最近项目中在做人脸检测识别。现大致对人脸检测做一个总结归纳。
文章链接:《S3FD: Single Shot Scale-invariant Face Detector》
GITHUB :https://github.com/sfzhang15/SFD
This paper presents a real-time face detector, named Single Shot Scale-invariant Face Detector (S3FD), which performs superiorly on various scales of faces with a single deep neural network, especially for small faces。
Making contributions in the following three aspects:
1) proposing a scale-equitable face detection framework to handle different scales of faces well. We tile anchors on a wide range of layers to ensure that all scales of faces have enough features for detection. Besides, we design anchor scales based on the effective receptive field and a proposed equal proportion interval principle;
2) improving the recall rate of small faces by a scale compensation anchor matching strategy;
3) reducing the false positive rate of small faces via a max-out background label. As a consequence, our method achieves state-of-theart detection performance on all the common face detection benchmarks, including the AFW, PASCAL face, FDDB and WIDER FACE datasets, and can run at 36 FPS on a Nvidia Titan X (Pascal) for VGA-resolution images.
总而言之
这篇可以看作是对SSD的改进与完善,速度较慢(36FPS with Titan X & VGA)。
对小脸检测效果较好,例如下图:

在1000个人脸中找到了853张脸。
并且在其他数据集上的召回率比起其他算法也要好一些。
其他的人脸检测算法速度和性能比较可以参照另一篇文章:https://zhuanlan.zhihu.com/p/32702868
一、方法介绍
在近几年里,CNN网络在图像分类到目标检测都取得了显著的成功。这同样激励着人脸检测。
因此该文作者从目标检测的方法中,改进了anchor-based的通用检测框架并提出了新的人脸检测方法。
In this paper, inspired by the RPN in Faster RCNN and the multi-scale mechanism in SSD, we develop a state-ofthe-art face detector with real-time speed.
原来的anchor-based是存在问题的。
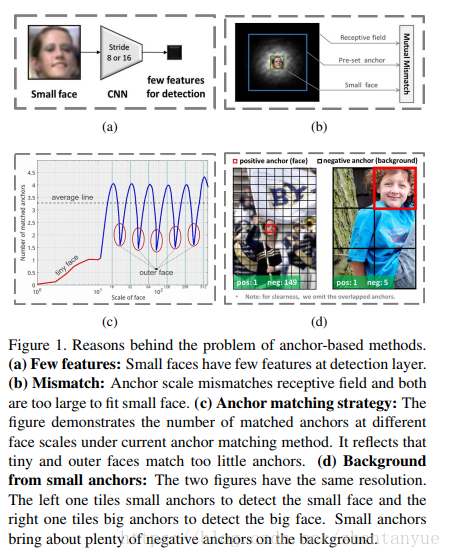
- (a) 由于卷积网络的池化层,小尺度人脸最后拥有的特征太少;
- (b) anchor的尺寸与感受野的尺寸互相不匹配,且都太大而不适宜小人脸;
- (c) 离散尺度的anchor预测连续尺度的人脸,导致tiny face和outer face均不能获得足够多的匹配;
- (d) 小的anchors在背景里进行匹配时会面临更多的负样本。
二、模型要点介绍
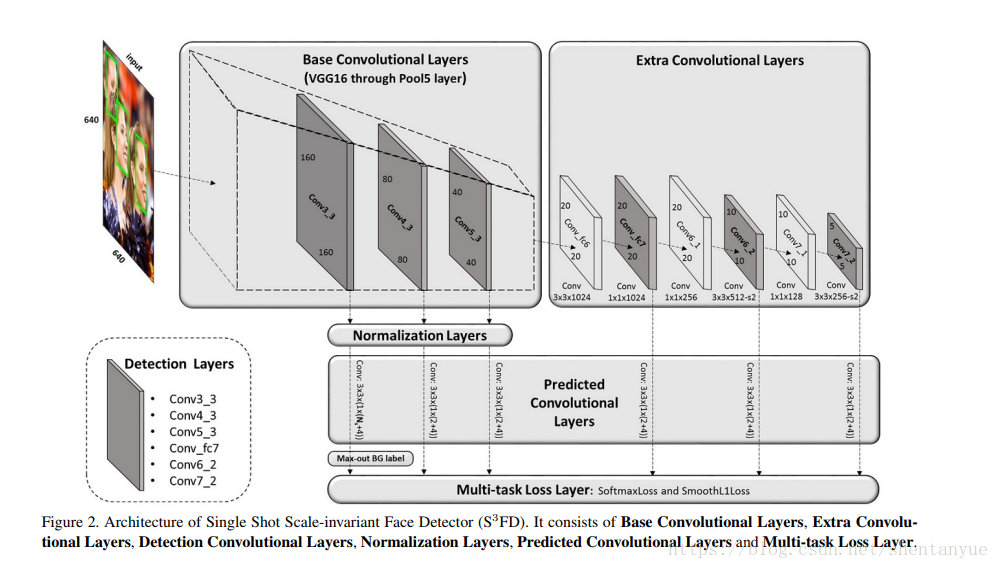
1.Scale-equitable framework
这个框架是基于anchor-based检测框架,例如RPN和SSD。作者为了提高面部尺度的鲁棒性,开发了一个网络架构,其中包括各种anchor-associated层。 论文中的anchor-associated 网络层的步长 从 4到 128 以2倍方式递增,这样可以保证不同尺度的人脸都有足够的信息用于人脸检测,anchor尺寸从16->512
网路结构(看上图)包括以下几个部分:
1)(Base Convolutional Layers)基础卷积层:我们保持了VGG16的从conv1_1到pool5的所有层,并去掉所有的其他网络层。
2)(Extra Convolutional Layers) 额外卷积层:我们通过对他们的参数进行二次采样,并将VGG16的fc6和fc7层转换成卷积层,然后在它们后面添加额外的卷积层。这些层可以逐渐减小尺寸并形成多尺度特征图。
3)(Detection Convolutional Layers)检测卷积层:我们选择了conv3_3,conv4_3,conv5_3,conv_fc7,conv6_2和conv7_2层作为检测层。
4)(Normalization Layers)正则化层:与其他检测层相比,conv3_3,con4_3,con5_3具有不同的特征尺度。因为我们使用L2正则化将它们的Norm分别调整到10,8,和5,然后在反向传播期间学习尺度。
5)(Predicted Convolutional Layers)预测卷积层:每个检测层之后都是一个p×3×3×q的卷积层,其中p和q是输入和输出的通道数字,3×3是卷积核大小。对于每一个anchor,我们预测 4个坐标位置补偿, N_s 个分类概率,其中 conv3_3 检测层是N_s = N_m + 1 ,其他检测层 N_s =2。
6)(Multi-task Loss Layer)多任务损失层:我们对分类用softmax loss,对于位置回归使用smooth L1 loss。
Designing scales for anchors.
对于6个检测层,我们使用不同尺度的Square anchor。
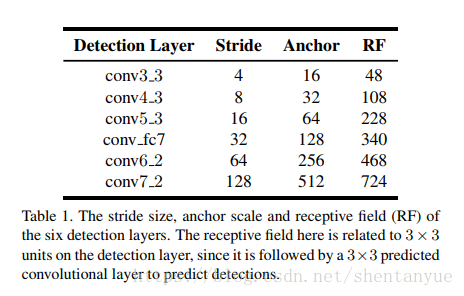
上表说表示的网络之所以这么设计,主要考虑了以下两个因素:
1.Anchor的尺度应该比receptive field(RF)小。
理论上的感受野是指该范围内的任意输入都会影响到输出。但实际上,这种影响不是均匀的。因此中间的输入对输出影响越重,类似于一种高斯分布。如下图所示。

我们应当使得anchor的尺度与有效receptive field相匹配,有效receptive field如上图b蓝色圈圈所示。其中黑色框为理论receptive field。
**不同size的anchor应当具有相同的空间密度。
如上图(c)所示,anchor的size与stride的比例始终保持为4。 这也就意味着,即使在不同尺度上,滑动过一定百分比(占anchor大小的百分比)的像素,得到的anchor的数量是一致的。
2.Scale compensation anchor matching strategy
如上图所示,平均匹配到的anchor数量约为3,太少;与anchor size差距较远的人脸匹配成功的数量尤其少(tiny face + outer face)。为了改善这种状况,主要采取了下列两种手段:
- (1)将原有的匹配阈值由0.5降到0.35,以此来增加更多的成功匹配。 (但该策略只能提高平均匹配数量,但不能改善tiny face和outer face。)
- (2)选出所有IOU大于0.1得到anchor并进行排序,从中选TOP N。(N为平均成功匹配数量。)
处理后的效果如下(a):

3.Max-out bckground label
下表是一张640x640图片上所能产生的不同size的anchor的数量,显然尺寸小的anchor占了绝大比例,这也是false positive的主要来源。
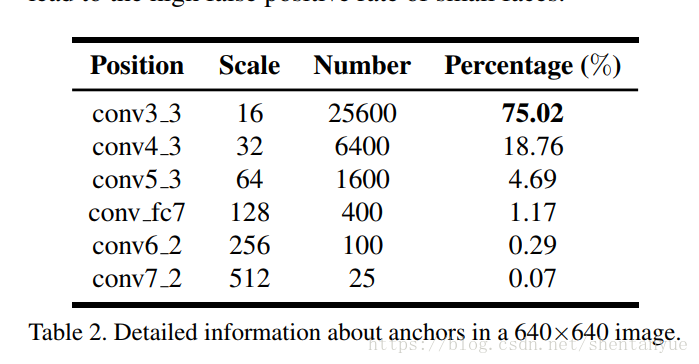
对于conv3_3,由于采用了小的anchor,导致太多的人脸虚警(False positive)
这里背景太过复杂,将其分类一类太笼统了,于是我们将背景细分为多类,人脸作为一类。这样复杂的背景就可以被正确分类的概率就提升了。
为了去除这些虚警,我们对每个最小anchors,我们将背景分为了N_m类,在计数每个位置类别时,我们得到N_m类个背景的概率,然后选择一个概率最大的分数作为最终分数用于计算softmax loss。



4.Conclusion
本文介绍了一种新型的人脸检测方法,是通过解决anchor-based检测方法的随着物体变小而性能急剧下降的问题。该文分析了这个问题的背后原因,并提出了一种scale-equitable框架,其中包含了各种anchor-associated层和一系列合理的anchor尺度,以便很好地处理不同人脸尺度。此外,该文还提出了尺度补偿anchor匹配策略,以提高小脸的召回率和最大背景标签以减小人脸的误报率。
实验表明,该文的三项贡献使S3FD在所有常见的人脸检测基准测试中都具有最先进的性能,特别是对小脸的检测。在他们未来的工作中,打算进一步改进背景patch的分类策略。他们认为明确将背景类划分为若干子类是值得进一步研究的。
后续再对S3FD算法实际测试和重新训练。----未完