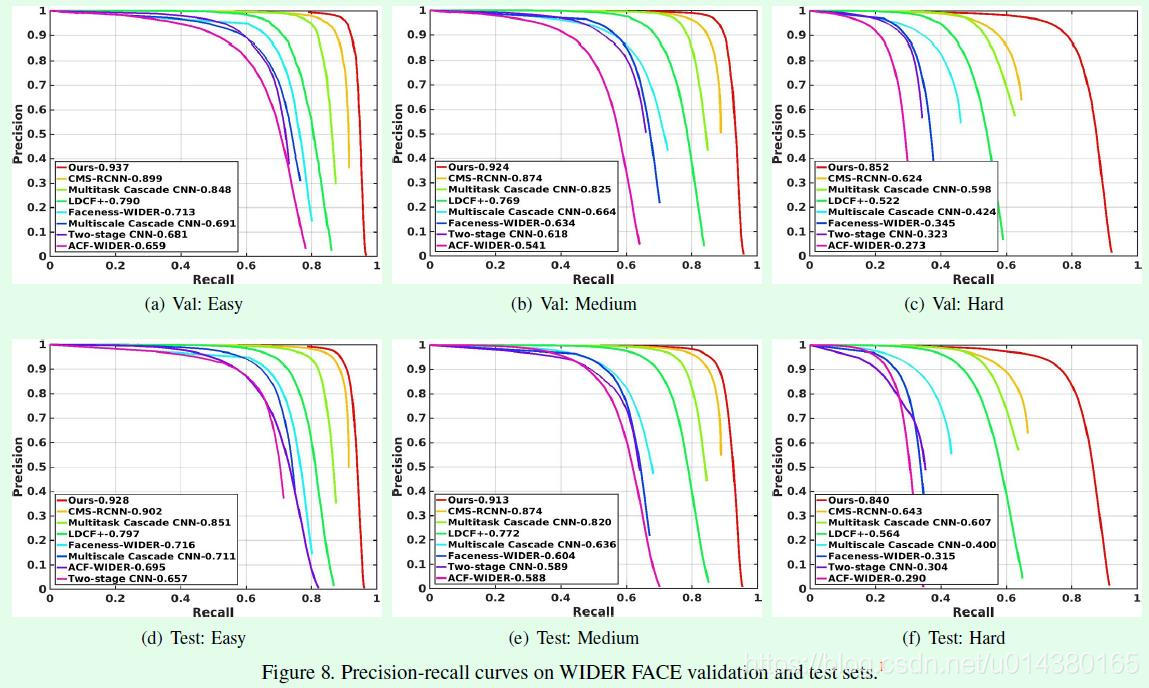
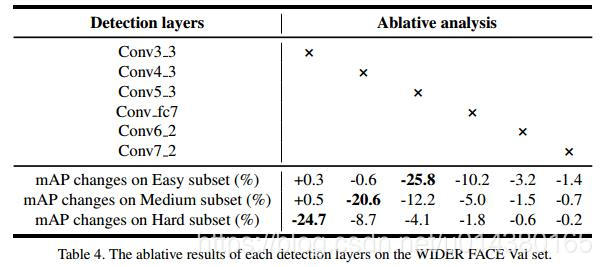
Table4是关于选择不同预测层对最终模型效果的影响,重点看下去掉conv3_3层的效果,因为这是S3FD算法在改进检测网络时做的非常重要的一个操作,可以看到去掉这个预测层对hard人脸的检测效果影响很大,这是因为hard部分主要是小尺寸人脸。